Propel your digital transformation.
I use ScienceLogic SL1 at my job at Kyndryl to provide monitoring services of IT infrastructure for clients and customer support teams.
ScienceLogic is a system and application monitoring and performance management platform. ScienceLogic collects and aggregates data across and IT ecosystems and contextualizes it for actionable insights with the SL1 product offering.
Products that are considered exceptional by their customers based on a variety of criteria win TrustRadius awards. Learn more about the types of TrustRadius awards to make the best purchase decision. More about TrustRadius Awards
1 video
ScienceLogic is a system and application monitoring and performance management platform. ScienceLogic collects and aggregates data across and IT ecosystems and contextualizes it for actionable insights with the SL1 product offering.
3 people also want pricing
StackState is an observability solution that helps enterprises decrease downtime and prevent outages by breaking down the silos between existing monitoring tools and tracking changes in dependencies, relationships, and configuration over time. The system relates these changes to incidents,…
IBM AIOps Insights is a solution for event and incident management that offers central IT operations teams a comprehensive view of their managed IT environment, providing holistic context in a single pane of glass. AIOps Insights uses intelligent automation and AI to aggregate information by…
The ScienceLogic SL1 platform aims to enable companies to digitally transform themselves by removing the difficulty of managing complex, distributed IT services. SL1 uses patented discovery techniques to find everything in a network, so users get visibility across all technologies and vendors running anywhere in data centers or clouds. SL1 is that it collects and analyzes millions of data points across an IT universe (made up of infrastructure, network, applications, and business services), to help users make sense of it all, share data, and automate IT processes.
With SL1, the user can:
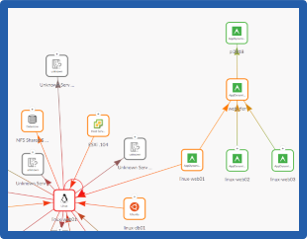






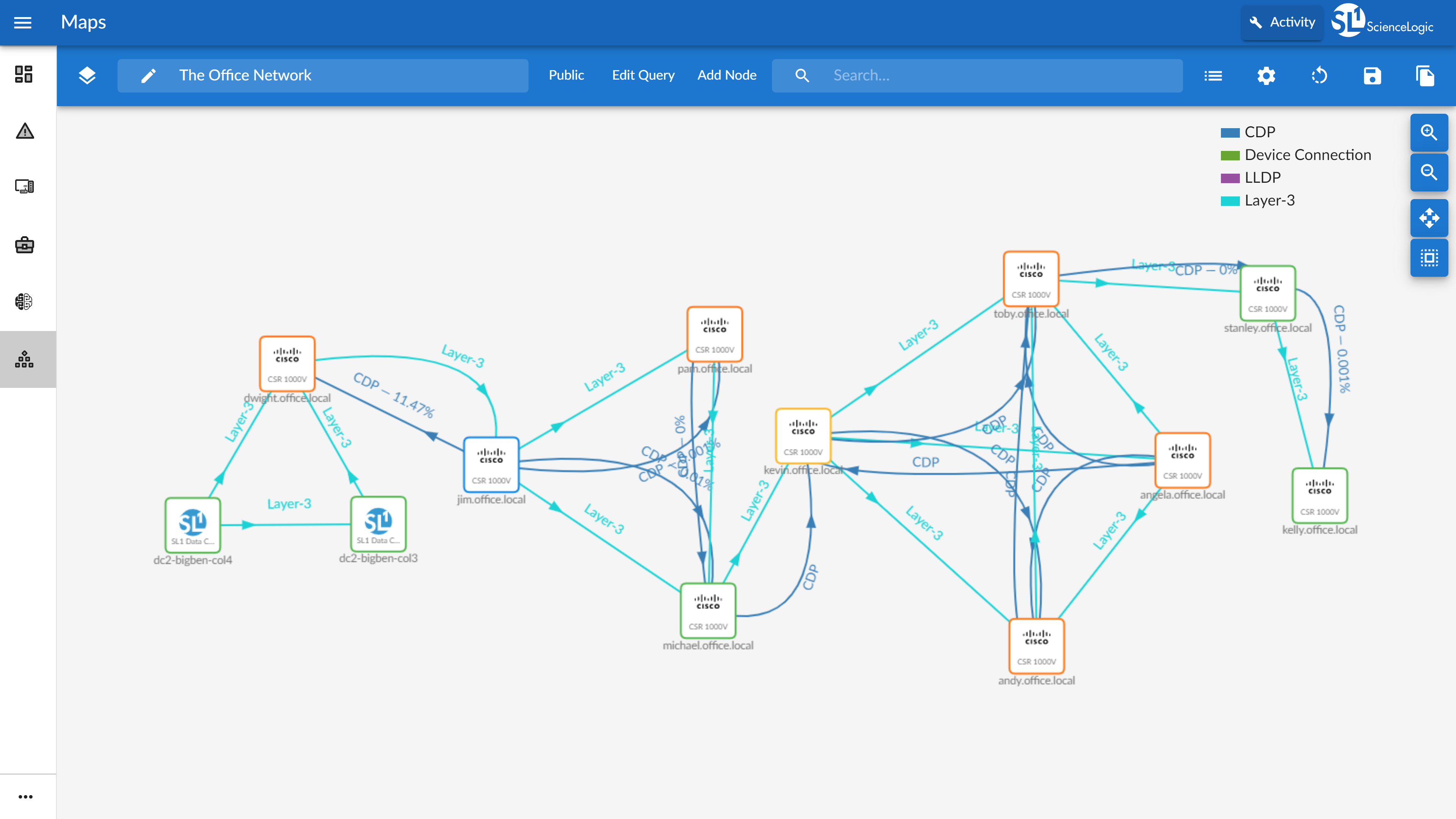
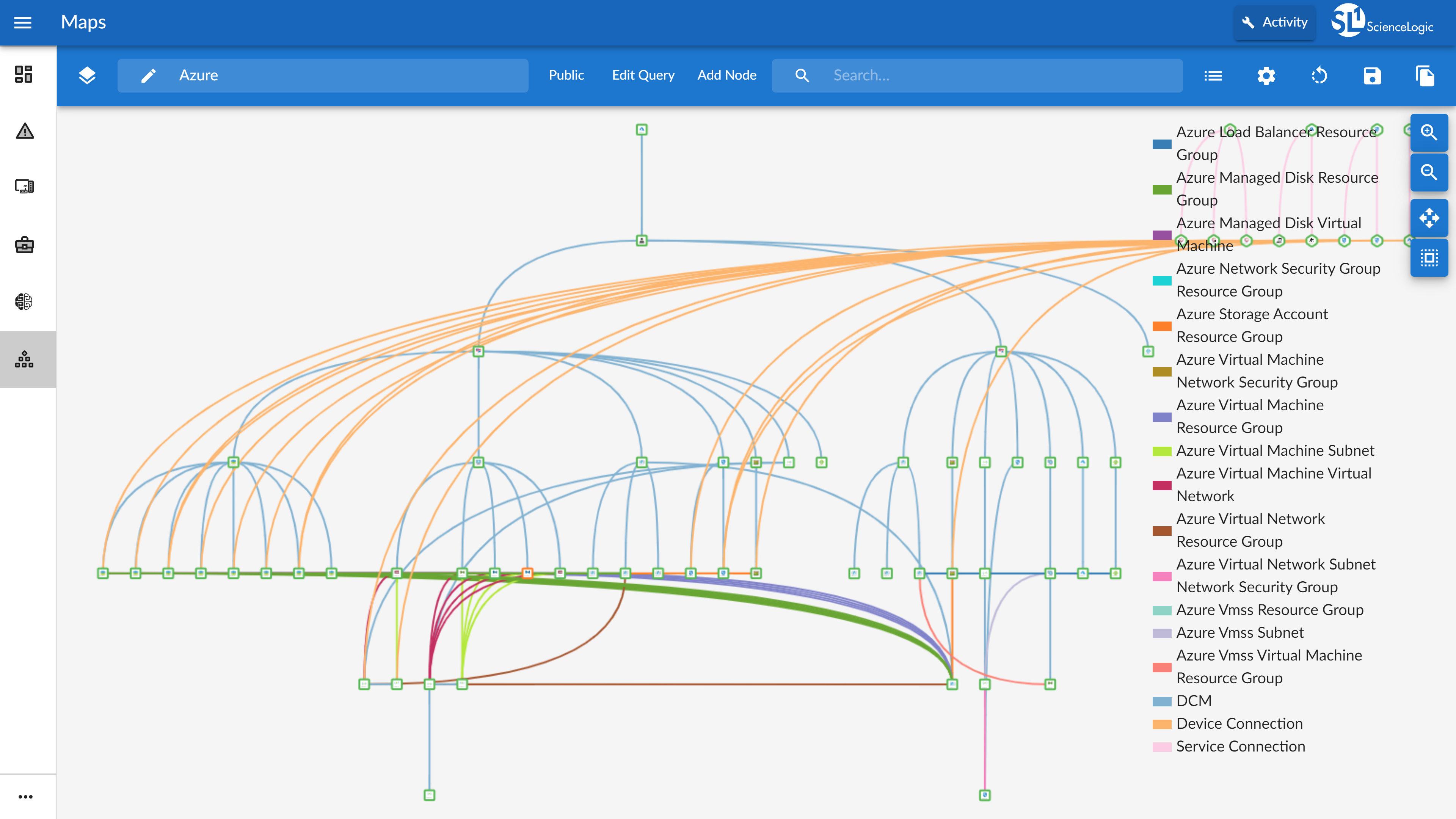
Watch Eliminating Visibility Gaps While Driving Tool Consolidation
Watch Diagnosing and Resolving Service Impacting Issues with Behavioral Correlation
Watch Automating Troubleshooting for Faster Root Cause Analysis
Watch CMDB Accuracy With Real-time Synchronization of Monitored Environment
Watch Understanding Infrastructure Impact on Apps with AppDynamics
| Deployment Types | On-premise, Software as a Service (SaaS), Cloud, or Web-Based |
|---|---|
| Operating Systems | Windows, Linux, Mac, UNIX |
| Mobile Application | No |
| Supported Countries | Americas, EMEA, APAC |
| Supported Languages | English |
| Consumers | 0% |
|---|---|
| Small Businesses (1-50 employees) | 0% |
| Mid-Size Companies (51-500 employees) | 0% |
| Enterprises (more than 500 employees) | 100% |