Neo4j is an open source embeddable graph database developed by Neo Technologies based in San Mateo, California with an office in Sweden.
$65
per month
Treasure Data
Score 9.0 out of 10
Mid-Size Companies (51-1,000 employees)
Treasure Data is an enterprise customer data platform (CDP) that reclaims customer-centricity in the age of the digital customer. It does this by connecting all data and uniting teams and systems into one customer data platform to power purposeful engagements.
Neo4J is great for creating network graphs or illustrating how things are related. It is also good for finding individuals or things that have greater influence than others in a system. It is not appropriate if you have standard data sets that can be analyzed using conventional methods or visualized using Tableau, for example.
Treasure Data is well suited to integrating multiple data sources, including online and digital sources. It is also well suited to trigger audience activations to known customers based on their online activity, integrating 3rd party data, and activating target audiences to ad platforms.
Mature Query language, I found Cypher QL to be mature in handling all sorts of problems we throw at it. Its expressive enough to be intuitive while providing rich features for various scenarios.
Native support for REST API, that makes interacting with Neo4J intuitive and easy.
Support for Procedures in Java, procedures are custom code that could be added to the Neo4J to write custom querying of data. The best part about the procedures is it could be invoked using the REST API. This allows us to overcome any shortcomings from their Cypher query language.
Nice UI and interface for executing the Query and visualizing the response.
UI access controlled by User credentials allows for neat access controls.
Awesome free community edition for small-scale projects.
CDP provides a unified view of data from all touchpoints in the customer journey until a single customer uses the service. This feature is very helpful in making service decisions and direction.
It provides a variety of extensions to bring your data together in one place and helps you do this easily.
Kits provided by Treasure Box provide basic but helpful methods for further development of services.
One of the hardest challenges that Neo4j had to solve was the horizontal scaling problem. I am not updated on recent developments, but at the time of my use, I couldn't find a viable solution.
Neo4j does not play with other open source APIs like Blueprint. You have to use the native Neo4j API.
There wasn't a visual tool to see your data. Of course, third party tools are always available, but I would have loved something which came with the Neo4j bundle. I love that Docker comes bundled with Kitematic, so it's not wrong to hope that Neo4j could also ship with some default visualization software.
I do think that we definitely will be renewing. We are putting major resources, time, and effort into Treasure Data becoming an extension of our organization, in many ways. We are working toward complete synergies with this product and leadership is very excited about the direction we are heading to be completely customer-centric.
