Apache Kafka is an open-source stream processing platform developed by the Apache Software Foundation written in Scala and Java. The Kafka event streaming platform is used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
N/A
MongoDB
Score 8.9 out of 10
N/A
MongoDB is an open source document-oriented database system. It is part of the NoSQL family of database systems. Instead of storing data in tables as is done in a "classical" relational database, MongoDB stores structured data as JSON-like documents with dynamic schemas (MongoDB calls the format BSON), making the integration of data in certain types of applications easier and faster.
$0.10
million reads
Pricing
Apache Cassandra
Apache Kafka
MongoDB
Editions & Modules
No answers on this topic
No answers on this topic
Shared
$0
per month
Serverless
$0.10million reads
million reads
Dedicated
$57
per month
Offerings
Pricing Offerings
Cassandra
Apache Kafka
MongoDB
Free Trial
No
No
Yes
Free/Freemium Version
No
No
Yes
Premium Consulting/Integration Services
No
No
No
Entry-level Setup Fee
No setup fee
No setup fee
No setup fee
Additional Details
—
—
Fully managed, global cloud database on AWS, Azure, and GCP
Four years ago, I needed to choose a web-scale database. Having used relational databases for years (PostgreSQL is my favorite), I needed something that could perform well at scale with no downtime. I considered VoltDB for its in-memory speed, but it's limited in scale. I …
Apache Cassandra has the best of both worlds, it is a Java based NoSQL, linearly scalable, best in class
tunable performance across different workloads, fault tolerant, distributed, masterless, time series database. We have used both Apache HBase and MongoDB for some use cases …
We evaluated MongoDB also, but don't like the single point failure possibility. The HBase coupled us too tightly to the Hadoop world while we prefer more technical flexibility. Also HBase is designed for "cold"/old historical data lake use cases and is not typically used for …
Against HBase, writes were faster. Reads not so much. Also ability to store in other formats would be good (such as objects). Compared to aerospike, does not compare. Aerospike blows it out of water.
DynamoDB is good and is also a truly global database as a service on AWS. However, if your organization is not using AWS, then Cassandra will provide a highly scalable and tuneable, consistent database. Cassandra is also fault-tolerant and good for replication across multiple …
