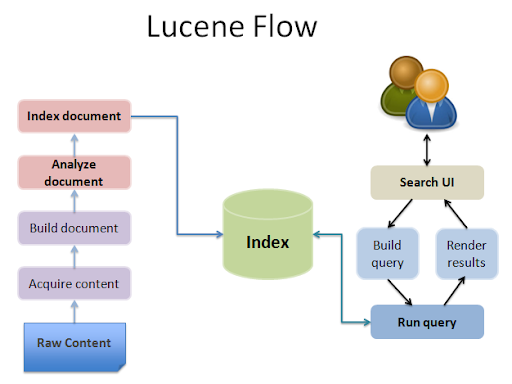
Apache Lucene is an open source and free text search engine library written in Java. It is a technology suitable for applications that requires full-text search, and is available cross-platform.
$0
per month
Presto
Score 10.0 out of 10
N/A
Presto is an open source SQL query engine designed to run queries on data stored in Hadoop or in traditional databases.
Teradata supported development of Presto followed the acquisition of Hadapt and Revelytix.
Apache Lucene is a perfect text search implementation where the heap space usage needs to be kept to its minimal. It also enables search based on various search fields and most importantly the search and index process can happen simultaneously. The only scenario where it might be less appropriate would be when the index size grows too big. We have witnessed few scalable issues where the search would take a while when the index size is too large.
Presto is for interactive simple queries, where Hive is for reliable processing. If you have a fact-dim join, presto is great..however for fact-fact joins presto is not the solution.. Presto is a great replacement for proprietary technology like Vertica
We found Apache Lucene to be extremely performant in querying large amounts of data and retrieving the correct files based on the metadata provided.
The online community offers great support for the product. Even though it is an open source tool, it is not difficult to find help online for it.
When we were creating a proof of concept application, we found that the software worked just as well, while being run locally on a resource-limited PC.
Linking, embedding links and adding images is easy enough.
Once you have become familiar with the interface, Presto becomes very quick & easy to use (but, you have to practice & repeat to know what you are doing - it is not as intuitive as one would hope).
Organizing & design is fairly simple with click & drag parameters.
Presto was not designed for large fact fact joins. This is by design as presto does not leverage disk and used memory for processing which in turn makes it fast.. However, this is a tradeoff..in an ideal world, people would like to use one system for all their use cases, and presto should get exhaustive by solving this problem.
Resource allocation is not similar to YARN and presto has a priority queue based query resource allocation..so a query that takes long takes longer...this might be alleviated by giving some more control back to the user to define priority/override.
UDF Support is not available in presto. You will have to write your own functions..while this is good for performance, it comes at a huge overhead of building exclusively for presto and not being interoperable with other systems like Hive, SparkSQL etc.
The search and index performance of [Apache] Lucene is excellent and the quality of results is good, if not better. For implementing it with small scale applications it is a no brainer, Lucene is the best and most cost effective solution. Learning curve is not too steep either.
Presto is good for a templated design appeal. You cannot be too creative via this interface - but, the layout and options make the finalized visual product appealing to customers. The other design products I use are for different purposes and not really comparable to Presto.
Being an open source project we did not have to pay any licensing fees for using Apache Lucene. It has greatly improved our search functionality in our web apps.