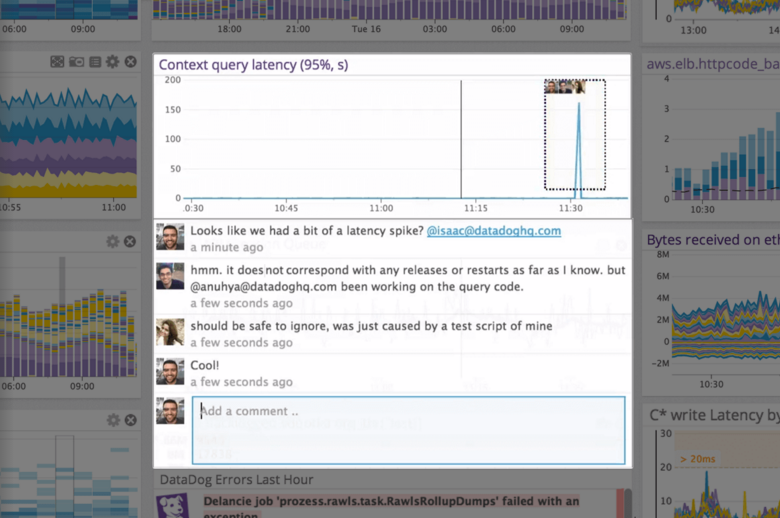
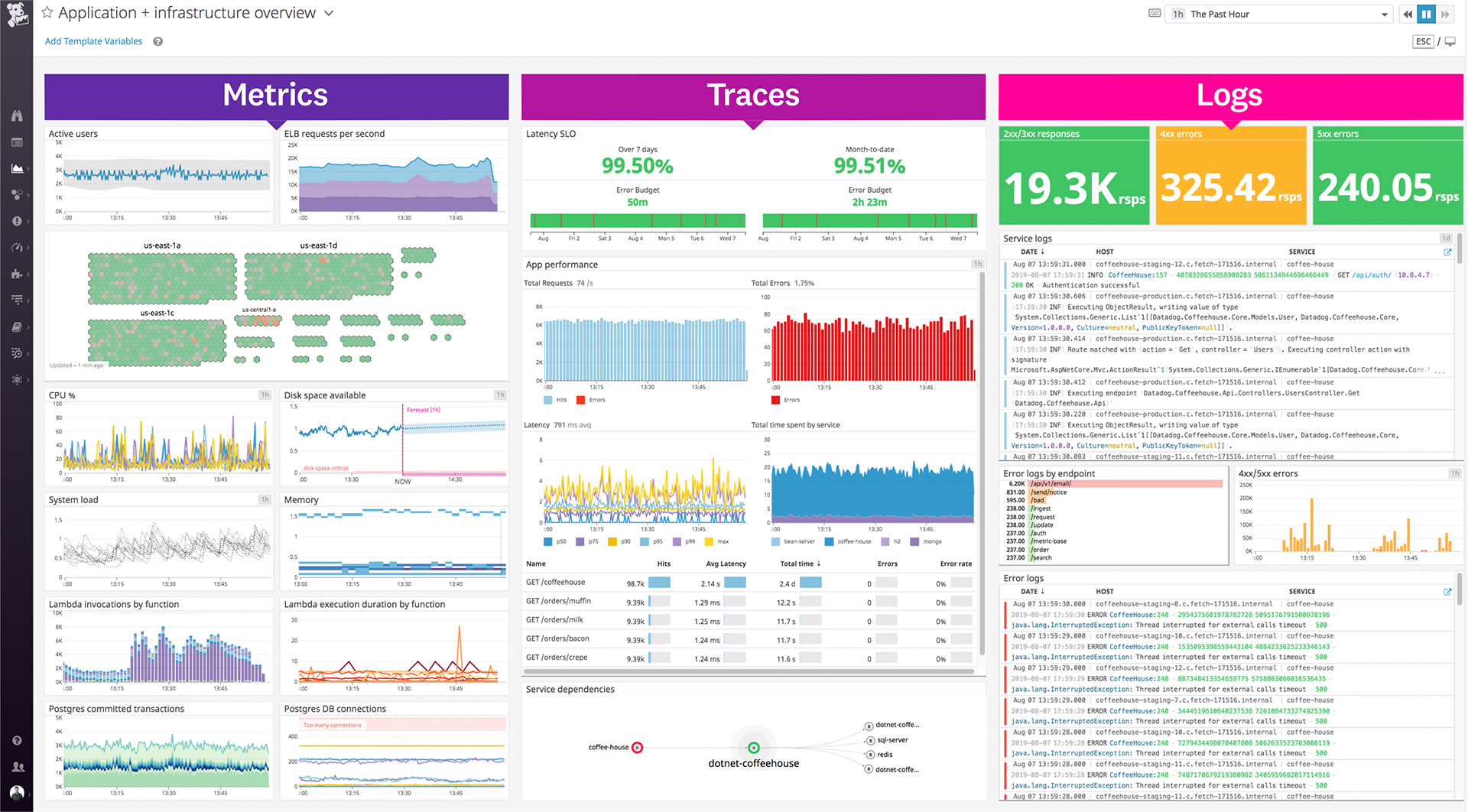
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
SolarWinds Hybrid Cloud Observability
Score 8.5 out of 10
N/A
SolarWinds® Hybrid Cloud Observability aims to provide a comprehensive, integrated, and full-stack solution designed to optimize performance, improve availability, and reduce remediation time by correlating data from across the IT ecosystem, including networks, servers, applications, databases, and more.
$5
per month node
Pricing
Datadog
SolarWinds Hybrid Cloud Observability
Editions & Modules
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
Essentials
$5
per month per node
Advanced
$9
per month per node
Offerings
Pricing Offerings
Datadog
SolarWinds Hybrid Cloud Observability
Free Trial
Yes
Yes
Free/Freemium Version
Yes
No
Premium Consulting/Integration Services
No
Yes
Entry-level Setup Fee
Optional
No setup fee
Additional Details
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
Pricing is set per node, per month, and billing is annual. The prices listed are base prices that could increase depending on your environment. Please speak to a representative to get a quote.
Solarwinds has the best overlap of the two others I've mentioned - the other two tools (Datadog and Dynatrace) are great in their own way but Solarwinds is just good at everything; if I had to pick one tool of the above, it would be Solarwinds for the compatibility and ease of …
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
- For small teams serving big organizations - it's a really simple tool to install and set up relatively quickly. - the new installer is also great - I don't have to understand what modules need to be installed; it's all streamlined. - The HCO Licensing allows you to run the Additional polling engines at a scale where the previous licensing model didn't. We can deploy APEs in locations now, which would not have been worth the investment in previously as there weren't enough devices in that location/region to spend the $$$$ on an APE License.
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
Solarwinds has the best overlap of the two others I've mentioned - the other two tools (Datadog and Dynatrace) are great in their own way but Solarwinds is just good at everything; if I had to pick one tool of the above, it would be Solarwinds for the compatibility and ease of use, the other tools are more focused on being great at certain things while Solarwinds is the jack of all trades.