Cassandra has its own use case. It performs very well as a data store. Data can be written to it at a high rate. It cannot be compared to traditional RDBMS like Oracle, because they all have their own usage. Even MongoDB, which is somewhat similar, cannot be stacked up against …
Technology selection should be done based on the need and not based on buzz words in the market (google searching). If your data need flat file approach and more searchable based on index and partition keys, then it's better to go for Cassandra. Cassandra is a better choice …
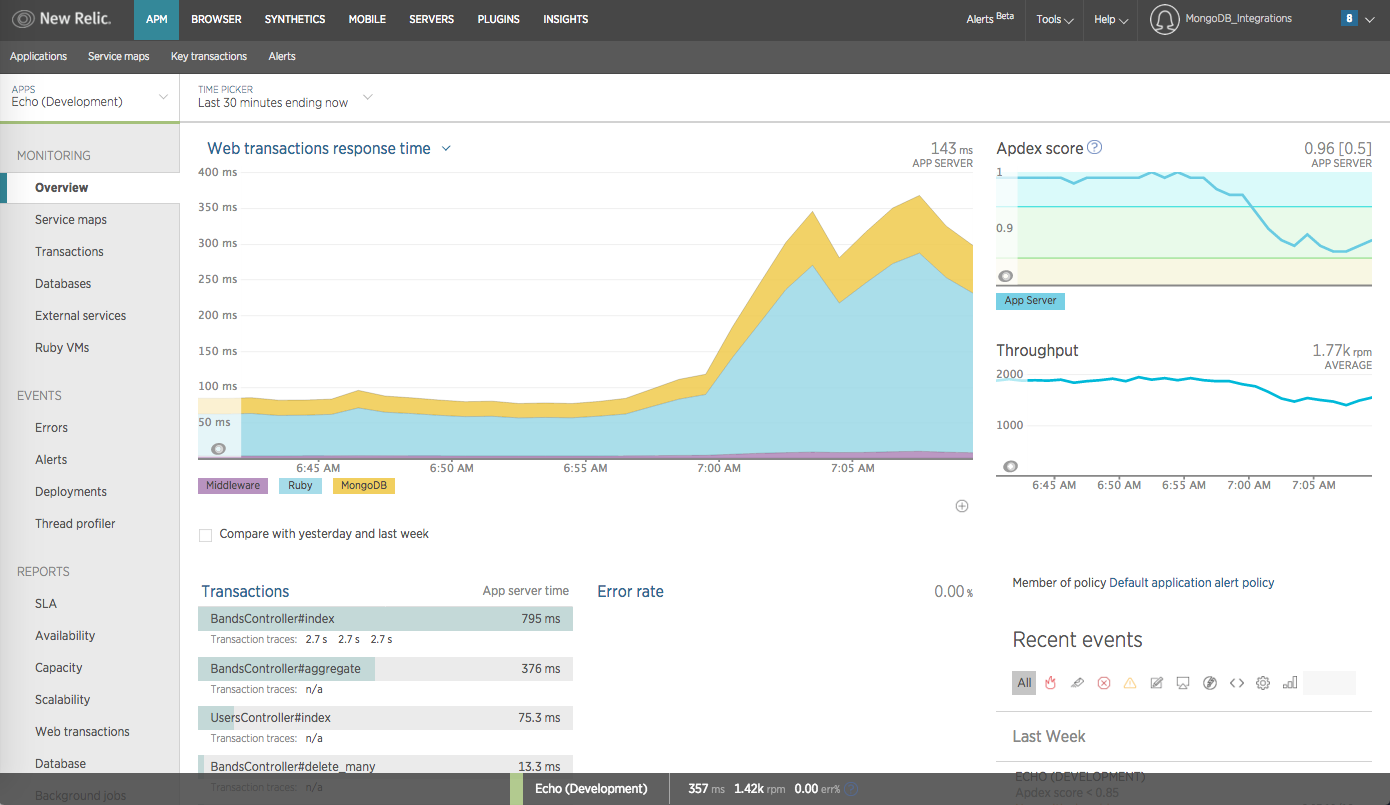
We have [measured] the speed in reading/write operations in high load and finally select the winner = MongoDBWe have [not] too much data but in case there will be 10 [times] more we need Cassandra. Cassandra's storage engine provides constant-time writes no matter how big your …
Verified User
Engineer
Chose MongoDB
I would say Cassandra is better than MongoDB since it has the backing of Facebook to it. Its inherent properties like versioning put it into the other category of columnar databases, but it's one of the NoSQL databases which you should definitely consider for your organization …
MongoDB and Cassandra are both database system from the NoSQL family. MongoDB can be used in lots of use cases while Cassandra has a specific usage. There are some features that MongoDB provides efficiently while Cassandra doesn't and vice-versa. Like, you can update the data …
In the beginning, we considered several products in the market. Since our project was a science and research project, our budget wasn't as big as a commercial project, but still, we wanted the product to be scalable so that we could deal with "smooth transition" from research …
From the beginning, we thought we would have a large volume of data, so MongoDB was a natural choice. Next we started the project and found MongoDB is also developing new features that are more like SQL which was very nice for us. As data volume is growing with time, no need to …
Cassandra: may be better for bigger use cases, in PB range, due to our use cases being slightly smaller, we did not need this, but we highly rely on efficient indexing, and low latency, which seemed to be better based on our testing in Mongodb. Couchbase Server: Document …
MongoDB provides better performance on a big database. If you prefer to define indexes rather than a map/reduce function, MongoDB is good for you. It's quick to start it up and very easy to learn, basically no entry barrier. MongoDB's community is very welcoming.
MongoDB's interface is extremely intuitive and allows [you to] come up from no knowledge to a working deployment with no effort, even without a background in the NoSQL world.
