Apache Spark vs. esProc SPL Community
Apache Spark vs. esProc SPL Community
| Product | Rating | Most Used By | Product Summary | Starting Price |
|---|---|---|---|---|
 Apache Spark | N/A | Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters. | N/A | |
 esProc SPL Community | Small Businesses (1-50 employees) | esProc SPL is an open-source and JVM-based analyzing and computing engine for structured data and semi-structured data, and capable at solving data problems, including hard to write, slow to run and difficult to operate and maintain. esProc SPL adopts self-created SPL (Structured Process Language) syntax, boasting the characteristics of low code, high performance, lightweight and versatility. Compared with SQL, SPL has more abundant data types and calculation features, which enhances… | $0 |
| Apache Spark | esProc SPL Community | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Editions & Modules | No answers on this topic | No answers on this topic | ||||||||||||||
| Offerings |
| |||||||||||||||
| Entry-level Setup Fee | No setup fee | No setup fee | ||||||||||||||
| Additional Details | — | — | ||||||||||||||
| More Pricing Information | ||||||||||||||||
| Apache Spark | esProc SPL Community |
|---|
| Apache Spark | esProc SPL Community | |
|---|---|---|
| Small Businesses | No answers on this topic |  Jupyter Notebook Score 8.5 out of 10 |
| Medium-sized Companies |  Cloudera Manager Score 9.9 out of 10 |  Posit Score 10.0 out of 10 |
| Enterprises |  IBM Analytics Engine Score 7.2 out of 10 | Posit Score 10.0 out of 10 |
| All Alternatives | View all alternatives | View all alternatives |
| Apache Spark | esProc SPL Community | |
|---|---|---|
| Likelihood to Recommend | 9.0 (24 ratings) | - (0 ratings) |
| Likelihood to Renew | 10.0 (1 ratings) | - (0 ratings) |
| Usability | 8.0 (4 ratings) | - (0 ratings) |
| Support Rating | 8.7 (4 ratings) | - (0 ratings) |
| Apache Spark | esProc SPL Community | |
|---|---|---|
| Likelihood to Recommend | Apache
 Ananth Gouri Assistant Professor | scudata No answers on this topic |
| Pros | Apache
 Nitin Pasumarthy Software Engineer | scudata No answers on this topic |
| Cons | Apache
 Anson Abraham Data Czar | scudata No answers on this topic |
| Likelihood to Renew | Apache
 Steven Li Senior Software Developer (Consultant) | scudata No answers on this topic |
| Usability | Apache
| scudata No answers on this topic |
| Support Rating | Apache
| scudata No answers on this topic |
| Alternatives Considered | Apache
| scudata No answers on this topic |
| Return on Investment | Apache
 Surendranatha Reddy Chappidi Senior Data Engineer | scudata No answers on this topic |
| ScreenShots | esProc SPL Community Screenshots  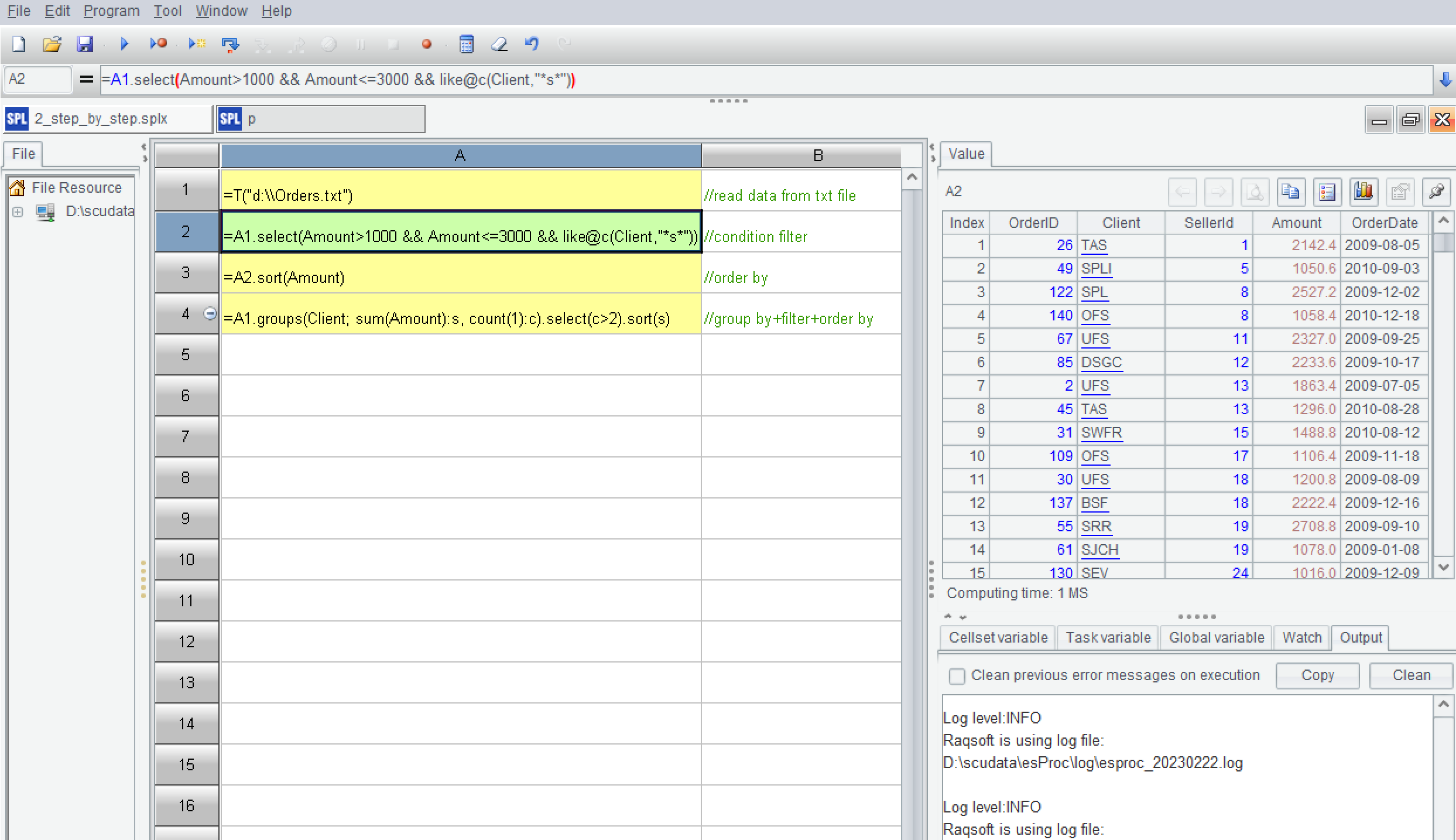  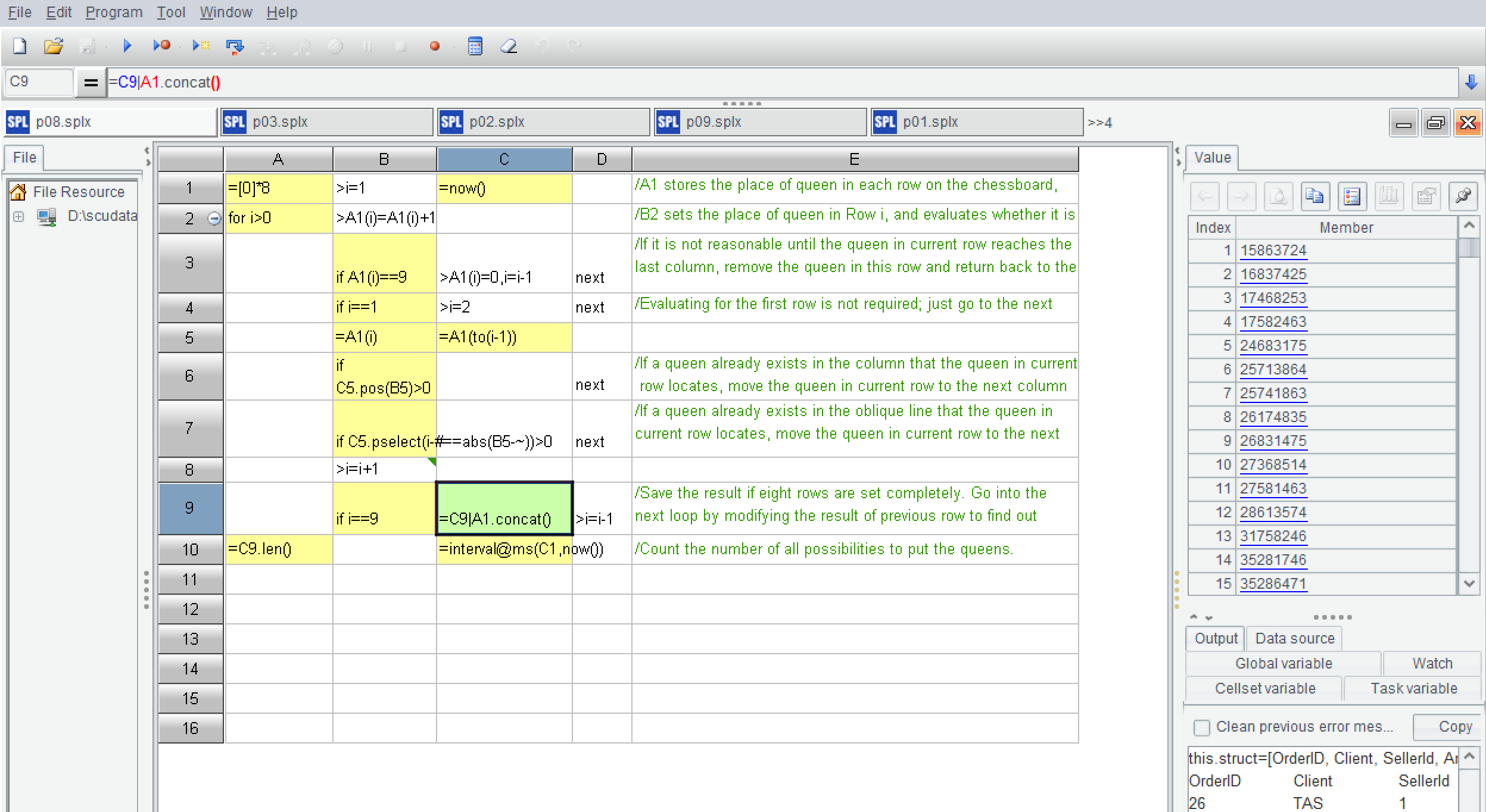 |