





Datadog is a fundamentally useful platform for centralized app observabilty and beyond

Use Cases and Deployment Scope
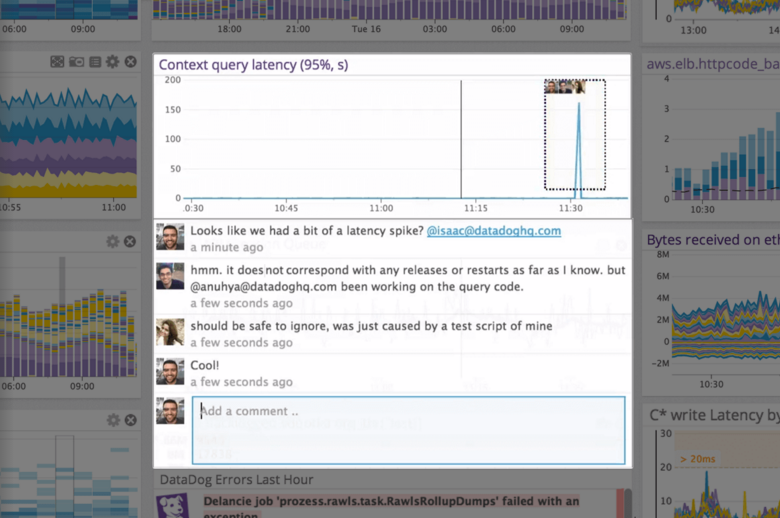
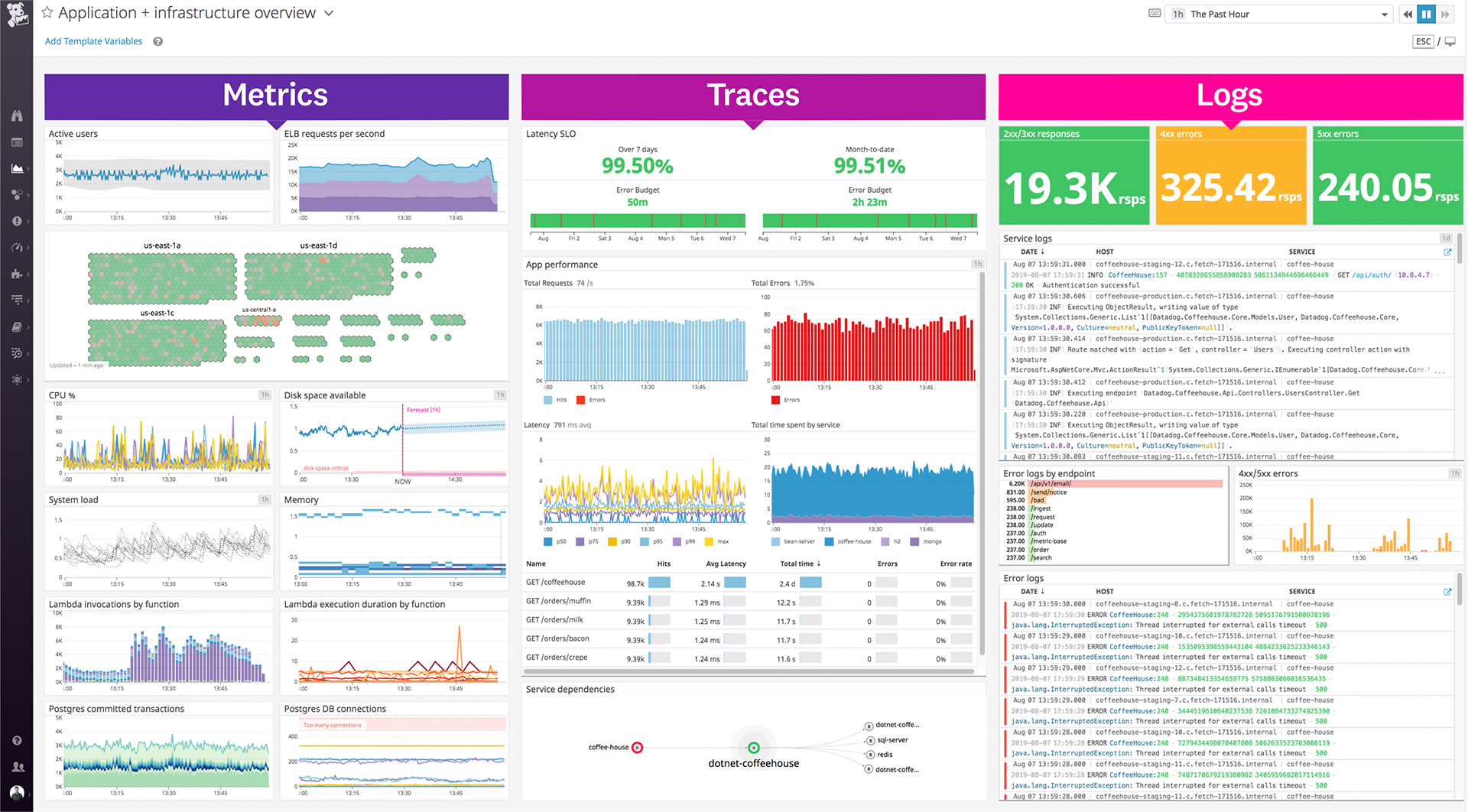
Datadog is our first point of access for developers to review logs and monitoring of key services and architecture. Primarily, we were drowning in trying to find useful logs in AWS Cloudwatch and Datadog's log discovery capabilities are far and away better. We have setup up several key alarms for bad log patterns but have yet to find full utility in monitoring other metrics - largely because we do not have a core platform development team.
Pros
- Log indexing
- Log Searching
- Dashboard building (combining logs and metrics)
- Traceability
- User Monitoring
Cons
- More recipes for fundamental monitoring tooling
- Targetting different scales of application (beyond enterprise SaaS)
- Multiple workspaces in an account to separate users
Return on Investment
- Highly improved distributed compute debugging
- Still waiting for Bits AI access - negative experience on new product rollouts
- Spreadsheets have made reporting to external teams significantly easier
Usability
Alternatives Considered
ClickHouse, Grafana and Sentry
Other Software Used
AWS CloudTrail, Amazon CloudWatch, Google Workspace






