Amazon Elasticsearch Service is a fully managed service that enables users to search, analyze, and visualize your log data at petabyte-scale. As a fully managed service, Amazon Elasticsearch Service manages the setup, deployment, configuration, patching, and monitoring of Elasticsearch clusters, so users can spend less time managing clusters and more time building applications. With a few clicks in the AWS console, users create scalable, secure, and available Elasticsearch clusters. Amazon…
N/A
Apache Lucene
Score 9.0 out of 10
N/A
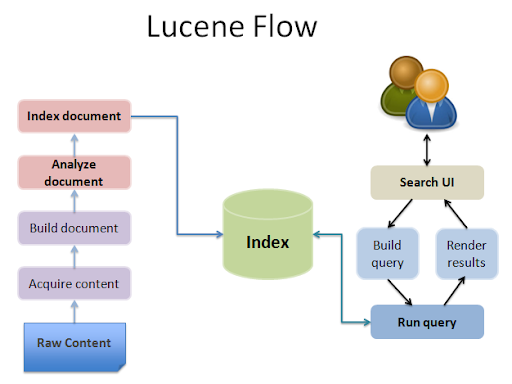
Apache Lucene is an open source and free text search engine library written in Java. It is a technology suitable for applications that requires full-text search, and is available cross-platform.
Applications Developer Information Technology Specialist
Chose Apache Lucene
The search and index performance of [Apache] Lucene is excellent and the quality of results is good, if not better. For implementing it with small scale applications it is a no brainer, Lucene is the best and most cost effective solution. Learning curve is not too steep either.
Elasticsearch is a good alternative to relational databases for setting up complex searching of data. It's inbuilt features for slicing the data [in] different ways and its ability to add weights to search results makes it easy to set up complex searching scenarios. Given that data must be pushed to this service, it may be best suited for data that is not changing very rapidly.
Apache Lucene is a perfect text search implementation where the heap space usage needs to be kept to its minimal. It also enables search based on various search fields and most importantly the search and index process can happen simultaneously. The only scenario where it might be less appropriate would be when the index size grows too big. We have witnessed few scalable issues where the search would take a while when the index size is too large.
We found Apache Lucene to be extremely performant in querying large amounts of data and retrieving the correct files based on the metadata provided.
The online community offers great support for the product. Even though it is an open source tool, it is not difficult to find help online for it.
When we were creating a proof of concept application, we found that the software worked just as well, while being run locally on a resource-limited PC.
It is an extremely powerful tool if the time is put in to learn it. There are basic skeletons of out of the box behavior, it involves having really dedicated people to learn how to use it to take full advantage of its capabilities. A 10 for the tool itself, minus 3 for the difficulty in learning and maintenance
Splunk is the most flexible of the 3 where you can manipulate the data to whatever fits your specific use case. Grafana has the most powerful capabilities but the steepest learning curve. Grafana also does offer the most flexibility as you can visualize almost any data source. Elastic is a solid middle ground between the 2
The search and index performance of [Apache] Lucene is excellent and the quality of results is good, if not better. For implementing it with small scale applications it is a no brainer, Lucene is the best and most cost effective solution. Learning curve is not too steep either.
Being an open source project we did not have to pay any licensing fees for using Apache Lucene. It has greatly improved our search functionality in our web apps.