Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
N/A
Datadog
Score 8.6 out of 10
N/A
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
Logstash
Score 9.0 out of 10
N/A
N/A
N/A
Pricing
Apache Spark
Datadog
Logstash
Editions & Modules
No answers on this topic
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
No answers on this topic
Offerings
Pricing Offerings
Apache Spark
Datadog
Logstash
Free Trial
No
Yes
No
Free/Freemium Version
No
Yes
No
Premium Consulting/Integration Services
No
No
No
Entry-level Setup Fee
No setup fee
Optional
No setup fee
Additional Details
—
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
Logstash can be compared to other ETL frameworks or tools, but it is also complementary to several, for example, Kafka. I would not only suggest using Logstash when the rest of the ELK stack is available, but also for a self-hosted event collection pipeline for various …
Well suited: To most of the local run of datasets and non-prod systems - scalability is not a problem at all. Including data from multiple types of data sources is an added advantage. MLlib is a decently nice built-in library that can be used for most of the ML tasks. Less appropriate: We had to work on a RecSys where the music dataset that we used was around 300+Gb in size. We faced memory-based issues. Few times we also got memory errors. Also the MLlib library does not have support for advanced analytics and deep-learning frameworks support. Understanding the internals of the working of Apache Spark for beginners is highly not possible.
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
Perfect for projects where Elasticsearch makes sense: if you decide to employ ES in a project, then you will almost inevitably use LogStash, and you should anyways. Such projects would include: 1. Data Science (reading, recording or measure web-based Analytics, Metrics) 2. Web Scraping (which was one of our earlier projects involving LogStash) 3. Syslog-ng Management: While I did point out that it can be a bit of an electric boo-ga-loo in finding an errant configuration item, it is still worth it to implement Syslog-ng management via LogStash: being able to fine-tune your log messages and then pipe them to other sources, depending on the data being read in, is incredibly powerful, and I would say is exemplar of what modern Computer Science looks like: Less Specialization in mathematics, and more specialization in storing and recording data (i.e. Less Engineering, and more Design).
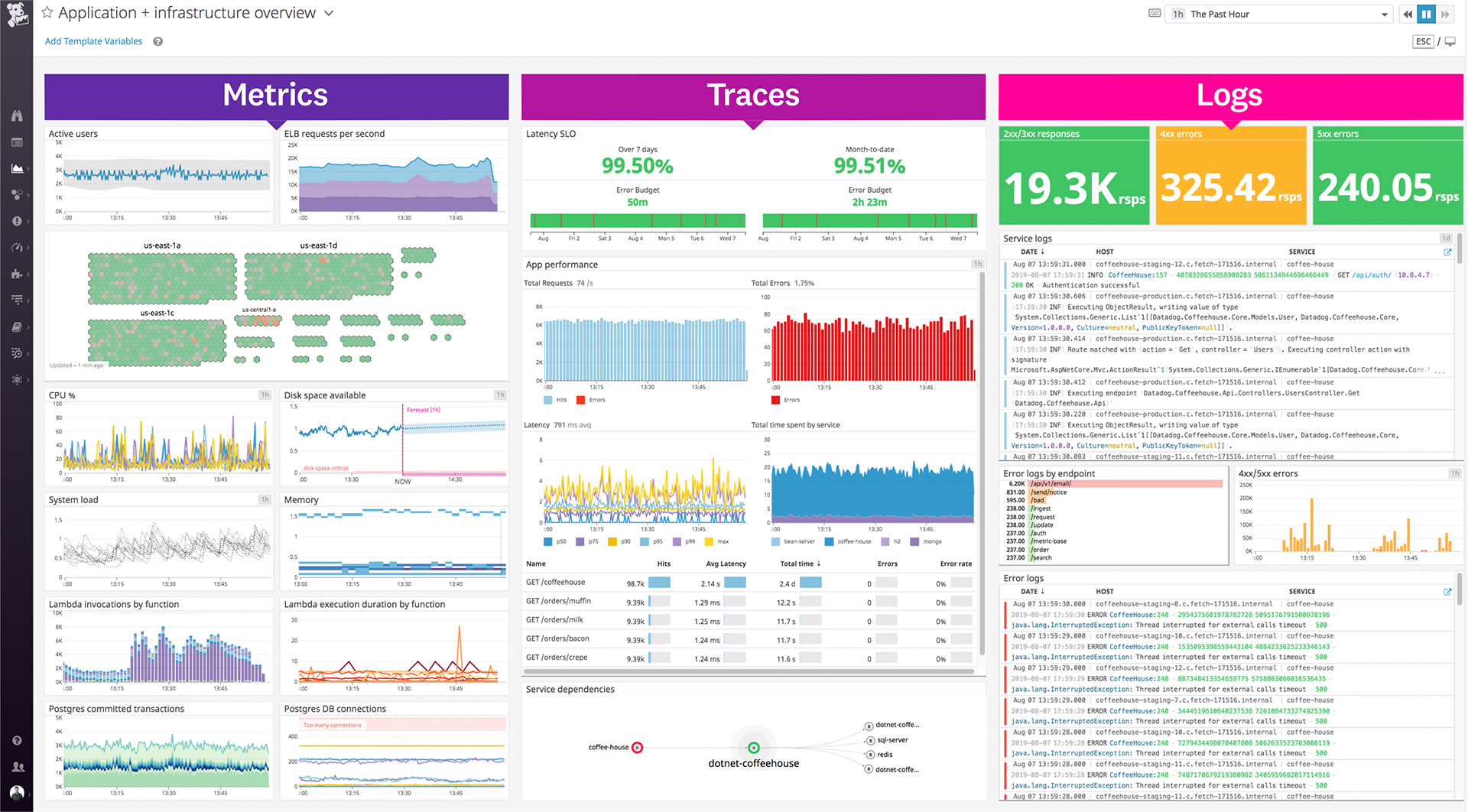
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Logstash design is definitely perfect for the use case of ELK. Logstash has "drivers" using which it can inject from virtually any source. This takes the headache from source to implement those "drivers" to store data to ES.
