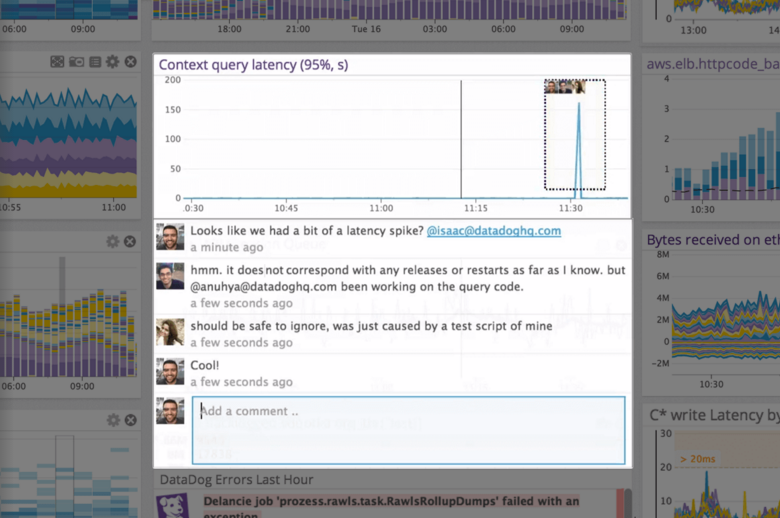
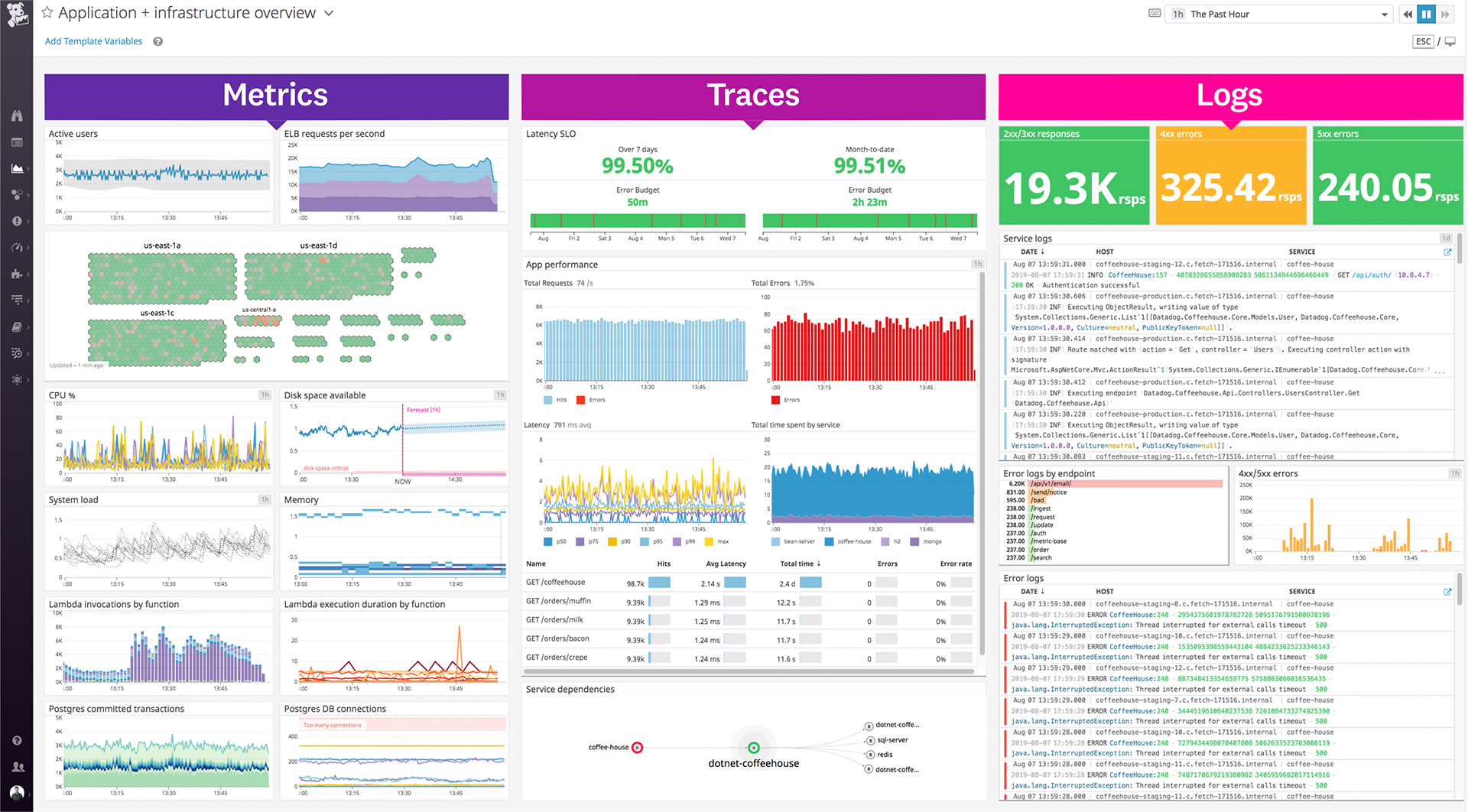
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
Tivoli Monitoring (legacy)
Score 5.1 out of 10
N/A
Tivoli Monitoring products monitor the performance and availability of distributed operating systems and applications. It is a legacy product.
N/A
Pricing
Datadog
Tivoli Monitoring (legacy)
Editions & Modules
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
No answers on this topic
Offerings
Pricing Offerings
Datadog
Tivoli Monitoring (legacy)
Free Trial
Yes
No
Free/Freemium Version
Yes
No
Premium Consulting/Integration Services
No
No
Entry-level Setup Fee
Optional
No setup fee
Additional Details
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
Datadog works really well with complex microservices architecture like any E-commerce platform which will be having multiple services but they all are interdependent to others so in this scenario Datadog will be best to monitor these as it will show the transactions also between those microservices. If you are using multiple services in your architecture whether it will be cloud services or on prem services Datadog will be the best choice to monitor all those service with in Datadog so that you can see everything in a single place. But if you are having small architecture and few services in that then in that scenario you can use Datadog but it will be little costly as compared to other but obviously the features are very well.
If you are looking for a software that looks decent but is not something you truly rely on, this is it. I have had bad experiences with IBM Tivoli Monitoring reporting on system errors that were not evident on the systems themselves at all. There is a lot of specific alerting you can set up which is nice.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
There is some room for improvement, but the Datadog team sends out updates frequently, and the UI is user-friendly for engineers, with no significant loading issues or region-specific problems. That was one of the key reasons we preferred Datadog; our company has employees worldwide, and it wasn't difficult to transition to the tool.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
We are still trying other products, but people still like Datadog. After setting up a dashboard, it's great for monitoring instances on Datadog. Also, the DevOps team had a good time setting up Datadog. It means Datadog was way easier to set up compared to those others.
We selected IBM Tivoli Monitoring as a bundle deal, other than that I would have probably gone with another vendor. We use Brocade Network Advisor for our SAN also which I would suggest to anyone over this software. The software has not been that reliable for me since we started using it.