What is Data Fabric? We Asked an Expert
Data Fabric is a new category of technology that helps businesses simplify data management and accelerate the delivery of app-centric technologies. Though data fabric solutions offer a number of unique features and capabilities, they are often confused with data virtualization tools. We spoke with Dan DeMers, the CEO at Data Fabric pioneer Cinchy, to gain more insight into the key capabilities that set Data Fabric technology apart.
Data Fabric technology is getting a lot of attention right now, but many people associate it with Data Virtualization or other data management software. How does Data Fabric software differ from other data management technologies?
The adoption of Data Fabric technology is growing rapidly but it’s fair to say that it is not yet widely understood. This fact has not been helped by vendors claiming to represent Data Fabric technology in order to capture website traffic when they are fundamentally different in design and function.
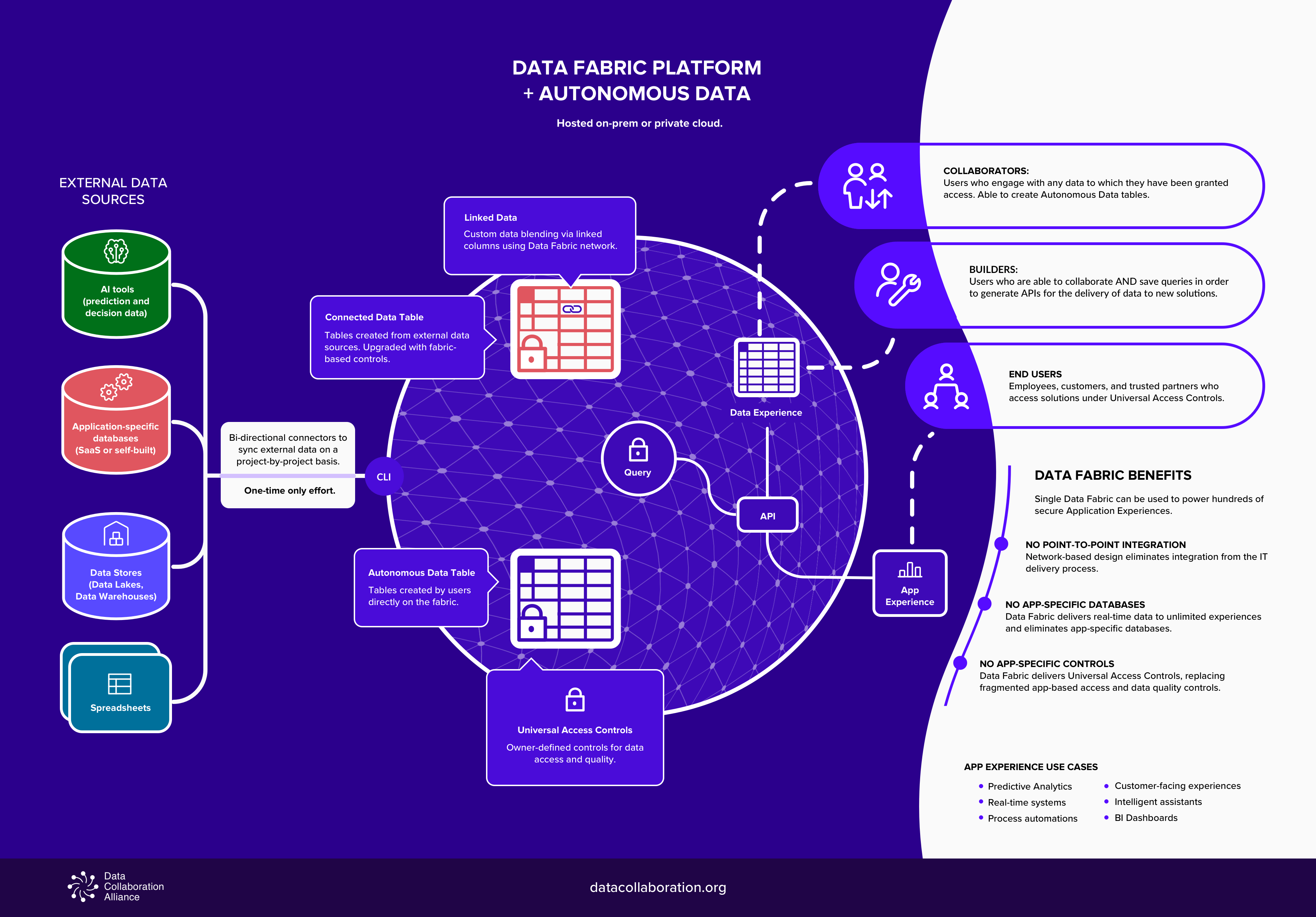
The key element that defines a Data Fabric is suggested by the word “fabric” itself. The term describes how this technology manages data as a logical network of structured datasets, and does not rely on the on-going exchange of copies between apps or data stores in order to provide a data integration function. This design is inspired by the structure of the brain which uses a physical network of axons and neurons to connect information and eliminate duplication. In Data Fabric technology, a logical, rather than physical network is applied but the outcome is the same – the elimination of point-to-point integration. The benefit is the creation of significant efficiencies within the IT delivery process.
