Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
InfluxDB
Score 8.8 out of 10
N/A
The InfluxDB is a time series database from InfluxData headquartered in San Francisco. As an observability solution, it is designed to provide real-time visibility into stacks, sensors and systems. It is available open source, via the Cloud as a DBaaS option, or through an Enterprise subscription.
N/A
Pricing
Apache Cassandra
Datadog
InfluxDB
Editions & Modules
No answers on this topic
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
No answers on this topic
Offerings
Pricing Offerings
Cassandra
Datadog
InfluxDB
Free Trial
No
Yes
No
Free/Freemium Version
No
Yes
No
Premium Consulting/Integration Services
No
No
No
Entry-level Setup Fee
No setup fee
Optional
No setup fee
Additional Details
—
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
Apache Cassandra is a NoSQL database and well suited where you need highly available, linearly scalable, tunable consistency and high performance across varying workloads. It has worked well for our use cases, and I shared my experiences to use it effectively at the last Cassandra summit! http://bit.ly/1Ok56TK It is a NoSQL database, finally you can tune it to be strongly consistent and successfully use it as such. However those are not usual patterns, as you negotiate on latency. It works well if you require that. If your use case needs strongly consistent environments with semantics of a relational database or if the use case needs a data warehouse, or if you need NoSQL with ACID transactions, Apache Cassandra may not be the optimum choice.
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
InfluxDB is very good at storing monitoring metrics (e.g. performance data). InfluxDB is not the right choice if you need to store other data types (like plain text, data relations etc.).
Continuous availability: as a fully distributed database (no master nodes), we can update nodes with rolling restarts and accommodate minor outages without impacting our customer services.
Linear scalability: for every unit of compute that you add, you get an equivalent unit of capacity. The same application can scale from a single developer's laptop to a web-scale service with billions of rows in a table.
Amazing performance: if you design your data model correctly, bearing in mind the queries you need to answer, you can get answers in milliseconds.
Time-series data: Cassandra excels at recording, processing, and retrieving time-series data. It's a simple matter to version everything and simply record what happens, rather than going back and editing things. Then, you can compute things from the recorded history.
