Azure Synapse Analytics is described as the former Azure SQL Data Warehouse, evolved, and as a limitless analytics service that brings together enterprise data warehousing and Big Data analytics. It gives users the freedom to query data using either serverless or provisioned resources, at scale. Azure Synapse brings these two worlds together with a unified experience to ingest, prepare, manage, and serve data for immediate BI and machine learning needs.
$4,700
per month 5000 Synapse Commit Units (SCUs)
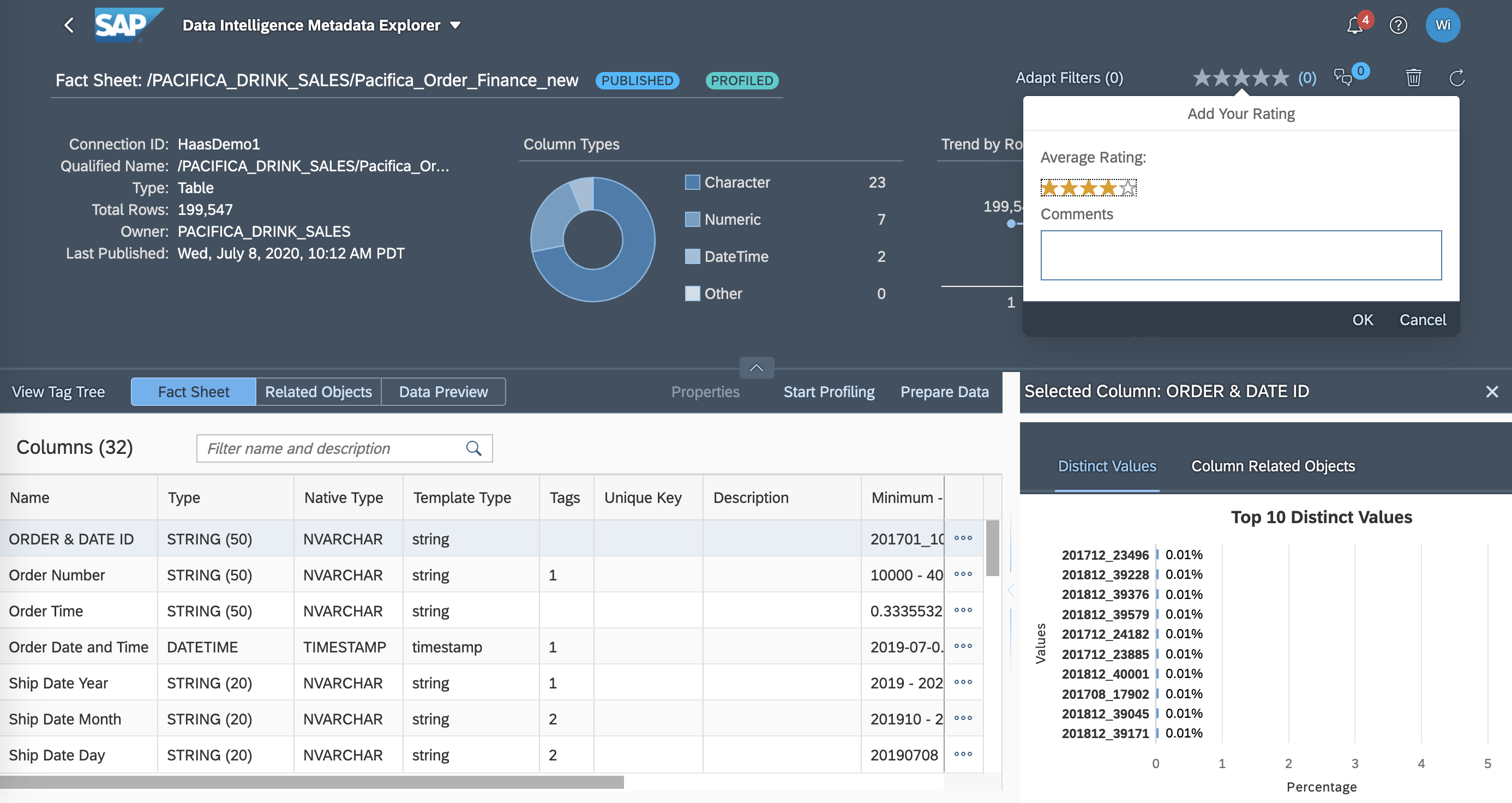
SAP Data Intelligence
Score 8.7 out of 10
N/A
SAP Data Intelligence is presented by the vendor as a single solution to innovate with data. It provides data-driven innovation in the cloud, on premise, and through BYOL deployments. It is described by the vendor as the new evolution of the company's data orchestration and management solution running on Kubernetes, released by SAP in 2017 to deal with big data and complex data orchestration working across distributed landscapes and processing engine.
