Apache Spark vs. Devart Excel Add-ins
Apache Spark vs. Devart Excel Add-ins
| Product | Rating | Most Used By | Product Summary | Starting Price |
|---|---|---|---|---|
 Apache Spark | N/A | Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters. | N/A | |
 Devart Excel Add-ins | N/A | Devart Excel Add-ins allow you to use Excel capabilities to import, process, and analyze data from cloud applications and relational databases. The Excel Add-ins also allow users to make data changes and then save those changes back to the data source they were originally imported from. | $399.95 one-time fee |
| Apache Spark | Devart Excel Add-ins | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Editions & Modules | No answers on this topic |
| ||||||||||||||
| Offerings |
| |||||||||||||||
| Entry-level Setup Fee | No setup fee | No setup fee | ||||||||||||||
| Additional Details | — | Purchases include a perpetual license and 1 year of subscription which includes the product updates and premium support. | ||||||||||||||
| More Pricing Information | ||||||||||||||||
| Apache Spark | Devart Excel Add-ins |
|---|
| Apache Spark | Devart Excel Add-ins | |
|---|---|---|
| Small Businesses | No answers on this topic |  Skyvia Score 10.0 out of 10 |
| Medium-sized Companies |  Cloudera Manager Score 9.9 out of 10 |  IBM InfoSphere Information Server Score 8.0 out of 10 |
| Enterprises | IBM Analytics Engine Score 7.1 out of 10 | IBM InfoSphere Information Server Score 8.0 out of 10 |
| All Alternatives | View all alternatives | View all alternatives |
| Apache Spark | Devart Excel Add-ins | |
|---|---|---|
| Likelihood to Recommend | 9.0 (24 ratings) | 8.0 (2 ratings) |
| Likelihood to Renew | 10.0 (1 ratings) | - (0 ratings) |
| Usability | 8.0 (4 ratings) | - (0 ratings) |
| Support Rating | 8.7 (4 ratings) | - (0 ratings) |
| Apache Spark | Devart Excel Add-ins | |
|---|---|---|
| Likelihood to Recommend | Apache
 Ananth Gouri Assistant Professor |  Devart
 Scott Kennedy Director, eCommerce Analytics and Digital Marketing |
| Pros | Apache
 Nitin Pasumarthy Software Engineer | Devart
|
| Cons | Apache
 Anson Abraham Data Czar | Devart
Scott Kennedy Director, eCommerce Analytics and Digital Marketing |
| Likelihood to Renew | Apache
 Steven Li Senior Software Developer (Consultant) | Devart No answers on this topic |
| Usability | Apache
| Devart No answers on this topic |
| Support Rating | Apache
| Devart No answers on this topic |
| Alternatives Considered | Apache
| Devart
|
| Return on Investment | Apache
 Surendranatha Reddy Chappidi Senior Data Engineer | Devart
Scott Kennedy Director, eCommerce Analytics and Digital Marketing |
| ScreenShots | Devart Excel Add-ins Screenshots  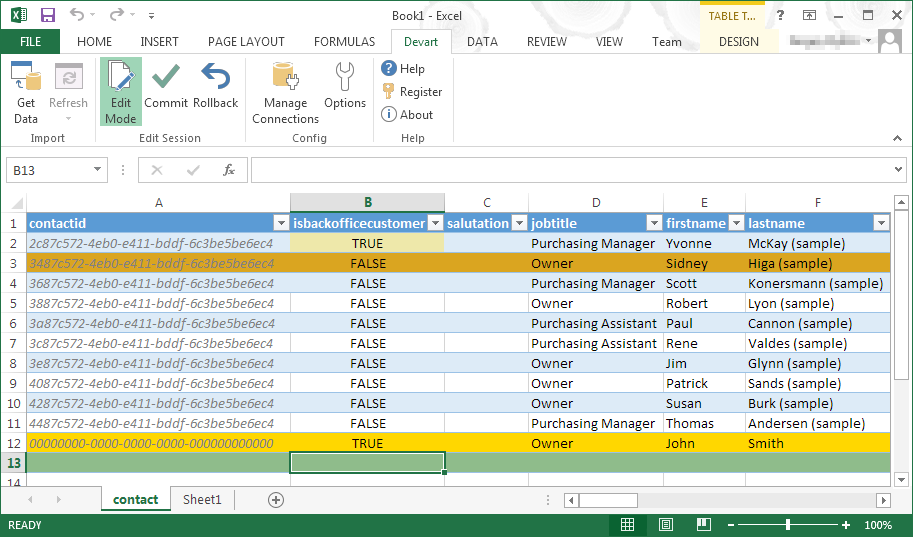 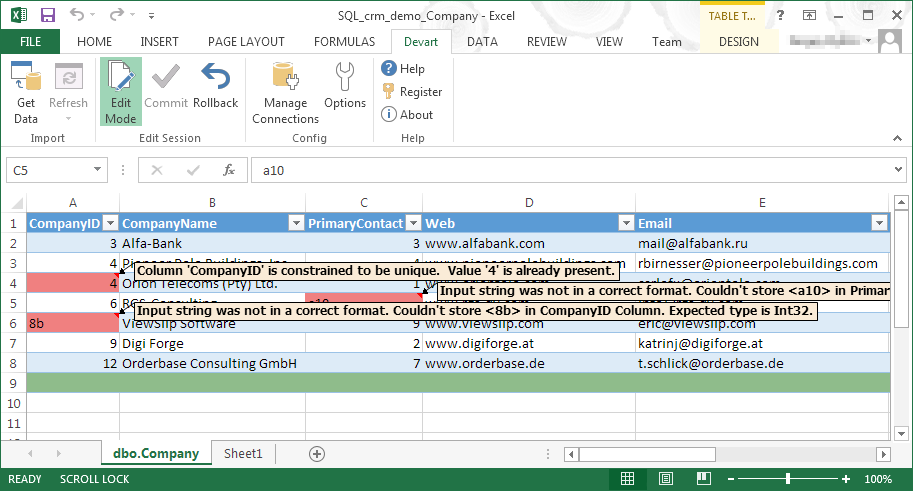 |