Amazon Redshift is a hosted data warehouse solution, from Amazon Web Services.
$0.24
per GB per month
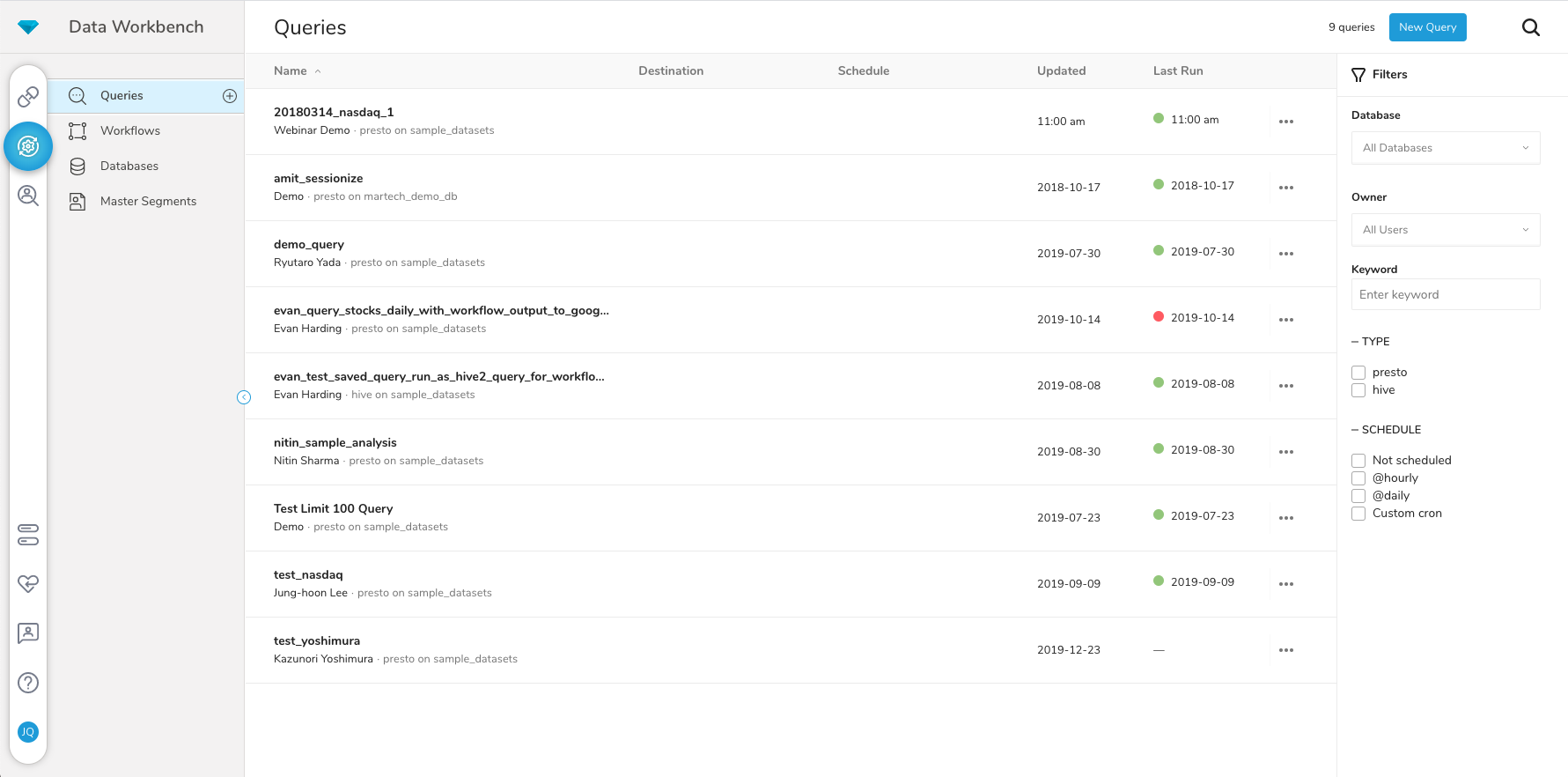
Treasure Data
Score 8.3 out of 10
Mid-Size Companies (51-1,000 employees)
Treasure Data is an enterprise customer data platform (CDP) that powers the entire business to reclaim customer-centricity in the age of the digital customer. It does this by connecting all data and uniting teams and systems into one customer data platform to power purposeful engagements that drive value and protect privacy for every customer, every time. According to the vendor, Treasure Data serves customers globally across a broad base of industries that…
From an engineers perspective data must be available in near real time and from business perspective data must to consistent all over which is perfectly supported by Amazon Redshift. Scalability and performance tuning is well designed in Redshift. Business can make decisions and …
Redshift does not have a simple web console interface for us to use. However, one area where Redshift shines and Treasure Data does not is in its pricing model. Auto-scaling is a great feature in Redshift, whereas the Presto-hours business model can be somewhat limiting at …
Treasure Data stacks up very well against its competitors. It is a highly scalable tool with great support. The reason we went ahead with Treasure Data is that it has good customizations and AI capabilities. With machine learning and AI becoming more and more important every …
Treasure Data provides a combination of out of the box connectors, end to end functionality (Ingestion, Storage, Interactive Querying, Workflows and outputs all in one place) that no other solution we've found seems to do well. The fully managed nature of Workflow, combined …
I have not used strong products in the in past to compare TD to but I have heard from my peers that TD is a very solid product compared to the competition
We still use all of the above. They are part of an ecosystem of data software products and each of them has its own purpose. As I mentioned before, easiness of "writes" to TD and the capability of querying vast amounts of data in a reasonable time are a reason we will not be …
Wish heavily depends on Treasure data to store the data. All the critical tables are stored in Treasure Data and reports are generated on top of it. Apart from that machine learning data generation is done in Treasure Data.
