Structured vs. Unstructured Data: Differences, Uses, and More
Understanding, managing, and leveraging data is a crucial task for any modern business. The availability and volume of data have grown exponentially in recent years. In fact, total data creation, consumption, and production is expected to triple in just 5 years between 2020 and 2025.
This data poses a range of opportunities for savvy businesses. It also poses new challenges around data analytics and management for SMBs and enterprises alike.
Structured and unstructured data are the two most common groupings of data. The distinction between structured and unstructured data heavily impacts how businesses approach their own data, and thus what utility they can get from it. Proper data management and identification are essential to staying relevant in a data-drven world.
Structured vs. Unstructured data
At its most basic level, the difference between structured and unstructured data is simple. Whether it be data science in academic, professional, governmental, or any other setting the first thing to understand is:
- Structured data has a fixed field within a file, record or database.
- Unstructured data does not follow a particular field structure.
These few words difference has massive implications for how businesses collect, store, and analyze their data.
Businesses and stakeholders should know how to identify and work with each kind of data. Businesses must be able to understand the nuances of each data type. They also need to know how to store and manage the data. There are also specialized skill sets are helpful or simply necessary to do so. There are also a range of tools available to help businesses throughout this process.
For more visual learners, the video below is a lighting-fast summary of the differences between structured and unstructured data.
What is Structured Data?
Structured data is data that fits within a fixed field, such as a table, within a record or file. This is the type of data that business users work with directly. For instance, any data found in Excel spreadsheets has been structured within the table format.
Business users work with structured data more frequently because it is easier to analyze. Users can store and process the data automatically or manually. The tools and languages for working with structured data are also easier. For instance, structured data is stored in relational databases (RDBMS). These databases allow business users to use a Structured Query Language (SQL) to get data.
There are many advantages to working with structured data. However, data is rarely created in a prestructured format like a table. Most data starts in an unstructured format.
What Is Unstructured Data?
Unstructured data is that which does not fit within a consistent structure or format. It is usually categorized as qualitative data, such as natural language text. Users cannot analyze unstructured data with conventional data tools and methods. This poses a big problem– 80% or more of enterprise data is unstructured.
Unstructured data can take many forms. Examples of unstructured data include:
- Text
- Video files
- Audio files (i.e. mp3)
- Images
- Social media posts
- abstract data, i.e. behavioral data
- Mobile data
A big component of unstructured data’s challenge is the variety of forms it takes. It follows no predefined data model. This means that businesses can’t organize it in a relational database.
Unstructured data does not mean that the data cannot be structured. It just means that no one has transformed the data into a structured format yet. In most workflows, unstructured data goes through a structuring/transforming process before analysis.
Bonus: What Is Semistructured Data?
There are some data types that fall in between structured and unstructured data. This “semistructured” data is technically structured data. However, it does not fit into the formal structure of a relational database. Examples of semi-structured data formats include JSON, XML, and CSV filetypes.
Semistructured data doesn’t have a specific tabular data model. It does include more tools to assist with analysis than unstructured data. Common semistructured tools include tags and semantic elements. Analysts and data scientists can use these indicators to format the data into a dataset.
| Structured Data | Unstructured Data | |
| Definition | Data That Fits Into a Table or Other Fixed Field | Data That Does Not Fit Into a Fixed Field or Consistent Structure |
| Examples | Quantitative Data, Categorized Data | Images, Audio files, Natural language/text, large text files Social Media Content, Digital Behavior Data |
| Storage | Relational Database Management System (RDBMS), Data Warehouse | NoSQL databases, Data lakes |
| Analysis | Conventional Methods and Tools, Excel, Google Sheets, Artificial Intelligence | Specialized tools, Natural language, Processing (NLP)Text Mining, Some manual analysis |
| Users | Business Professionals, Data Analysts | Data Scientists, Data Engineers |
Structured vs. Unstructured Data: 4 Key Differences
There are some core definitional differences to highlight between structured and unstructured data. Structured data fits into rows and columns, making it easy to access in relational databases. In contrast, unstructured data does not have a predefined data model to follow.
The clearest distinction between structured/unstructured data is quantitative and qualitative data, respectively. Quantitative data consists of numbers or countable values. This makes quantitative data easy to structure. Qualitative data is most other forms of data, such as open text. There is much more variety in the format and orientation of qualitative data. This makes it impossible to analyze via conventional methods.
These differences impact how businesses store and analyze structured and unstructured data.
1. Storing Structured and Unstructured Data
Structured data is easier to store at scale than unstructured data, in most cases. It takes up less storage space because it is prestructured to a particular format. In contrast, unstructured data requires the storage function to handle a wider variety of formats.
As mentioned above, structured data resides in relational databases. At smaller scales, these databases can be accessible and even free in some cases. At scale, these databases become data warehouses. Data warehouses are high-volume, long-term repositories for structured data. They are usually the endpoint for the Extraction, Transformation, and Loading (ETL) pipeline. This pipeline gets data into a structured format before sending it to the data warehouse. Cloud data warehouses have also become more accessible in recent years.
Unstructured data is usually stored at scale in data lakes. Data lakes are a more freeform repository that stores data in its original format or with minor “cleaning.” Data lakes use more raw storage space, but have much more flexibility than warehouses.
2. Analyzing Structured & Unstructured Data
Structured data is much easier to analyze. Traditional tools and programs can often analyze structured data at scale. Business professionals usually analyze structured data within the first year, or even month, of their careers. Once you’ve run a pivot table or formula in Excel, you’ve reached this checkpoint.
Analyzing unstructured data is a more intensive and specialized process. Users almost always have to run the data through some kind of structuring tool and process. A simple example would be getting a word frequency count within a series of text. Machine learning and algorithms make this step more accessible for data analysts.
