Nagios provides monitoring of all mission-critical infrastructure components. Multiple APIs and community-build add-ons enable integration and monitoring with in-house and third-party applications for optimized scaling.
N/A
Splunk Infrastructure Monitoring
Score 8.7 out of 10
N/A
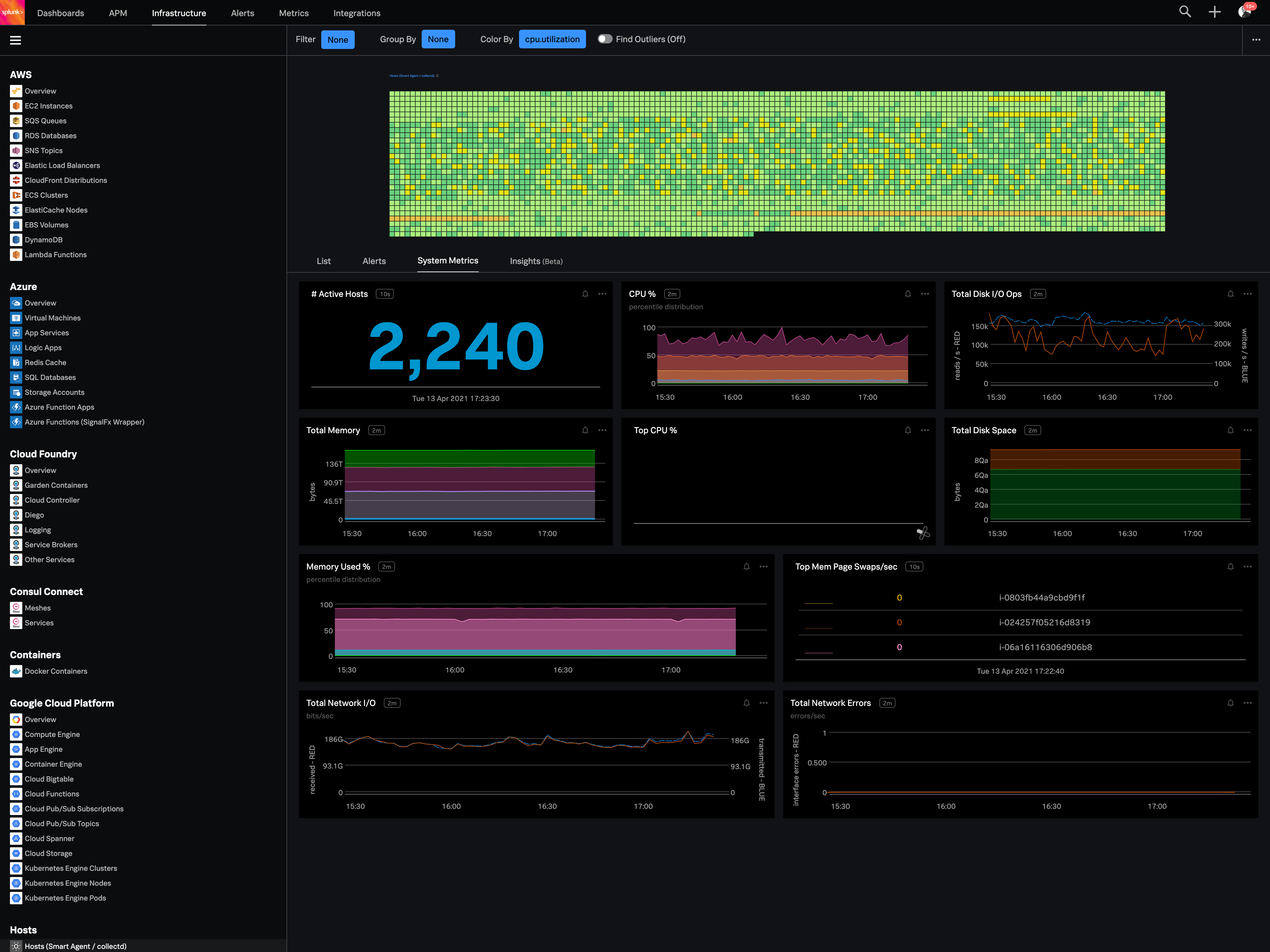
SignalFX is Real-Time Cloud Monitoring and Observability for Infrastructure, Microservices and Applications. SignalFX was acquired by Splunk in August 2019. SignalFX Infrastructure Monitoring provides real-time cloud monitoring and observability platform for infrastructure, microservices and DevOps. A new SignalFX product, SignalFx Microservices APM, was released March 2020 to detect issues, provide real-time app troubleshooting, and future-proof expectations.