If the number of connections is expected to be low, but the amounts of data are large or projected to grow it is a good solutions especially if there is previous exposure to PostgreSQL. Speaking of Postgres, Redshift is based on several versions old releases of PostgreSQL so the developers would not be able to take advantage of some of the newer SQL language features. The queries need some fine-tuning still, indexing is not provided, but playing with sorting keys becomes necessary. Lastly, there is no notion of the Primary Key in Redshift so the business must be prepared to explain why duplication occurred (must be vigilant for)
Treasure Data is well suited to integrating multiple data sources, including online and digital sources. It is also well suited to trigger audience activations to known customers based on their online activity, integrating 3rd party data, and activating target audiences to ad platforms.
[Amazon] Redshift has Distribution Keys. If you correctly define them on your tables, it improves Query performance. For instance, we can define Mapping/Meta-data tables with Distribution-All Key, so that it gets replicated across all the nodes, for fast joins and fast query results.
[Amazon] Redshift has Sort Keys. If you correctly define them on your tables along with above Distribution Keys, it further improves your Query performance. It also has Composite Sort Keys and Interleaved Sort Keys, to support various use cases
[Amazon] Redshift is forked out of PostgreSQL DB, and then AWS added "MPP" (Massively Parallel Processing) and "Column Oriented" concepts to it, to make it a powerful data store.
[Amazon] Redshift has "Analyze" operation that could be performed on tables, which will update the stats of the table in leader node. This is sort of a ledger about which data is stored in which node and which partition with in a node. Up to date stats improves Query performance.
CDP provides a unified view of data from all touchpoints in the customer journey until a single customer uses the service. This feature is very helpful in making service decisions and direction.
It provides a variety of extensions to bring your data together in one place and helps you do this easily.
Kits provided by Treasure Box provide basic but helpful methods for further development of services.
We've experienced some problems with hanging queries on Redshift Spectrum/external tables. We've had to roll back to and old version of Redshift while we wait for AWS to provide a patch.
Redshift's dialect is most similar to that of PostgreSQL 8. It lacks many modern features and data types.
Constraints are not enforced. We must rely on other means to verify the integrity of transformed tables.
I do think that we definitely will be renewing. We are putting major resources, time, and effort into Treasure Data becoming an extension of our organization, in many ways. We are working toward complete synergies with this product and leadership is very excited about the direction we are heading to be completely customer-centric.
Just very happy with the product, it fits our needs perfectly. Amazon pioneered the cloud and we have had a positive experience using RedShift. Really cool to be able to see your data housed and to be able to query and perform administrative tasks with ease.
It's a easy platform to use and give the user detailed logs about what is going on in the workflows, so someone that do not have a lot of experience can start to work with it. And also the master segment usability is awesome, as we can filter a lot of data the way we want.
As treasure data has a 24 hours support, every time we has big issues that impacts the zones, we do have immediatly support from the treasure data team, so I would say that we do not have any issues with availability
Since treasure data has started having a huge amount of data, sometimes we do have problems with the workflows logs because we generate a lot of then. But with integrations I have not to complain, its really easy to integrate with other platforms.
The support was great and helped us in a timely fashion. We did use a lot of online forums as well, but the official documentation was an ongoing one, and it did take more time for us to look through it. We would have probably chosen a competitor product had it not been for the great support
The technical team has a good hold on the nuances of the data related to our organization. I have found the online technical support on their site quite responsive including the L1 support. In cases where the L1 team isn't able to resolve, I have found they are prompt in getting the product team's input to get a quick resolution.
I wasnt here at the training in the start, but I had a few training with treasure data for a few functionalities, and they provided me god explanations and great documentations, eve if the project were in beta.
Than Vertica: Redshift is cheaper and AWS integrated (which was a plus because the whole company was on AWS). Than BigQuery: Redshift has a standard SQL interface, though recently I heard good things about BigQuery and would try it out again. Than Hive: Hive is great if you are in the PB+ range, but latencies tend to be much slower than Redshift and it is not suited for ad-hoc applications.
We chose Treasure Data for the supreme customer service and lack of hidden costs. We don't need to manage any infrastructure or scale anything to meet customer demand. Treasure Data handles everything and makes it easy for us to integrate and focus on the tasks at hand. There may be cheaper options but we do not regret our decision to go with Treasure Data one bit.
Redshift is relatively cheaper tool but since the pricing is dynamic, there is always a risk of exceeding the cost. Since most of our team is using it as self serve and there is no continuous tracking by a dedicated team, it really needs time & effort on analyst's side to know how much it is going to cost.
Our company is moving to the AWS infrastructure, and in this context moving the warehouse environments to Redshift sounds logical regardless of the cost.
Development organizations have to operate in the Dev/Ops mode where they build and support their apps at the same time.
Hard to estimate the overall ROI of moving to Redshift from my position. However, running Redshift seems to be inexpensive compared to all the licensing and hardware costs we had on our RDBMS platform before Redshift.
We have built and supported our source of truth data tables using Treasure. This forms the foundation of our decision making.
Most of our Tableau data sources are created using a Treasure Data export which is executed by workflows on a daily basis which allows us to have visibility into day to day performance and communicate them to a wide variety of roles.
We load custom data into our Salesforce instance which allows us to trigger certain workflows and build accountability - i.e. a "Sale" will only count once a certain product driven event occurs which comes from data we pipe into Treasure and then into Salesforce.