More advanced analytics tools will do this transformation step behind the scenes. For instance, natural language processing (NLP) and text mining can analyze unstructured text tat scale. Even if it’s not visible, structuring the data to some extent is still necessary.
3. Who can Work with Unstructured Data?
Structured data has a relatively low barrier to entry for management and analysis. Business users can analyze structured data via programs like Excel and Google sheets. Unstructured data analysis is a more complicated process.
More technical specialists tend to be the users working directly with unstructured data. This is because unstructured data requires knowledge of scalable data integration, preparation, and integrity practices. Common titles for these users include data scientists and data engineers. They can analyze unstructured data for their own use. Others focus on transforming unstructured data for non-technical users. Larger organizations have entire teams dedicated to managing unstructured data for the business.
4. Structured Data and Big Data
As mentioned above, structured data is much easier to store. With high volumes of data (i.e. “big data”), data storage efficiency becomes a key consideration. Structured data has traditionally been much easier for big data applications to digest.
The exponential growth of data necessitates better tools for analyzing data at scale. This need is just as relevant across structured and unstructured data. Fortunately, modern analytics tools have been making strides in big data analytics. These advancements have made unstructured data analytics more accessible as well.
Unstructured Data Analysis in a Modern Business World
This is an area that has seen colossal investment in the past decade, and will likely explode in the next. The requirement to manage unstructured data is cited by 95 percent of firms as a challenge, and 97.2 percent of businesses are investing in big data and artificial intelligence for the growth of their businesses and brands. New Machine learning algorithms are developed and improved constantly in an effort to keep up with this demand.
One of the major factors both driving innovation and expanding use-cases are the expansion of data sources. Social media is nothing new at this point, but the sheer amount of data mined from these sites is astonishing. While location data, demographics, and other structured forms have been sold for years, machine learning is allowing businesses to glean more from unstructured information as well.
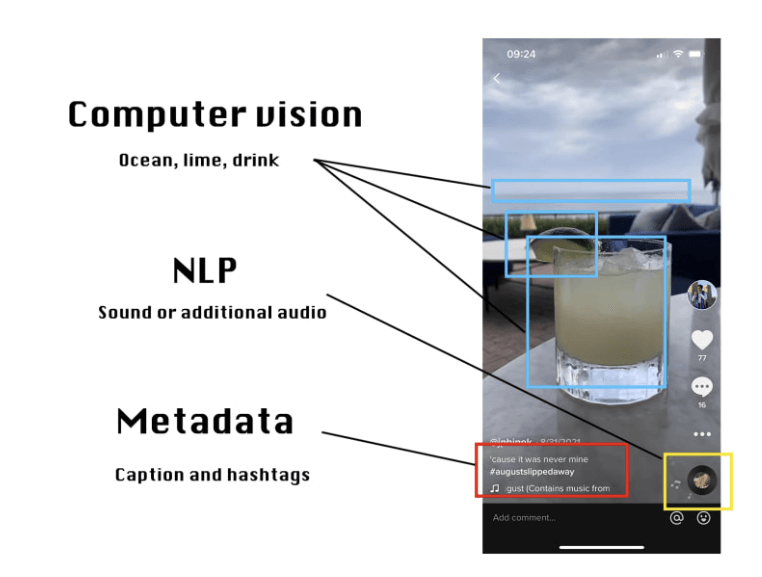
One perfect example of this in action is happening at TikTok. This fascinating piece demonstrates some of the ways Tiktok is gathering, classifying, and using data.
As we can see in the image below, computer vision is allowing data to be processed using schema in much the same way the human mind does. This allows examining of data structures in its native format. Combines with more traditional methods of data gathering and metadata, TikTok can use this to create an addictive product with more targeted ads.
Structured and Unstructured Data Management Tools
For buyers looking to handle unstructured data, their first search should be for use case-specific options. For instance, security systems can create massive amounts of unstructured or semistructured data. Data systems like SIEM and XDR can normalize and structure that data. At that point, security specialists can manually respond or set automatic policies.
Failing that, there are some general resources and capabilities to look for. For instance, NoSQL databases can provide the repository for unstructured data. Other databases and Databases-as-a-Service can also handle unstructured data. Well-known examples include Hadoop and related products, as well as Google BigQuery.
- PostgreSQL is a classic structured data storage/management system but it’s low-level, requiring knowledge of SQL to access the data in a useful way
Tools for Analyzing Unstructured Data
As unstructured data grows in variety and volume, tools to handle the data also develop. Many of these tools are specific to certain data types or use cases. Machine learning and AI-driven analytics have dramatically improved our ability to work with unstructured data. Structured data can use machine learning too. However, the massive volume and variation in unstructured data virtually requires it.
- MongoDB is comparable to PostgreSQL in that you need to be familiar with their query language to get much use from it and find what you are looking for
How to Handle Your Data
No two business’s data look identical. Businesses will benefit long-term from considering how they will manage data before collection. This includes thinking through questions like:
- Is this data structured or unstructured?
- What data repository is best suited for this kind of data?
- What skillsets are necessary to manage this data? What about analyzing it?
- What tools are available to make analysis easier?
- What should be done by hand or can be automated?
- Does this data need to be accessible by non-technical users?
Knowing the answers to these questions will help your business extract value from its data. There are also myriad use case and industry-specific factors to consider. Investing in planning and preparation early will help avoid data headaches later on. Investing in the right technology is also a key step. User reviews of products can often suggest what questions buyers should ask themselves and vendors. Consider checking out our piece on Free Database Software. The video below also gives more insight into SQL-based databases vs the NoSQL options mentioned above:
Was this helpful?