We chose MongoDB because it fit our specific use cases better than the other two NoSQL products that I've identified. There are some use cases where those products would be better. Be sure to use the right tool for the job, for us, it was MongoDB, for you it might not be.
I use Cassandra more often these days for best in class performance, tunable consistency, linear scalability. In similar cases, I have used Apache HBase. But if there is a need for document store, MongoDB is the top choice.
Apache Cassandra is a NoSQL database and well suited where you need highly available, linearly scalable, tunable consistency and high performance across varying workloads. It has worked well for our use cases, and I shared my experiences to use it effectively at the last Cassandra summit! http://bit.ly/1Ok56TK It is a NoSQL database, finally you can tune it to be strongly consistent and successfully use it as such. However those are not usual patterns, as you negotiate on latency. It works well if you require that. If your use case needs strongly consistent environments with semantics of a relational database or if the use case needs a data warehouse, or if you need NoSQL with ACID transactions, Apache Cassandra may not be the optimum choice.
Apache Kafka is well-suited for most data-streaming use cases. Amazon Kinesis and Azure EventHubs, unless you have a specific use case where using those cloud PaAS for your data lakes, once set up well, Apache Kafka will take care of everything else in the background. Azure EventHubs, is good for cross-cloud use cases, and Amazon Kinesis - I have no real-world experience. But I believe it is the same.
If asked by a colleague I would highly recommend MongoDB. MongoDB provides incredible flexibility and is quick and easy to set up. It also provides extensive documentation which is very useful for someone new to the tool. Though I've used it for years and still referenced the docs often. From my experience and the use cases I've worked on, I'd suggest using it anywhere that needs a fast, efficient storage space for non-relational data. If a relational database is needed then another tool would be more apt.
Continuous availability: as a fully distributed database (no master nodes), we can update nodes with rolling restarts and accommodate minor outages without impacting our customer services.
Linear scalability: for every unit of compute that you add, you get an equivalent unit of capacity. The same application can scale from a single developer's laptop to a web-scale service with billions of rows in a table.
Amazing performance: if you design your data model correctly, bearing in mind the queries you need to answer, you can get answers in milliseconds.
Time-series data: Cassandra excels at recording, processing, and retrieving time-series data. It's a simple matter to version everything and simply record what happens, rather than going back and editing things. Then, you can compute things from the recorded history.
Really easy to configure. I've used other message brokers such as RabbitMQ and compared to them, Kafka's configurations are very easy to understand and tweak.
Very scalable: easily configured to run on multiple nodes allowing for ease of parallelism (assuming your queues/topics don't have to be consumed in the exact same order the messages were delivered)
Not exactly a feature, but I trust Kafka will be around for at least another decade because active development has continued to be strong and there's a lot of financial backing from Confluent and LinkedIn, and probably many other companies who are using it (which, anecdotally, is many).
Being a JSON language optimizes the response time of a query, you can directly build a query logic from the same service
You can install a local, database-based environment rather than the non-relational real-time bases such a firebase does not allow, the local environment is paramount since you can work without relying on the internet.
Forming collections in Mango is relatively simple, you do not need to know of query to work with it, since it has a simple graphic environment that allows you to manage databases for those who are not experts in console management.
Cassandra runs on the JVM and therefor may require a lot of GC tuning for read/write intensive applications.
Requires manual periodic maintenance - for example it is recommended to run a cleanup on a regular basis.
There are a lot of knobs and buttons to configure the system. For many cases the default configuration will be sufficient, but if its not - you will need significant ramp up on the inner workings of Cassandra in order to effectively tune it.
Sometimes it becomes difficult to monitor our Kafka deployments. We've been able to overcome it largely using AWS MSK, a managed service for Apache Kafka, but a separate monitoring dashboard would have been great.
Simplify the process for local deployment of Kafka and provide a user interface to get visibility into the different topics and the messages being processed.
