Apache Drill is a schema-free query engine for use with NoSQL or Hadoop data or file storage systems and databases.
N/A
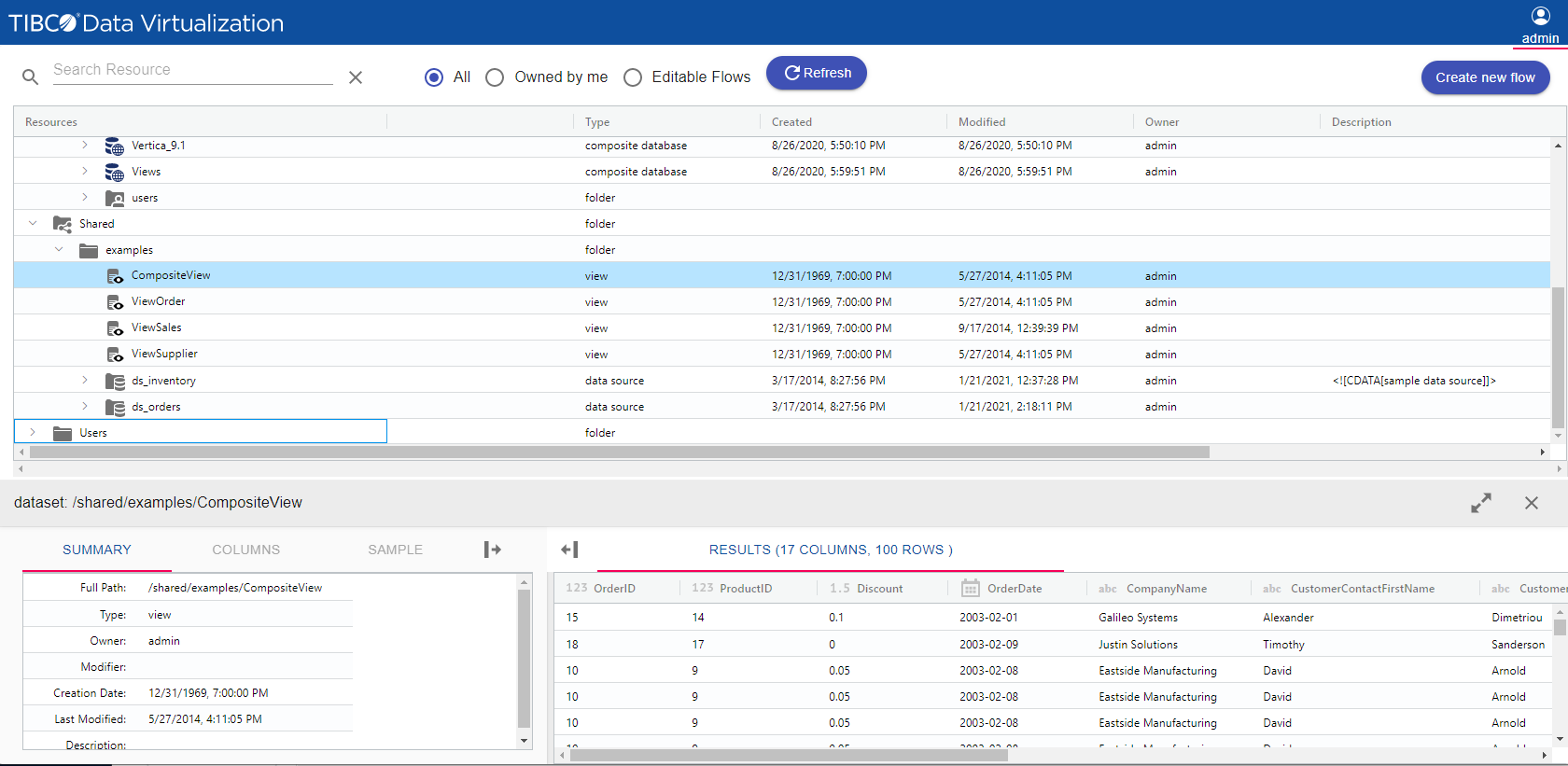
TIBCO Data Virtualization
Score 8.6 out of 10
N/A
TIBCO Data Virtualization is an enterprise data virtualization solution that orchestrates access to multiple and varied data sources and delivers the datasets and IT-curated data services foundation for nearly any solution.
compared to presto, has more support than prestodb. Impala has limitations to what drill can support apache phoenix only supports for hbase. no support for cassandra.
We have used and are still using SQL Server for database technology. TIBCO Data Virtualization apparently reduced development time in ingesting data, but it could not hold strong against SQL server in terms of querying performance.
Have started tinkering with Starburst and it seems to be a good tool, with predictable performance. TIBCO DV would certainly need to up its game wrt the overall design vis-à-vis hardware and its optimization.
Dremio is a newer and more nimble envisioning of TDV and really scales in a more manageable and predictable way. The technology behind dremio addresses many of the limitations in scalability and cost that we encountered with TDV in an impactful way. TDV still has a place for …
TIBCO Data Virtualization is set apart from competition. There are tools that just do not compare in the space of science. It is truly a one of a kind BI tool that is in a league of its own. I will continue to not only use TIBCO Data Virtualization, but I will spread the word …
We evaluated Informatica and Boomi but stuck with TDV because of our relationship with them. We started with Composite, then CDV (Cisco Data Virtualization), and not using TDV.
Tibco is a more mature environment that targets corporate requirements whereas Power BI has many built-for-purpose use cases at a department, division, or team level and Tableau is more geared toward custom visual development.