Data Fabric platforms also support a much wider variety of use cases than Data Virtualization, Data Warehouses, or Data Lakes. Like those categories, a Data Fabric can be used for data governance, data mastering, and data analytics, however, a Data Fabric can also be used to deliver (aka “persist”) real-time operational data to hundreds of real-time systems, process automations, and customer experiences. This ability to provide an organization with a centralized system for the delivery of operational data to potentially hundreds of solutions is a key differentiator of Data Fabric solutions.
As a Data Fabric vendor, Cinchy has also introduced the concept of “autonomous data” (or “app-less” data) which is data that is created directly on the fabric itself.. In this way, any user can log into the fabric and become a “data owner” with the ability to protect and govern their datasets with universal controls (e.g. for data access, data privacy, and data quality). In this way, autonomous data is self-controlled, self-protected, and self-describing.
The significance of autonomous data is that centralized, data-level controls become embedded within hundreds of use cases for which the Data Fabric is the sole data source. This means that outcomes like data governance and data privacy become universal in nature. ther categories leave such controls to be managed on an application-by-application basis which is challenging (if not impossible) to synchronize or enforce.
Many Data Management tools create virtualized copies of business data, but data fabric connects original data sources. What unique options and controls does data fabric software provide for the data sources that are included in the fabric?
All datasets within a fabric, whether connected from an outside application or system (or in Cinchy’s case, created as autonomous data) are real-time operational data. This is not Data Virtualization where the illusion of a consolidated view is provided through a distributed query. That might be sufficient for analytics use cases, but not for supporting new transactional systems.
The network-based design of a Data Fabric allows datasets to be combined via linking (similar in principle to web links) rather than the exchange of copies and this eliminates the need to perform point-to-point (i.e. app-to-app) integration in the creation of custom datasets. This design also means that all data within a fabric can be controlled with unprecedented levels of granularity.
For example, data owners can set access controls for a single user or an entire group by granting permissions for viewing/editing/querying at the level of an entire data domain (e.g. marketingdata), a specific table, or even an individual cell of data. Controls can also be set dynamically by following a rules-based formula (e.g. users cannot view data from customers outside of their home country).
The key is that the access controls are centralized and applied universally across a copyless Data Fabric environment that’s capable of delivering data to hundreds of individual solutions such as process automations, browser-based experiences, predictive analytics, and real-time systems.
This highly-efficient approach stands in contrast to the challenge of maintaining such controls across hundreds or even thousands of individual apps and systems.
Many data management tools are best for specific use cases, what use cases are ideal for data fabric software, and what use cases aren’t appropriate? How should businesses use data fabric software to get the most out of it?
The use cases for a Data Fabric platform cover a wide range of data-centric business solutions from data governance, data mastering, and data analytics to building more efficient and secure versions of applications called “Application Experiences”
Because a Data Fabric hosts data within a network-based architecture and eliminates both stand-alone databases and point-to-point integration from the IT delivery process, they are the ideal platform when a new project faces high costs associated with traditional integration.
It’s also worth noting that a Data Fabric platform grows on a project-by-project basis. It’s not a case of “connect everything, then build” but rather each new project adds the data it needs in order to build the desired solution. The datasets this project team connects within the fabric can then be made instantly accessible to future project teams as well.
In this way, each Data Fabric project “pays it forward” to the next project which can be granted access to any dataset on the fabric with virtually no effort required. Solutions powered by a Data Fabric can therefore be built and deployed faster and faster over time, creating a “network effect” within the IT delivery process.
Data Fabric takes a “network-based” approach to data management. How does this differ from other solutions, such as data virtualization? What are the benefits of a network approach to data management?
The term “fabric” refers to the fact that this technology creates a logical network of datasets which function somewhat similarly to how the human brain interconnects information. Put simply rows and columns can be linked between different tables across the network of the fabric.
The network-based approach to integration is copyless whereas other technologies achieve integration by exchanging hundreds or thousands of copies of datasets either on a point-to-point basis or between apps and a central data store e.g. Data Lake, Data Warehouse.
