Chose AWS Glue
We are already in AWS services, so AWS glue is the first choice for us. But for the comparison of ETL job making and process time, it's way faster for other services.
| Product | Rating | Most Used By | Product Summary | Starting Price |
|---|---|---|---|---|
 AWS Glue | N/A | AWS Glue is a managed extract, transform, and load (ETL) service designed to make it easy for customers to prepare and load data for analytics. With it, users can create and run an ETL job in the AWS Management Console. Users point AWS Glue to data stored on AWS, and AWS Glue discovers data and stores the associated metadata (e.g. table definition and schema) in the AWS Glue Data Catalog. Once cataloged, data is immediately searchable, queryable, and available for ETL. | $0.44 billed per second, 1 minute minimum | |
 Azure Data Factory | N/A | Microsoft's Azure Data Factory is a service built for all data integration needs and skill levels. It is designed to allow the user to easily construct ETL and ELT processes code-free within the intuitive visual environment, or write one's own code. Visually integrate data sources using more than 80 natively built and maintenance-free connectors at no added cost. Focus on data—the serverless integration service does the rest. | N/A | |
 Matillion | N/A | Matillion is a data pipeline platform used to build and manage pipelines. Matillion empowers data teams with no-code and AI capabilities to be more productive, integrating data wherever it lives and delivering data that’s ready for AI and analytics. | $2.50 Pay as you go per user |
| AWS Glue | Azure Data Factory | Matillion | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Editions & Modules |
| No answers on this topic |
| |||||||||||||||||||||
| Offerings |
| |||||||||||||||||||||||
| Entry-level Setup Fee | No setup fee | No setup fee | No setup fee | |||||||||||||||||||||
| Additional Details | — | — | Billed directly via cloud marketplace on an hourly basis, with annual subscriptions available depending on the customer's cloud data warehouse provider. | |||||||||||||||||||||