Learning cypher was super easy coming from a SQL background. Furthermore, the docs Neo4j provides on their website make it really easy to pull up a reference, guide or a quick example. The mac app they provide is also really well designed with good visualisation tools, with the ability to easily use colour, line thickness etc to help navigate your data.
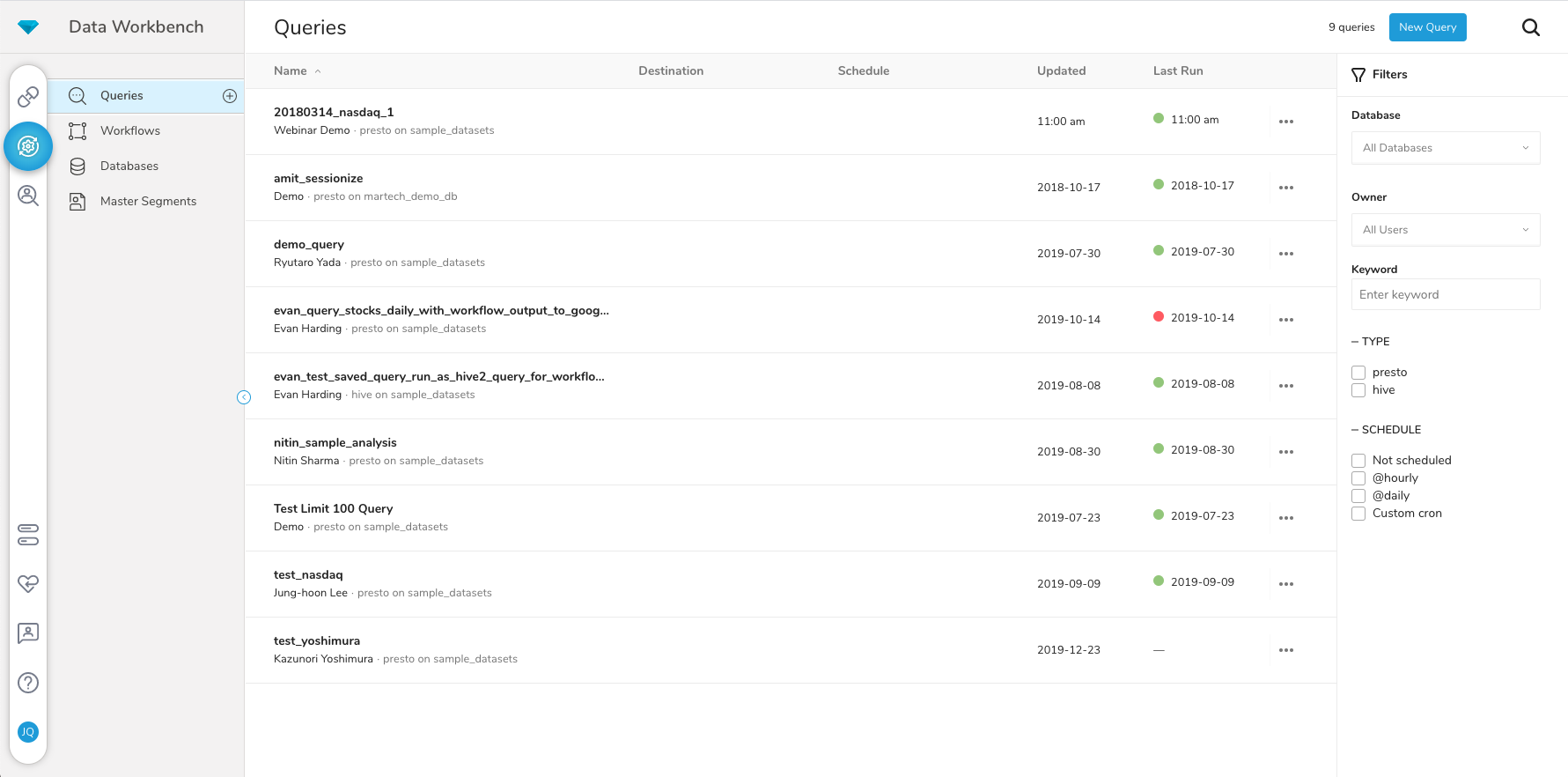
It's a easy platform to use and give the user detailed logs about what is going on in the workflows, so someone that do not have a lot of experience can start to work with it. And also the master segment usability is awesome, as we can filter a lot of data the way we want.
As treasure data has a 24 hours support, every time we has big issues that impacts the zones, we do have immediatly support from the treasure data team, so I would say that we do not have any issues with availability
Since treasure data has started having a huge amount of data, sometimes we do have problems with the workflows logs because we generate a lot of then. But with integrations I have not to complain, its really easy to integrate with other platforms.
The technical team has a good hold on the nuances of the data related to our organization. I have found the online technical support on their site quite responsive including the L1 support. In cases where the L1 team isn't able to resolve, I have found they are prompt in getting the product team's input to get a quick resolution.
I wasnt here at the training in the start, but I had a few training with treasure data for a few functionalities, and they provided me god explanations and great documentations, eve if the project were in beta.
Neo4j is a graph store and has different use cases compared to another NoSQL Document store like MongoDB. MongoDB is a bad choice when joins are common as existing operators for joining two documents (similar to tables in a relational store) as Mongo 3.5 use SQL like join algorithms which are expensive. MongoDB is a great choice when distributed schemaless rich document structures are important requirements. Cross document transaction support is not native to MongoDB yet, whereas Neo4J is ACID complaint with all its operations.
We chose Treasure Data for the supreme customer service and lack of hidden costs. We don't need to manage any infrastructure or scale anything to meet customer demand. Treasure Data handles everything and makes it easy for us to integrate and focus on the tasks at hand. There may be cheaper options but we do not regret our decision to go with Treasure Data one bit.
We have built and supported our source of truth data tables using Treasure. This forms the foundation of our decision making.
Most of our Tableau data sources are created using a Treasure Data export which is executed by workflows on a daily basis which allows us to have visibility into day to day performance and communicate them to a wide variety of roles.
We load custom data into our Salesforce instance which allows us to trigger certain workflows and build accountability - i.e. a "Sale" will only count once a certain product driven event occurs which comes from data we pipe into Treasure and then into Salesforce.