It's well suited for large, fastly growing, and frequently changing data warehouses (e.g., in startups). It's also suited for companies that want a single, relatively easy-to-use, centralized cloud service for all their data needs. Larger, more structured organizations could still benefit from this service by using Synapse Dedicated SQL Pools, knowing that costs will be much higher than other solutions. I think this product is not suited for smaller, simpler workloads (where an Azure SQL Database and a Data Factory could be enough) or very large scenarios, where it may be better to build custom infrastructure.
If you have an SAP products ecosystem in your IT landscape, it becomes a no-brainer to go ahead with an SAP Data Intelligence product for your data orchestration, data management, and advanced data analytics needs, such as data preparation for your AI/ML processes. It provides a seamless integration with other SAP products.
Quick to return data. Queries in a SQL data warehouse architecture tend to return data much more quickly than a OLTP setup. Especially with columnar indexes.
Ability to manage extremely large SQL tables. Our databases contain billions of records. This would be unwieldy without a proper SQL datawarehouse
Backup and replication. Because we're already using SQL, moving the data to a datawarehouse makes it easier to manage as our users are already familiar with SQL.
With Azure, it's always the same issue, too many moving parts doing similar things with no specialisation. ADF, Fabric Data Factory and Synapse pipeline serve the same purpose. Same goes for Fabric Warehouse and Synapse SQL pools.
Could do better with serverless workloads considering the competition from databricks and its own fabric warehouse
Synapse pipelines is a replica of Azure Data Factory with no tight integration with Synapse and to a surprise, with missing features from ADF. Integration of warehouse can be improved with in environment ETl tools
Data transfer speed tends to be slow when there is poor internet connection since SAP Data Intelligence don’t synchronize data while offline. However, this is not vendor fault, that’s why we have implemented robust wireless technology internet connection in our organization.
Allow collaborations among various personas with insights as ratings and comments on the datasets Reuse knowledges on the datasets for new users Next-Gen Data Management and Artificial Intelligence
The data warehouse portion is very much like old style on-prem SQL server, so most SQL skills one has mastered carry over easily. Azure Data Factory has an easy drag and drop system which allows quick building of pipelines with minimal coding. The Spark portion is the only really complex portion, but if there's an in-house python expert, then the Spark portion is also quiet useable.
I think the troubleshooting process might be streamlined with improved error recording and tracing. A lot of information about issues and how to fix them is hidden away in the Kubernetes pods themselves. I'm not sure whether SAP Data Intelligence can fix this problem it may be connected to Kubernetes's design, in which case fixing it could need modifications inside Kubernetes itself.
Microsoft does its best to support Synapse. More and more articles are being added to the documentation, providing more useful information on best utilizing its features. The examples provided work well for basic knowledge, but more complex examples should be added to further assist in discovering the vast abilities that the system has.
Initially we struggle to get help from SAP but then dedicated Dev angel was assigned to us and that simplify the overall support scenario. There is still room of improvement in documentation around SAP Data intelligence. We struggle a lot to initially understand the feature and required help around performance improvement area,
In comparing Azure Synapse to the Google BigQuery - the biggest highlight that I'd like to bring forward is Azure Synapse SQL leverages a scale-out architecture in order to distribute computational processing of data across multiple nodes whereas Google BigQuery only takes into account computation and storage.
One of the reasons to pick SAP Data Intelligence is the speed and security it provides, in addition to the excellent support it provides. It is also compatible with all popular databases, which is another reason to choose it.
Licensing fees is replaced with Azure subscription fee. No big saving there
More visibility into the Azure usage and cost
It can be used a hot storage and old data can be archived to data lake. Real time data integration is possible via external tables and Microsoft Power BI