Nagios monitoring is well suited for any mission critical application that requires per/second (or minute) monitoring. This would probably include even a shuttle launch. As Nagios was built around Linux, most (85%) plugins are Linux based, therefore its more suitable for a Linux environment.
As Nagios (and dependent components) requires complex configurations & compilations, an experienced Linux engineer would be needed to install all relevant components.
Any company that has hundreds (or thousands) of servers & services to monitor would require a stable monitoring solution like Nagios. I have seen Nagios used in extremely mediocre ways, but the core power lies when its fully configured with all remaining open-source components (i.e. MySQL, Grafana, NRDP etc). Nagios in the hands of an experienced Linux engineer can transform the organizations monitoring by taking preventative measures before a disaster strikes.
Splunk Infrastructure Monitoring is well suited for any complicated environment where you have apps and servers across multiple clouds and platforms and products. If you have a data centre where all your apps and servers are in one single network, you could probably get away with older solutions. But for any modern, complex, hybrid-cloud microservices environment, Splunk Infrastructure Monitoring is a must-have.
SignalFX handles historical metric aggregation exceptionally well, providing a multifaceted approach to event detection based on anomalies.
SignalFX's cost is incredibly flexible with their pricing model of DPM (data-point per minute) vs the traditional "per host" model that most monitoring SaaS use.
SignalFX support is responsive and knowledgeable, very eager to help solve your immediate problems.
SignalFX integrations is vast and constantly growing, making adoption easy even when multiple different open-source technologies are used in your stack.
Nagios could use core improvements in HA, though, Nagios itself recommends monitoring itself with just another Nagios installation, which has worked fine for us. Given its stability, and this work-around, a minor need.
Nagios could also use improvements, feature wise, to the web gui. There is a lot in Nagios XI which I felt were almost excluded intentionally from the core project. Given the core functionality, a minor need. We have moved admin facing alerts to appear as though they originate from a different service to make interacting with alerts more practical.
We're currently looking to combine a bunch of our network montioring solutions into a single platform. Running multiple unique solutions for monitoring, data collection, compliance reporting etc has become a lot to manage.
Good: Stable system with low error rate Easy to use for simple use cases Bad: UI is not very clear for complex usage Mobile view (when logged in from phone) is bad No library for .net
The Nagios UI is in need of a complete overhaul. Nice graphics and trendy fonts are easy on the eyes, but the menu system is dated, the lack of built in graphing support is confusing, and the learning curve for a new user is too steep.
I find that learning the interface can take some time. We need a better show-and-tell on how the Teams pages, Dashboard Groups, Dashboards and charts delay. Advance SignalFlow is sometimes hard to build. Some better samples of advanced SignalFlow would be helpful. For example, Splunk SPL has a vast resource of examples.
I haven't had to use support very often, but when I have, it has been effective in helping to accomplish our goals. Since Nagios has been very popular for a long time, there is also a very large user base from which to learn from and help you get your questions answered.
Because we get all we required in Nagios [Core] and for npm, we have to do lots of configuration as it is not as easy as Comair to Nagios [Core]. On npm UI, there is lots of data, so we are not able to track exact data for analysis, which is why we use Nagios [Core].
They’re not for the same purpose but we’re using NewRelic and Honeycomb for monitoring purposes. NewRelic is used for HTTP client monitoring for system related throughput, error, database and external client monitoring. Honeycomb is used to monitor actual HTTP request/response values. Splunk [Infrastructure Monitoring] is used for real-time application related throughout and error monitoring.
With it being a free tool, there is no cost associated with it, so it's very valuable to an organization to get something that is so great and widely used for free.
You can set up as many alerts as you want without incurring any fees.
Caused us to get a lot of spam when we redeployed apps and old instances stopped sending metrics. Muting alerts solves this, but people often forget to do it or do it incorrectly.
Helped us find historical info about instances/apps.