Since TIBCO Data Virtualization can be implemented with wide range of products with other TIBCO Products so this makes TIBCO stand out from other products.
Tableau Desktop is a tool that is used to visualize data from different data sources and develop dashboards that can be published on various platforms. Here integration is not required and data can be directly attached. In tableau data mapping cannot be done where as TIBCO Data …
1. We have evaluated the Denedo data virtualization tool, which uses the same concept of TIBCO Data Virtualization, but it lags in Custom adaptor supports and the availability of adaptors 2. As TIBCO Data Virtualization is a pioneer in data virtualization, so TIBCO Data …
We did not need to evaluate another technology in the same category for data virtualization, since we are 100% sure of the capabilities and benefits that we would have with TIBCO Data Virtualization, both for market positioning as well as success stories from other companies. …
In the retail industry, you want to penetrate more and more market areas and increase your company's market share compared to other competitors. For more penetration, one needs to increase CSL( Customer service Level). For this company need to analyse what they are currently …
I was not involved in the purchasing decision of TIBCO Data Virtualization. TIBCO Data Virtualization does provide us with a good reporting tool that can access various data sources in order to review the analytics and make future decisions. It can be used on-premise or in …
When we evaluated the pros and cons of each of the competitor applications, what we found is that the pros in Tibco outweigh the cons by a decent margin. Tibco gave us great confidence when we evaluated it in terms of its ability to connect with all the data sources we had in …
Both products are comparable and we use them for different departments and data. Tibco is better in terms of responsiveness and implementation. The cost of implementation and maintenance is lower also and is easier for our users to use. It is easier for us to maintain in the …
Honestly, we decided to use Microsoft Power BI over TIBCO Data Virtualization for our visualization purpose. TIBCO is up against Power BI by having a long list of different data sources compared to the list of data sources available in Power BI. TIBCO is a good tool but for …
The key decision to select TIBCO over other products was made by the client team in which I did not have any role, however after using the product I can say that the new age of data science calls for a new shift in data visualization tools. The incorporation of AI takes it to …
[TIBCO Data Virtualization] is [has great performance] and [the] overall cost is much reasonable than other competitors. The wide range of services/features make it the perfect solution for our data needs. [TIBCO Data Virtualization] has always met our quality needs.
TIBCO Data Virtualization was more robust with an array of features that other tools did not have. Working with the team was easy and the support was very responsive.
Very versatile and user-friendly software that allows you to deploy results quickly, on the fly even. Data transparency and business efficiency are improved tremendously, without the need for an extensive training program or course. Snowflake, Tableau, and Yellowfin are better …
if you're doing joins from hBASE, hdfs, cassandra and redis, then this works. Using it as a be all end all does not suit it. This is not your straight forward magic software that works for all scenarios. One needs to determine the use case to see if Apache Drill fits the needs. 3/4 of the time, usually it does.
TIBCO Data Virtualization is well suited for customers who are challenged to deal with extracting data from dozens of different sources and systems, and do not have the time and liberty to hire data engineers and/or ETL developers to write dozens or hundreds of complex ETLs. However, there are situations where TIBCO Data Virtualization severely underperforms, and those are where we are dealing with large volumes of data, in tera bytes or peta byte scale system. For example, a messaging queue which sends 200 million messages every hour will choke TIBCO Data Virtualization if the technology is chosen to route the data.
if Presto comes up with more support (ie hbase, s3), then its strongly possible that we'll move from apache drill to prestoDB. However, Apache drill needs more configuration ease, especially when it comes to garbage collection tuning. If apache drill could support also sparkSQL and Flume, then it does change drill into being something more valuable than prestoDB
TDV's interface is a bit dated and not entirely intuitive. Would recommend some UX design review as the interface leaves a bit to be better understood to be used by users without inherent knowledge of Tibco. Overall I'd suggest more improvement here to ensure usability by a lesser tech audience.
This product's performance is very consistent. It is extremely rare for templates to fail. I've been using this software for 5 years and find it to be both simple and powerful. The impact within the company has been very positive as different processes in different areas, such as data analysis, development, and integrations, have been improved, and, best of all, it has not affected the users. Various systems with which it is connected in order to obtain information.
On a few occasions I have asked TIBCO technical support for help because I have adapted perfectly to their tools, but in those few that I have communicated with their technical team I have received personalized, attentive, responsible attention and I am always assisted by an expert staff the topic. A TIBCO technical support technician spent more than an hour helping me to solve a problem in the initial stage of implementation in my department and this is something that I always appreciate.
The training was helpful. I was able to understand how to use TIBCO for the data load process that we implemented and how to perform various troubleshooting steps based on the training I received. The technician was thorough and took the time to answer any questions. Once we were shown how to use TIBCO in the test environment, we were able to configure the production environment ourselves.
Other vendors have clearer, more visual implementation documentation. We also did not have our data architect and and server administrator available full-time for implementation. In the future, we will secure the necessary internal resources.
compared to presto, has more support than prestodb. Impala has limitations to what drill can support apache phoenix only supports for hbase. no support for cassandra. Apache drill was chosen, because of the multiple data stores that it supports htat the other 3 do not support. Presto does not support hbase as of yet. Impala does not support query to cassandra
We did not need to evaluate another technology in the same category for data virtualization, since we are 100% sure of the capabilities and benefits that we would have with TIBCO Data Virtualization, both for market positioning as well as success stories from other companies. great renown worldwide. From the first day of use, it meets our needs to provide the expected solutions.