| More Pricing Information | ||||||||||||||||||||||||
| AWS Glue | Azure Data Factory | Matillion | |
|---|---|---|---|
| Considered Multiple Products | AWS Glue | Azure Data Factory  Rajarshi Maitra PMI™- ASM®, ACP® and CAPM® Director/Client Engagement Leader- P&C Insurance (Digital Transformation) Chose Azure Data Factory Azure Data Factory helps us automate to schedule jobs as per customer demands to make ETL triggers when the need arises. Anyone can define the workflow with the Azure Data Factory UI designer tool and easily test the systems. It helped us automate the same workflow with … | Matillion  Adel Helal Tech Lead Engineer Chose Matillion It is much easier to use in terms of GUI capabilities. The only reason we would use an ETL tool other than our own manually written SQL scripts, is to be able to allow other engineers to use it without having one domain expert stuck on the inner working of complex scripts. So …  Andy Lai Techinical Lead Chose Matillion It has a drag-&-drop graphical UI, which makes it easy to connect all the components together. It's very fast to set up from cloud marketplace. It supports many data sources and it also provides a customizable data source component. |
| AWS Glue | Azure Data Factory | Matillion | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Data Source Connection |
| ||||||||||||||||||||||||
| Data Transformations |
| ||||||||||||||||||||||||
| Data Modeling |
| ||||||||||||||||||||||||
| Data Governance |
|
| AWS Glue | Azure Data Factory | Matillion | |
|---|---|---|---|
| Small Businesses |  IBM SPSS Modeler Score 9.2 out of 10 |  Skyvia Score 10.0 out of 10 | Skyvia Score 10.0 out of 10 |
| Medium-sized Companies |  IBM InfoSphere Information Server Score 8.0 out of 10 | IBM InfoSphere Information Server Score 8.0 out of 10 | IBM InfoSphere Information Server Score 8.0 out of 10 |
| Enterprises | IBM InfoSphere Information Server Score 8.0 out of 10 | IBM InfoSphere Information Server Score 8.0 out of 10 | IBM InfoSphere Information Server Score 8.0 out of 10 |
