Chose Apache Kafka
It has very minimal overhead and doesn't have a steep learning curve.
| Product | Rating | Most Used By | Product Summary | Starting Price |
|---|---|---|---|---|
 Apache Kafka | N/A | Apache Kafka is an open-source stream processing platform developed by the Apache Software Foundation written in Scala and Java. The Kafka event streaming platform is used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. | N/A | |
 Apache Lucene | N/A | Apache Lucene is an open source and free text search engine library written in Java. It is a technology suitable for applications that requires full-text search, and is available cross-platform. | N/A |
| Apache Kafka | Apache Lucene | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Editions & Modules | No answers on this topic | No answers on this topic | ||||||||||||||
| Offerings |
| |||||||||||||||
| Entry-level Setup Fee | No setup fee | No setup fee | ||||||||||||||
| Additional Details | — | A free and open source product. | ||||||||||||||
| More Pricing Information | ||||||||||||||||
| Apache Kafka | Apache Lucene | |
|---|---|---|
| Considered Both Products |  Apache Kafka  Alok Pabalkar Co-Founder & CTO Chose Apache Kafka - The biggest advantage of using Apache Kafka is that it is cloud agnostic - It handles super high volume, is fault tolerance, high performance  Animesh Kumar Senior Member of Technical Staff Chose Apache Kafka Apache Kafka can work at a higher scale as compared to SQS. It can work with higher size per message and millions of messages per second. Moreover it can be scaled horizontally by adding more brokers to the cluster. SQS is good enough for simple use cases like making a task …  Tyler Twitchell Senior System Engineer Chose Apache Kafka We really needed to get away from using a SQL database to act as a queue for processing records, so a new solution was needed. Kafka is a leading software application initially designed for queuing messages which is essentially what we were looking for. It has a great user …  Borislav Traykov DevOps Team Leader Chose Apache Kafka For us, Kafka really doesn't have a 1:1 alternative. We have used ActiveMQ extensively and we still use it as a lighter option for small messages. The situation is similar with Redis - although it could be used like a Kafka alternative, we do use it just as a per-component …  Viral Patel Senior Software Engineer Chose Apache Kafka We had lots of problems with active mq. That is why we started using Apache Kafka.  Juan Francisco Tavira Global Technology Centre - Middleware Chose Apache Kafka Kafka is faster and more scalable, also "free" as opensource (albeit we deploy using a commercial distribution). Infrastructure tends to be cheaper. On the other hand, projects must adapt to Kafka APIs that sometimes change and BAU increases until a major 1.x version comes out … | Apache Lucene  Sirish Vadala Applications Developer Information Technology Specialist Chose Apache Lucene The search and index performance of [Apache] Lucene is excellent and the quality of results is good, if not better. For implementing it with small scale applications it is a no brainer, Lucene is the best and most cost effective solution. Learning curve is not too steep either.  Craig J. Stadler Search Engineer Chose Apache Lucene I have tried Elastic and Sphinx, each has their benefits but I feel like Apache Lucene overall is the best performing and easiest to setup and maintain. |
| Apache Kafka | Apache Lucene | |
|---|---|---|
| Small Businesses | No answers on this topic |  Yext Score 7.4 out of 10 |
| Medium-sized Companies |  IBM MQ Score 8.8 out of 10 |  Guru Score 9.3 out of 10 |
| Enterprises | IBM MQ Score 8.8 out of 10 | Guru Score 9.3 out of 10 |
| All Alternatives | View all alternatives | View all alternatives |
| Apache Kafka | Apache Lucene | |
|---|---|---|
| Likelihood to Recommend | 8.0 (0 ratings) | 10.0 (0 ratings) |
| Likelihood to Renew | 9.0 (0 ratings) | - (0 ratings) |
| Usability | 8.0 (0 ratings) | - (0 ratings) |
| Support Rating | 8.4 (0 ratings) | - (0 ratings) |
| Apache Kafka | Apache Lucene | |
|---|---|---|
| Likelihood to Recommend |
|
|
| Pros |
|
Sirish Vadala Applications Developer Information Technology Specialist |
| Cons |
Borislav Traykov DevOps Team Leader |
|
| Likelihood to Renew |
Animesh Kumar Senior Member of Technical Staff | No answers on this topic |
| Usability |
| No answers on this topic |
| Support Rating |
| No answers on this topic |
| Alternatives Considered |
|
Sirish Vadala Applications Developer Information Technology Specialist |
| Return on Investment |
|
Craig J. Stadler Search Engineer |
| ScreenShots | Apache Lucene Screenshots 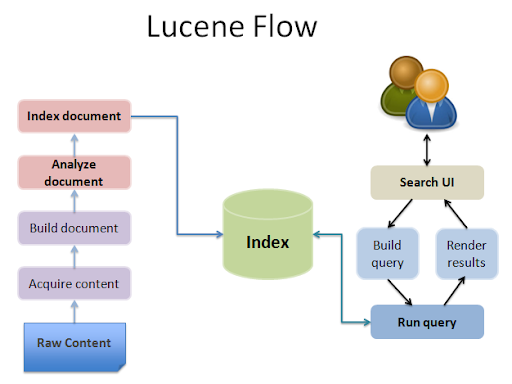 |