
What is Crawlable?
Crawlable is a web scraping platform that extracts structured data from URLs. The system analyzes page structures to identify available data fields. Users select specific fields for extraction and receive results in CSV or JSON formats.
The platform automates the scraping pipeline. Upon URL submission, the system identifies repeating patterns and data points such as product names, prices, descriptions, dates, and links. The extraction occurs on cloud infrastructure and handles JavaScript rendering, pagination, and proxy rotation.
Features
- Automated page analysis for data field identification.
- Scheduled extraction at daily, weekly, or custom intervals.
- Webhook integration for automated data delivery.
- Residential proxy support for access management.
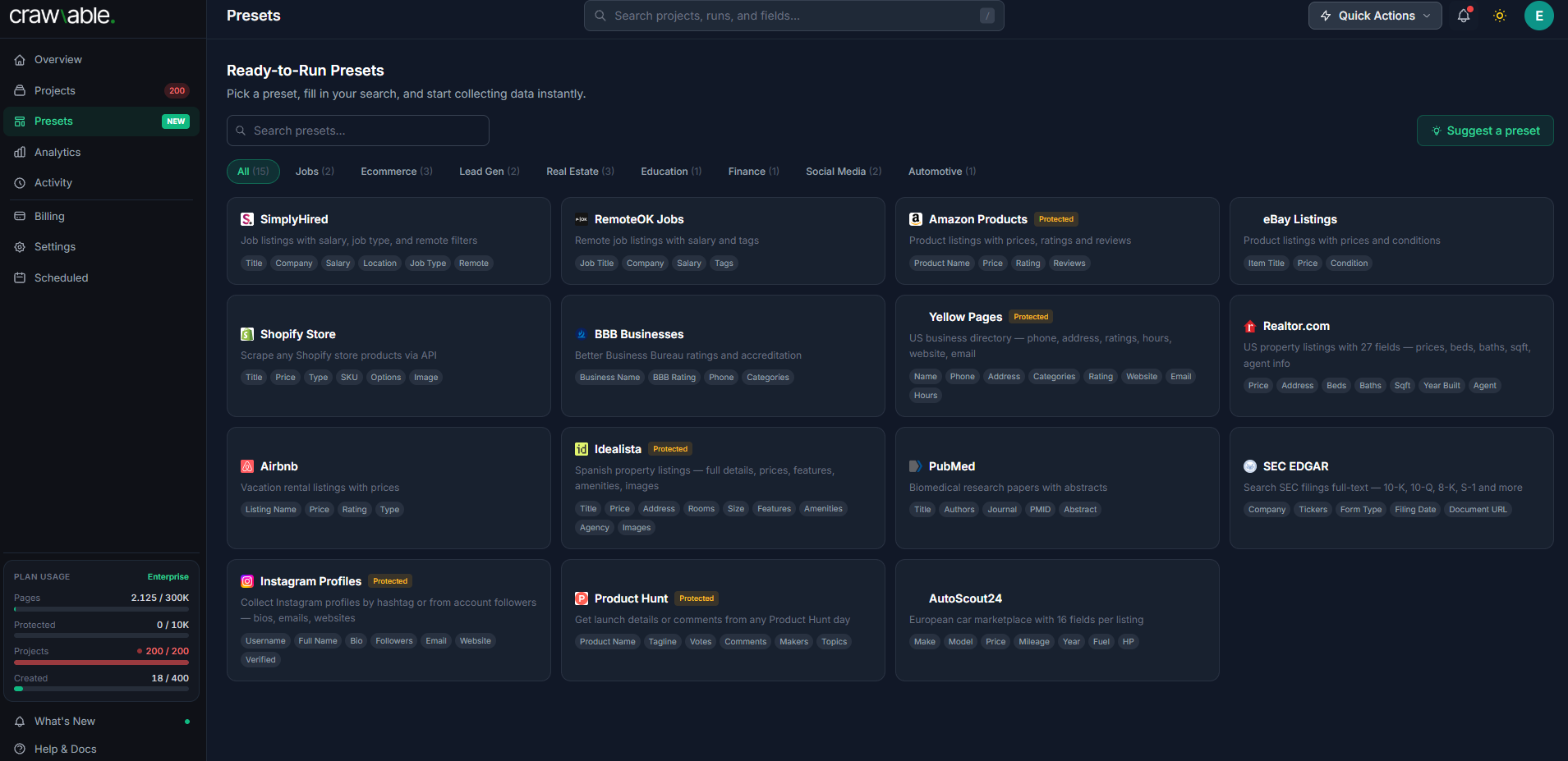
- Pre-configured templates for e-commerce, real estate, and job boards.
- Export options via CSV, JSON, and API.
- Real-time extraction monitoring.
Capabilities
- Automated Field Identification: Uses page analysis to detect extractable data.
- Scheduling: Configurable extraction intervals (daily, weekly, or custom).
- Data Delivery: Webhook integration for automated POSTing of results.
- Access Management: Support for residential proxies and bot-detection bypass.
- Templates: Pre-configured scrapers for e-commerce, real estate, and job listings.
- Export Options: API access, CSV, and JSON formats.
- Monitoring: Real-time visibility into extraction progress.
User Base
The platform is utilized for competitive price monitoring, real estate market analysis, and public directory research. It is used by teams that require web data without manual scripting, as well as technical users seeking to automate scraper maintenance.
Differentiation
Unlike tools requiring manual Python scripts or CSS selector configuration, Crawlable uses automated analysis and code generation. Users define extraction requirements through a visual interface for field selection rather than manual code or API configuration.
Categories & Use Cases
Media

1 / 2