| All Alternatives | View all alternatives | View all alternatives | View all alternatives |
| AWS Glue | Azure Data Factory | Matillion | |
|---|---|---|---|
| Likelihood to Recommend | 8.8 (10 ratings) | 9.0 (7 ratings) | 8.6 (145 ratings) |
| Likelihood to Renew | - (0 ratings) | - (0 ratings) | 8.6 (6 ratings) |
| Usability | 9.2 (3 ratings) | 8.0 (1 ratings) | 8.3 (144 ratings) |
| Support Rating | 7.0 (1 ratings) | 7.0 (1 ratings) | 7.4 (7 ratings) |
| Implementation Rating | - (0 ratings) | - (0 ratings) | 8.2 (1 ratings) |
| Product Scalability | - (0 ratings) | - (0 ratings) | 8.0 (131 ratings) |
| Vendor post-sale | - (0 ratings) | - (0 ratings) | 9.1 (1 ratings) |
| Vendor pre-sale | - (0 ratings) | - (0 ratings) | 9.1 (1 ratings) |
| AWS Glue | Azure Data Factory | Matillion | |
|---|---|---|---|
| Likelihood to Recommend | Amazon AWS
| Microsoft
 Raghuram Subramaniam Solution architect | Matillion
|
| Pros | Amazon AWS
 Apurv Doshi Practice Head - Labs (Innovation and R&D) | Microsoft
 Yoganand Shinde Data & Analytics Architect | Matillion
|
| Cons | Amazon AWS
| Microsoft
| Matillion
|
| Likelihood to Renew | Amazon AWS No answers on this topic | Microsoft No answers on this topic | Matillion
 Sudarshan Kothari Lead Analyst |
| Usability | Amazon AWS
| Microsoft
| Matillion
 Dan Zielinski Senior Database Architect |
| Support Rating | Amazon AWS
| Microsoft
| Matillion
|
| Implementation Rating | Amazon AWS No answers on this topic | Microsoft No answers on this topic | Matillion
Sudarshan Kothari Lead Analyst |
| Alternatives Considered | Amazon AWS
| Microsoft
Rajarshi Maitra Director/Client Engagement Leader- P&C Insurance (Digital Transformation) | Matillion
|
| Scalability | Amazon AWS No answers on this topic | Microsoft No answers on this topic | Matillion
|
| Return on Investment | Amazon AWS
| Microsoft
 Niloofar Keshvari Nia IT Operations and Support Specialist | Matillion
|
| ScreenShots | Matillion Screenshots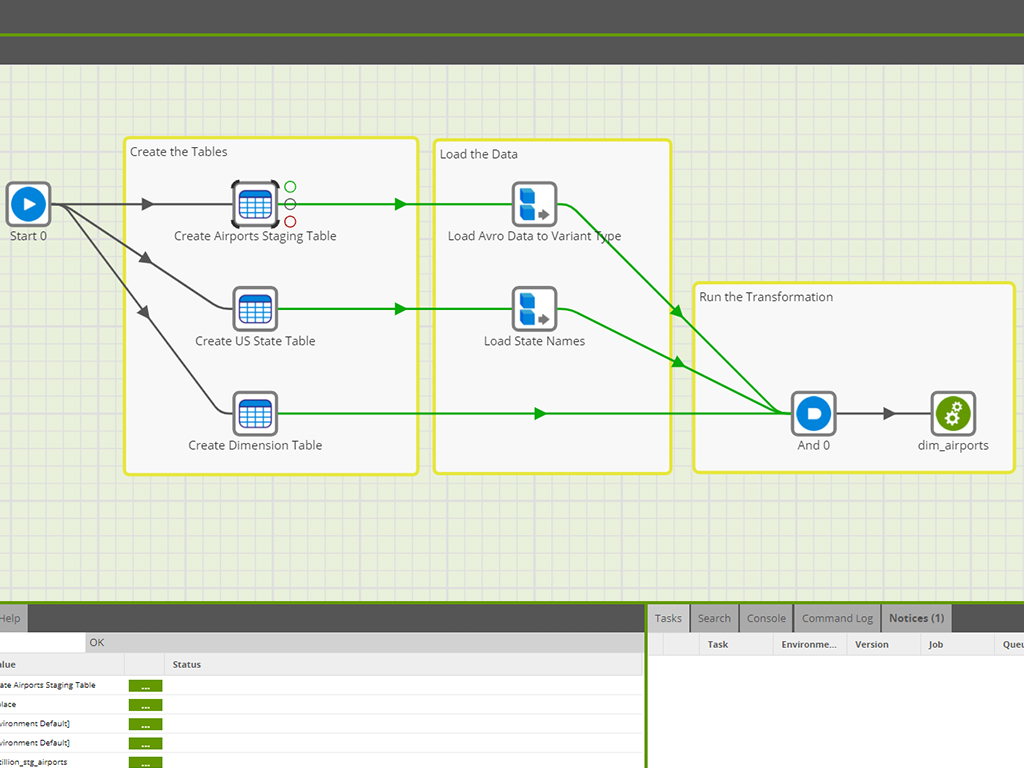 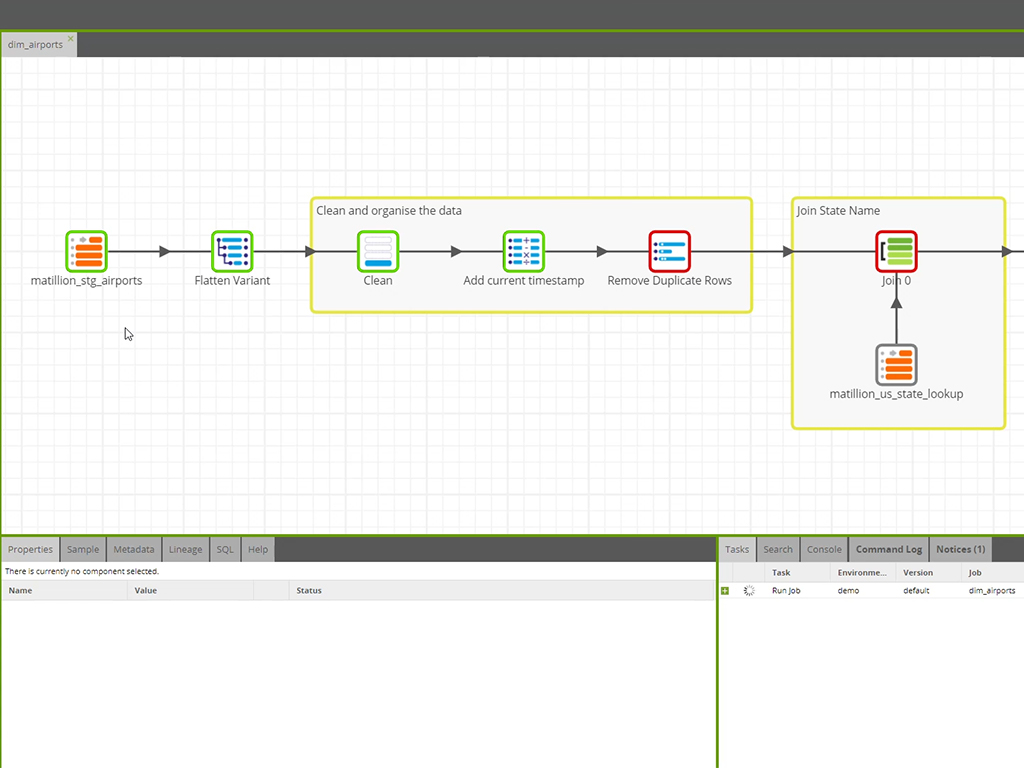  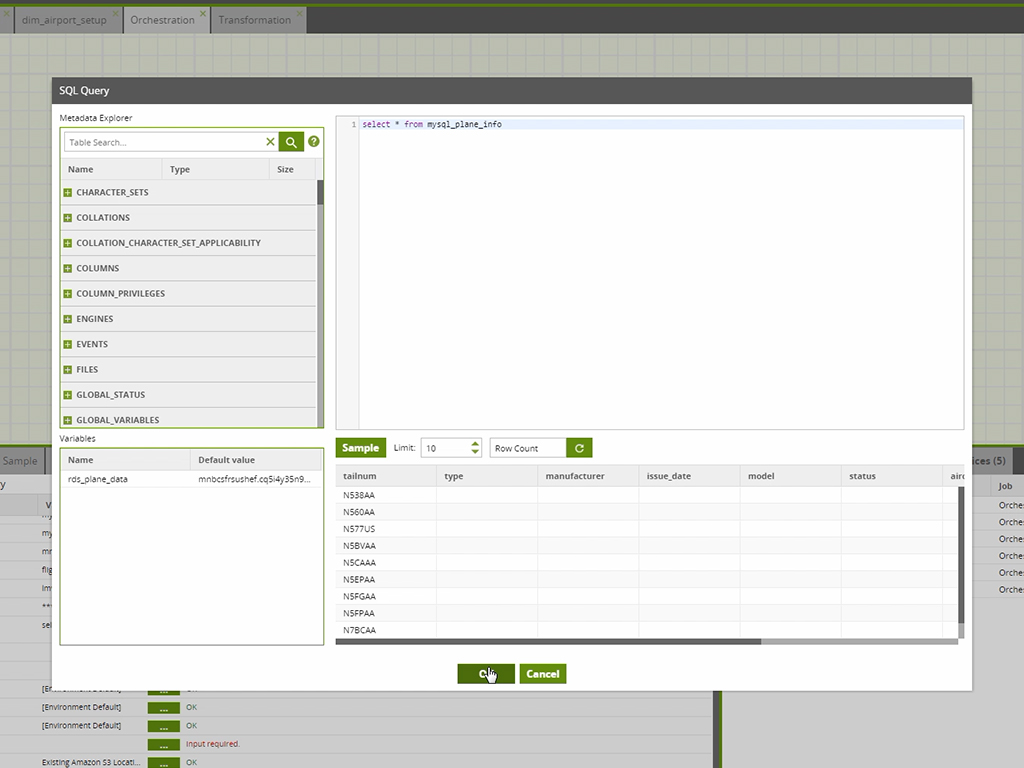 |