Learning curve around creation of broker and topics could be simplified
An aggregate pipeline can be a bit overwhelming as a newcomer.
There's still no real concept of joins with references/foreign keys, although the aggregate framework has a feature that is close.
Database management/dev ops can still be time-consuming if rolling your own deployments. (Thankfully there are plenty of providers like Compose or even MongoDB's own Atlas that helps take care of the nitty-gritty.
I would recommend Cassandra DB to those who know their use case very well, as well as know how they are going to store and retrieve data. If you need a guarantee in data storage and retrieval, and a DB that can be linearly grown by adding nodes across availability zones and regions, then this is the database you should choose.
I am looking forward to increasing our SaaS subscriptions such that I get to experience global replica sets, working in reads from secondaries, and what not. Can't wait to be able to exploit some of the power that the "Big Boys" use MongoDB for.
Apache Kafka is highly recommended to develop loosely coupled, real-time processing applications. Also, Apache Kafka provides property based configuration. Producer, Consumer and broker contain their own separate property file
NoSQL database systems such as MongoDB lack graphical interfaces by default and therefore to improve usability it is necessary to install third-party applications to see more visually the schemas and stored documents. In addition, these tools also allow us to visualize the commands to be executed for each operation.
Support for Apache Kafka (if willing to pay) is available from Confluent that includes the same time that created Kafka at Linkedin so they know this software in and out. Moreover, Apache Kafka is well known and best practices documents and deployment scenarios are easily available for download. For example, from eBay, Linkedin, Uber, and NYTimes.
Finding support from local companies can be difficult. There were times when the local company could not find a solution and we reached a solution by getting support globally. If a good local company is found, it will overcome all your problems with its global support.
While the setup and configuration of MongoDB is pretty straight forward, having a vendor that performs automatic backups and scales the cluster automatically is very convenient. If you do not have a system administrator or DBA familiar with MongoDB on hand, it's a very good idea to use a 3rd party vendor that specializes in MongoDB hosting. The value is very well worth it over hosting it yourself since the cost is often reasonable among providers.
We evaluated MongoDB also, but don't like the single point failure possibility. The HBase coupled us too tightly to the Hadoop world while we prefer more technical flexibility. Also HBase is designed for "cold"/old historical data lake use cases and is not typically used for web and mobile applications due to its performance concern. Cassandra, by contrast, offers the availability and performance necessary for developing highly available applications. Furthermore, the Hadoop technology stack is typically deployed in a single location, while in the big international enterprise context, we demand the feasibility for deployment across countries and continents, hence finally we are favor of Cassandra
I used other messaging/queue solutions that are a lot more basic than Confluent Kafka, as well as another solution that is no longer in the market called Xively, which was bought and "buried" by Google. In comparison, these solutions offer way fewer functionalities and respond to other needs.
We have [measured] the speed in reading/write operations in high load and finally select the winner = MongoDBWe have [not] too much data but in case there will be 10 [times] more we need Cassandra. Cassandra's storage engine provides constant-time writes no matter how big your data set grows. For analytics, MongoDB provides a custom map/reduce implementation; Cassandra provides native Hadoop support.
I have no experience with this but from the blogs and news what I believe is that in businesses where there is high demand for scalability, Cassandra is a good choice to go for.
Since it works on CQL, it is quite familiar with SQL in understanding therefore it does not prevent a new employee to start in learning and having the Cassandra experience at an industrial level.
Positive: Get a quick and reliable pub/sub model implemented - data across components flows easily.
Positive: it's scalable so we can develop small and scale for real-world scenarios
Negative: it's easy to get into a confusing situation if you are not experienced yet or something strange has happened (rare, but it does). Troubleshooting such situations can take time and effort.
Open Source w/ reasonable support costs have a direct, positive impact on the ROI (we moved away from large, monolithic, locked in licensing models)
You do have to balance the necessary level of HA & DR with the number of servers required to scale up and scale out. Servers cost money - so DR & HR doesn't come for free (even though it's built into the architecture of MongoDB