Logstash is fast, very fast. As per my observance, you don't need more than 1 or 2 servers for even big size projects.
Data in different shape, size, and formats? No worries, Logstash can handle it. It lets you write simple rules to programmatically take decisions real-time on data.
You can change your data on the fly! This is the CORE power of Logstash. The concept is similar to Kafka streams, the difference being the source and destination are application and ES respectively.
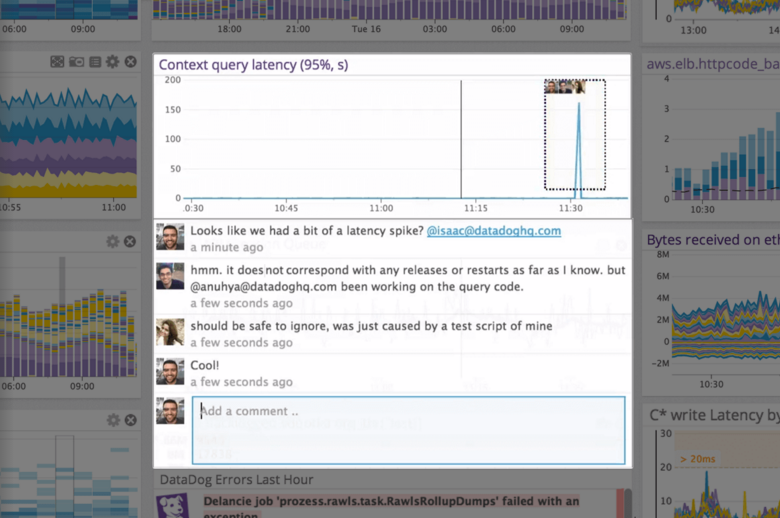
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
If the team looking to use Apache Spark is not used to debug and tweak settings for jobs to ensure maximum optimizations, it can be frustrating. However, the documentation and the support of the community on the internet can help resolve most issues. Moreover, it is highly configurable and it integrates with different tools (eg: it can be used by dbt core), which increase the scenarios where it can be used
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
As I said earlier, for a production-grade OpenStack Telco cloud, Logstash brings high value in flexibility, compliance, and troubleshooting efficiency. However, this brings a higher infra & ops cost on resources, but that is not a problem in big datacenters because there is no resource crunch in terms of servers or CPU/RAM
1. It integrates very well with scala or python. 2. It's very easy to understand SQL interoperability. 3. Apache is way faster than the other competitive technologies. 4. The support from the Apache community is very huge for Spark. 5. Execution times are faster as compared to others. 6. There are a large number of forums available for Apache Spark. 7. The code availability for Apache Spark is simpler and easy to gain access to. 8. Many organizations use Apache Spark, so many solutions are available for existing applications.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
Spark in comparison to similar technologies ends up being a one stop shop. You can achieve so much with this one framework instead of having to stitch and weave multiple technologies from the Hadoop stack, all while getting incredibility performance, minimal boilerplate, and getting the ability to write your application in the language of your choosing.
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
Logstash can be compared to other ETL frameworks or tools, but it is also complementary to several, for example, Kafka. I would not only suggest using Logstash when the rest of the ELK stack is available, but also for a self-hosted event collection pipeline for various searching systems such as Solr or Graylog, or even monitoring solutions built on top of Graphite or OpenTSDB.
Positive: LogStash is OpenSource. While this should not be directly construed as Free, it's a great start towards Free. OpenSource means that while it's free to download, there are no regular patch schedules, no support from a company, no engineer you can get on the phone / email to solve a problem. You are your own Engineer. You are your own Phone Call. You are your own ticketing system.
Negative: Since Logstash's features are so extensive, you will often find yourself saying "I can just solve this problem better going further down / up the Stack!". This is not a BAD quality, necessarily and it really only depends on what Your Project's Aim is.
Positive: LogStash is a dream to configure and run. A few hours of work, and you are on your way to collecting and shipping logs to their required addresses!