Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
N/A
NGINX
Score 9.2 out of 10
Mid-Size Companies (51-1,000 employees)
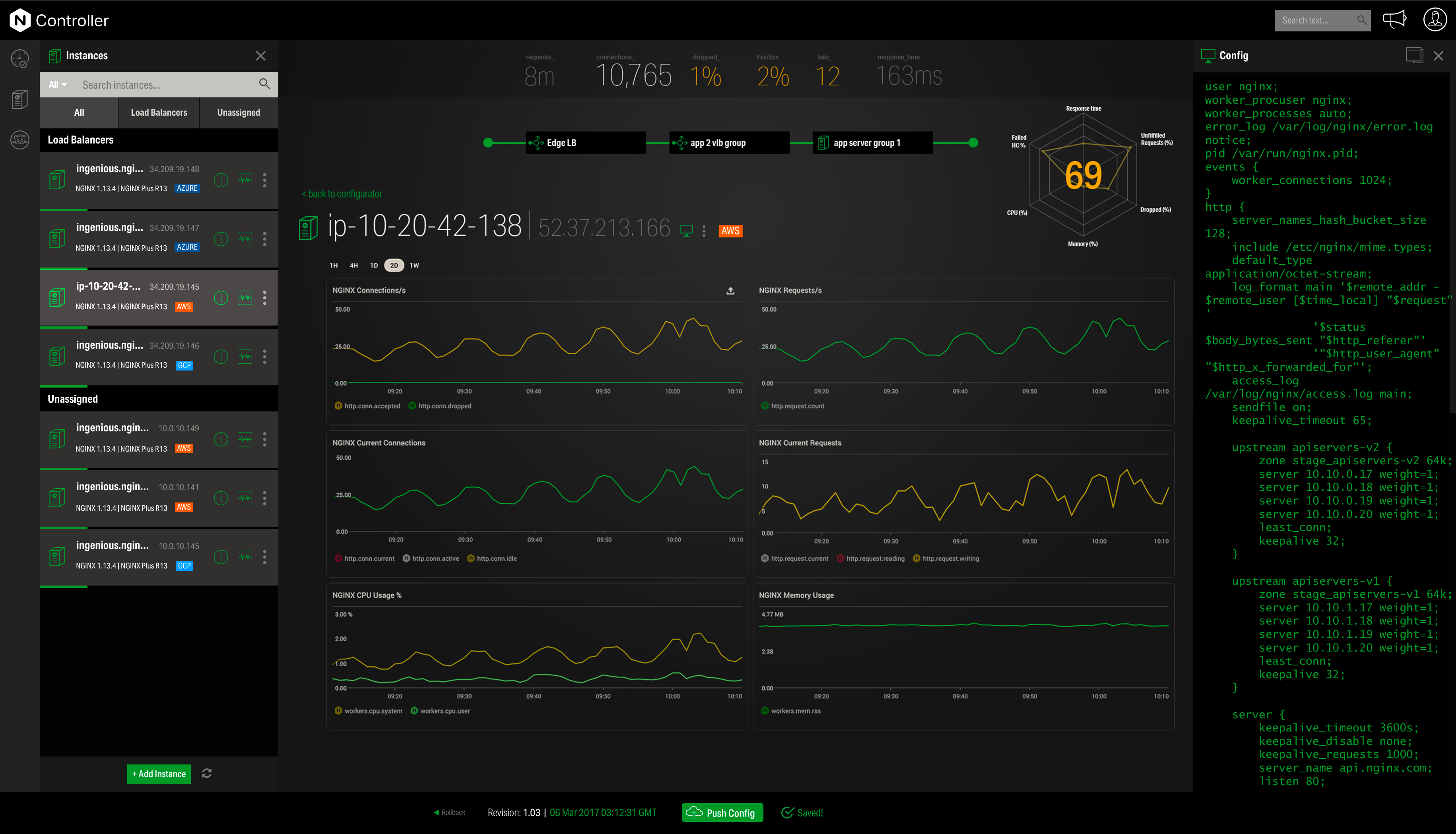
NGINX, a business unit of F5 Networks, powers over 65% of the world's busiest websites and web applications. NGINX started out as an open source web server and reverse proxy, built to be faster and more efficient than Apache. Over the years, NGINX has built a suite of infrastructure software products o tackle some of the biggest challenges in managing high-transaction applications. NGINX offers a suite of products to form the core of what organizations need to create…
Well suited: To most of the local run of datasets and non-prod systems - scalability is not a problem at all. Including data from multiple types of data sources is an added advantage. MLlib is a decently nice built-in library that can be used for most of the ML tasks. Less appropriate: We had to work on a RecSys where the music dataset that we used was around 300+Gb in size. We faced memory-based issues. Few times we also got memory errors. Also the MLlib library does not have support for advanced analytics and deep-learning frameworks support. Understanding the internals of the working of Apache Spark for beginners is highly not possible.
Nginx is well-suited for any web server scenarios, such as web applications, backend or reverse proxy for both application and HTTP requests, and distribution. It is less appropriate for Windows-based applications that run directly on a Windows Server host. In any case, it is very easy to manage, through separate conf files for each application or site you want to host with it.
Customer support can be strangely condescending, perhaps it's a language issue?
I find it a little weird how the release versions used for Nginx+ aren't the same as for open source version. It can be very confusing to determine the cross-compatibility of modules, etc., because of this.
It seems like some (most?) modules on their own site are ancient and no longer supported, so their documentation in this area needs work.
It's difficult to navigate between nginx.com commercial site and customer support. They need to be integrated together.
I'd love to see more work done on nginx+ monitoring without requiring logging every request. I understand that many statistics can only be derived from logs, but plenty should work without that. Logging is not an option in many environments.
If the team looking to use Apache Spark is not used to debug and tweak settings for jobs to ensure maximum optimizations, it can be frustrating. However, the documentation and the support of the community on the internet can help resolve most issues. Moreover, it is highly configurable and it integrates with different tools (eg: it can be used by dbt core), which increase the scenarios where it can be used
This tool is really easy to use and configure. Consumes very less system resources. It is highly modular and configurable. You can easily use it with other tools like certbot for SSLs. You can configure basic security with configuration and headers
1. It integrates very well with scala or python. 2. It's very easy to understand SQL interoperability. 3. Apache is way faster than the other competitive technologies. 4. The support from the Apache community is very huge for Spark. 5. Execution times are faster as compared to others. 6. There are a large number of forums available for Apache Spark. 7. The code availability for Apache Spark is simpler and easy to gain access to. 8. Many organizations use Apache Spark, so many solutions are available for existing applications.
Community support is great, and they've also had a presence at conferences. Overall, there is no shortage of documentation and community support. We're currently using it to serve up some WordPress sites, and configuring NGINX for this purpose is well documented.
Spark in comparison to similar technologies ends up being a one stop shop. You can achieve so much with this one framework instead of having to stitch and weave multiple technologies from the Hadoop stack, all while getting incredibility performance, minimal boilerplate, and getting the ability to write your application in the language of your choosing.
I have found that [NGINX] seems to perform better throughout the years with less issues although I've used Apache more. I would definitely recommend [NGINX] for any high volume site and I've seen this to usually be the case from most provided web hosts who will pick [NGINX] over alternatives
By using Nginx, we can host multiple web services on a single server, keeping our infrastructure costs lower.
Nginx maintains our HTTPS connections, allowing us to keep our promise to our customers that their data is safe in transit.
Due to Nginx's extremely low failure rate, our web addresses always return something meaningful, even when individual services go down. In sense, this means we are "always online" and allows us to maintain brand and support our customers even in the face of catastrophe.