The elimination of copies and traditional integration has significant implications for the protection, quality, and auditability quality of data as well as the speed and efficiency with which new enterprise-grade solutions can be built and deployed. Organizations using Data Fabric technology to build real-time solutions frequently experience 30-50% reductions in their time-to-market and IT resource consumption.
In terms of operations, how does a data fabric deliver its use cases? What’s the methodology and how is it different from agile, for example?
Traditionally, building a new business solution starts with the creation of a stand-alone database followed by months of integration and coding.
By contrast, a Data Fabric leverages its network-based architecture to eliminatethe new database and integration requirements and instead uses a simple query-builder interface to enable users to create sophisticated data models, with embedded control logic, that can be saved in order to generate an API. This API can then be connected to a table-based experience, a data visualization (either native to the fabric or external e.g. Tableau or PowerBI), or a rich HTML/Java-based user experience.
This data-centric delivery approach represents a simpler and more democratic way to develop technology and redefines the skills associated with the role of “technologist”. For example, an employee with a basic understanding of data modelling and SQL can produce sophisticated solutions, often in just days..
Crucially, the delivery process is protected by the Data Fabric’s powerful governance capabilities which ensure compliance with data privacy, data protection and other regulations. The principles of the agile methodology can be applied to a Data Fabric build, but the project elements and review process would be far simpler and more data-centric compared to a traditional project.
Data management tools often require businesses to create integrations to connect different sources of data. How does data fabric approach data integration? What are the benefits to this approach?
The network-based architecture of a Data Fabric allows users to create new data blends, data models, and queries by hyperlinking rows and columns across the fabric. These links replace the need to make copies, a capability that is unique to Data Fabric technology.
The first major benefit of this approach to integration is efficiency. By eliminating the process of traditional integration (based on copies) a project can be delivered anywhere from 30-50% by using a Data Fabric.
The second major benefit is control.
An organization using a Data Fabric as its primary data management environment (rather than databases, API networks, Data Virtualization, Data Warehouses, Data Lakes, or spreadsheets) can give its users the ability to manage a single set of controls without worrying that they will drift, dilute, or beerased as a result of the integration process..
This ability to give data owners an extremely high degree of control over operational data is considered a key benefit of a Data Fabric platform.
One concern many businesses have with data management tools is data protection and privacy. How does data fabric software protect business data, how does this differ from how data virtualization tools handle data protection and privacy?
A Data Fabric is used not only by IT and Data Science employees but all teams within an organization. Everyone can become a “data owner” meaning they have either been responsible for connecting an external data source (SaaS app, databases, spreadsheet etc), or (in the case of Cinchy) they have created an autonomous data table directly on the fabric.
Either way, as a data owner, they are able to control what users and groups can view, edit, or query their data.. Not only are these controls incredibly granular and adjustable right down to a single cell of data but they also exist within the fabric’s copyless, network-based architecture so they are universally-enforced.
When a Data Fabric is used to deliver (aka “persist”) data for a new solution, such as an analytics dashboard, real-time system, or automation, the access controls are baked-in to the new solution (aka Application Experience). In short, there’s no escaping these owner-defined controls because they are embedded at the data layer.
Other data management solutions (such as point-to-point API networks, Data Warehouses, and Data Virtualization) rely on the “traditional” approach to integration, meaning that they produce hundreds or even thousands of copies of data in order to function – copies which become increasingly difficult, if not impossible, to control, track, and protect.
Many businesses have users that require different permissions or who need only view data from specific sources. How does data fabric software handle user management?
The users of a Data Fabric platform can be divided into two main groups. First there are “collaborators” who add, edit, and query data and working alongside them are “builders” who have the same permissions but can generate APIs to power a new solution. Either type of user can also be a data owner, meaning that the control for a given dataset is theirs.
Beyond these roles, it is really the access controls set by data owners on specific datasets that defines the end user experience within a Data Fabric platform.
Are you Interested in Data Fabric Software?
Data Fabric software is quickly growing as more and more businesses become aware of the benefits of the technology. If you think data fabric software might be right for your business, consider reading what verified reviewers have to say on TrustRadius. If your business already uses a data fabric solution, consider providing your insights for prospective buyers to read.
Meet the Expert
Dan DeMers is the CEO of Cinchy, the Autonomous Data Fabric platform that combines a data-as-a-network architecture with unique Autonomous Data capabilities. (As Dan explained to us, this powerful combination eliminates on-going integration from the IT delivery process while giving data owners the ability to set universal controls for data quality and protection.) Cinchy is used by global banks, telcos, public sector agencies, and healthcare providers to enable every employee to collaborate securely on real-time data and accelerate hundreds of analytics, process automation, and customer experience projects.
Was this helpful?
