Apache Hive is database/data warehouse software that supports data querying and analysis of large datasets stored in the Hadoop distributed file system (HDFS) and other compatible systems, and is distributed under an open source license.
N/A
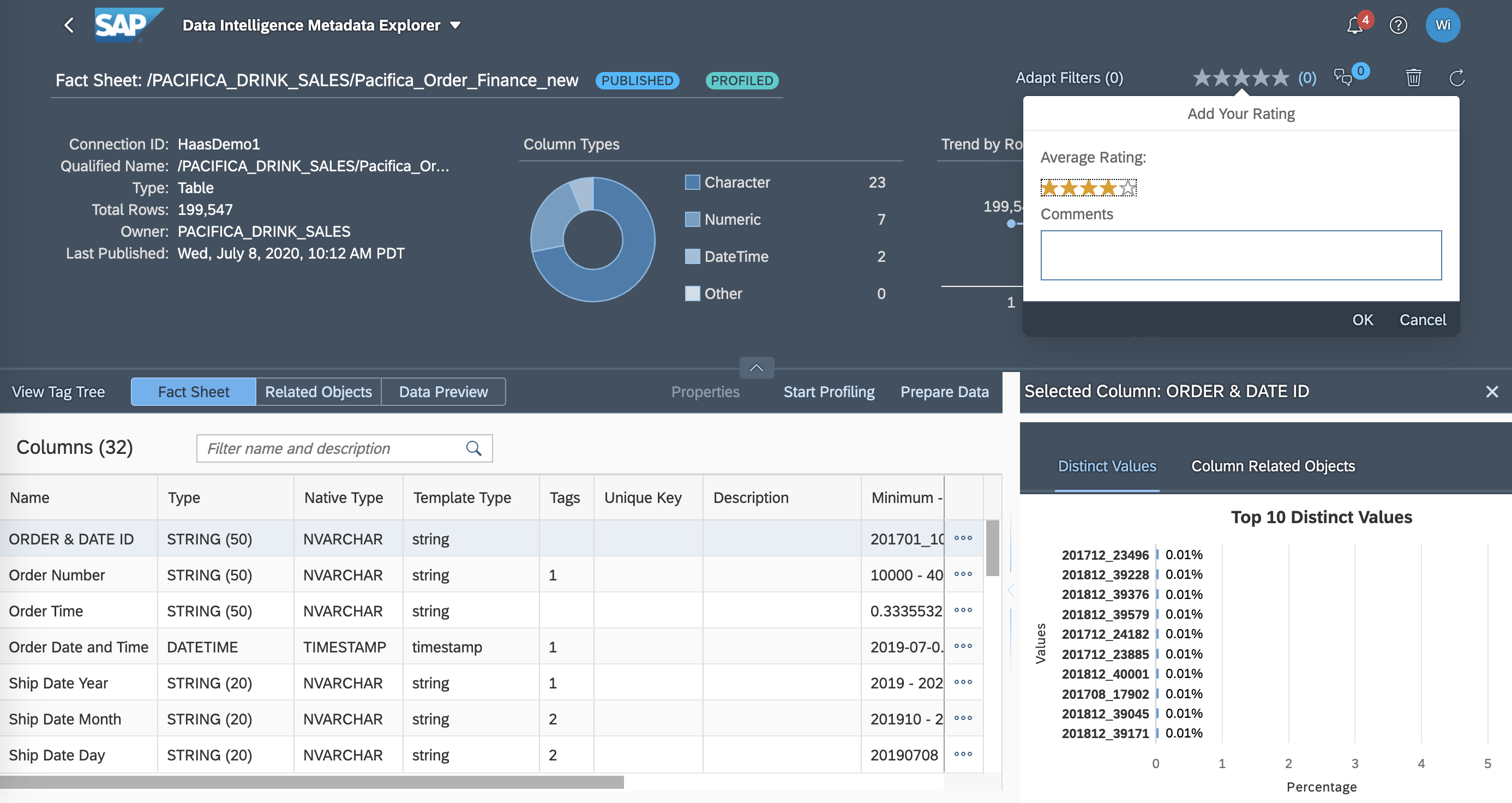
SAP Data Intelligence
Score 8.7 out of 10
N/A
SAP Data Intelligence is presented by the vendor as a single solution to innovate with data. It provides data-driven innovation in the cloud, on premise, and through BYOL deployments. It is described by the vendor as the new evolution of the company's data orchestration and management solution running on Kubernetes, released by SAP in 2017 to deal with big data and complex data orchestration working across distributed landscapes and processing engine.
Software work execution is on a large scale, it is good to use for new projects or organizational changes, data lineage mapping has always been dubious but this one has had good results. You can store and synchronize data from different departments, the storage process can be manual but it is best automated.
If you have an SAP products ecosystem in your IT landscape, it becomes a no-brainer to go ahead with an SAP Data Intelligence product for your data orchestration, data management, and advanced data analytics needs, such as data preparation for your AI/ML processes. It provides a seamless integration with other SAP products.
Apache Hive allows use to write expressive solutions to complex problems thanks to its SQL-like syntax.
Relatively easy to set up and start using.
Very little ramp-up to start using the actual product, documentation is very thorough, there is an active community, and the code base is constantly being improved.
Data transfer speed tends to be slow when there is poor internet connection since SAP Data Intelligence don’t synchronize data while offline. However, this is not vendor fault, that’s why we have implemented robust wireless technology internet connection in our organization.
Allow collaborations among various personas with insights as ratings and comments on the datasets Reuse knowledges on the datasets for new users Next-Gen Data Management and Artificial Intelligence
Hive is a very good big data analysis and ad-hoc query platform, which supports scaling also. The BI processes can be easily integrated with Hadoop via the Hive. It can deal with a much larger data set that traditional RDBMS can not. It is a "must-have" component of the big data domain.
I think the troubleshooting process might be streamlined with improved error recording and tracing. A lot of information about issues and how to fix them is hidden away in the Kubernetes pods themselves. I'm not sure whether SAP Data Intelligence can fix this problem it may be connected to Kubernetes's design, in which case fixing it could need modifications inside Kubernetes itself.
Apache Hive is a FOSS project and its open source. We need not definitely comment on anything about the support of open source and its developer community. But, it has got tremendous developer support, awesome documentation. I would justify the fact that much support can be gathered from the community backup.
Initially we struggle to get help from SAP but then dedicated Dev angel was assigned to us and that simplify the overall support scenario. There is still room of improvement in documentation around SAP Data intelligence. We struggle a lot to initially understand the feature and required help around performance improvement area,
Besides Hive, I have used Google BigQuery, which is costly but have very high computation speed. Amazon Redshift is the another product, I used in my recent organisation. Both Redshift and BigQuery are managed solution whereas Hive needs to be managed
One of the reasons to pick SAP Data Intelligence is the speed and security it provides, in addition to the excellent support it provides. It is also compatible with all popular databases, which is another reason to choose it.