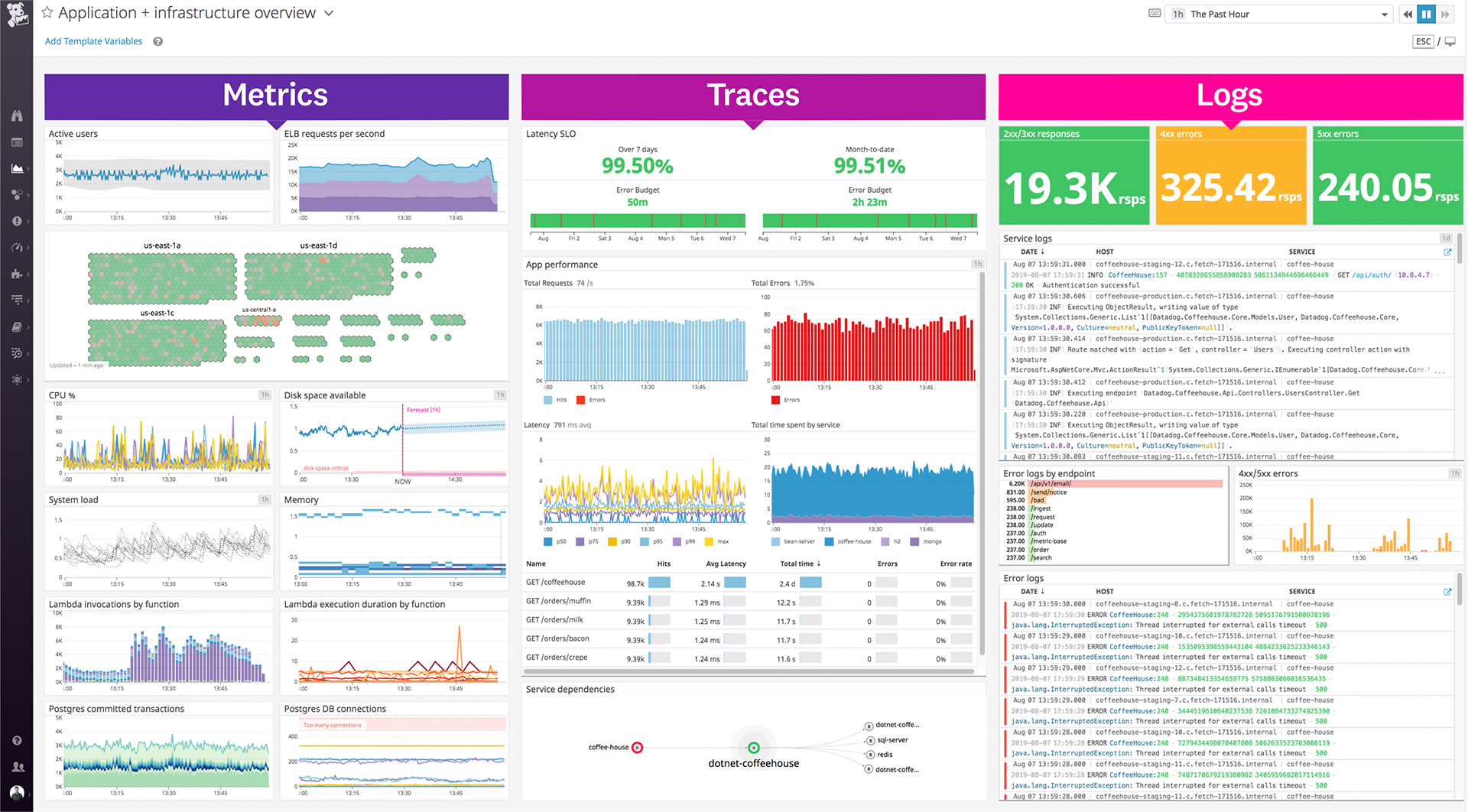
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Cassandra runs on the JVM and therefor may require a lot of GC tuning for read/write intensive applications.
Requires manual periodic maintenance - for example it is recommended to run a cleanup on a regular basis.
There are a lot of knobs and buttons to configure the system. For many cases the default configuration will be sufficient, but if its not - you will need significant ramp up on the inner workings of Cassandra in order to effectively tune it.
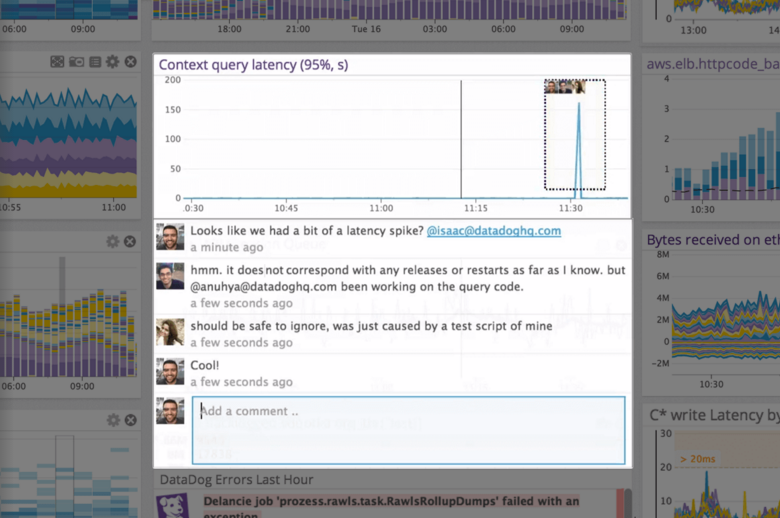
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
I would recommend Cassandra DB to those who know their use case very well, as well as know how they are going to store and retrieve data. If you need a guarantee in data storage and retrieval, and a DB that can be linearly grown by adding nodes across availability zones and regions, then this is the database you should choose.
InfluxDB is a near perfect product for time series database engines. The relatively small list of cons are heavily outweighed by it's ability to just work and be a very flexible and powerful database engine. The community and support provided by the corporation are the only areas I have little experience.
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
We have worked with the InfluxDB support team a few times so far and it has been positive. Issues submitted are worked on promptly and we have good feedback.
We evaluated MongoDB also, but don't like the single point failure possibility. The HBase coupled us too tightly to the Hadoop world while we prefer more technical flexibility. Also HBase is designed for "cold"/old historical data lake use cases and is not typically used for web and mobile applications due to its performance concern. Cassandra, by contrast, offers the availability and performance necessary for developing highly available applications. Furthermore, the Hadoop technology stack is typically deployed in a single location, while in the big international enterprise context, we demand the feasibility for deployment across countries and continents, hence finally we are favor of Cassandra
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
To be honest, I didn't look at alternatives since InfluxDB performs very well if you can oversee the lack of security and HA features. But for all challenges, there is an easy solution which brings you forward (e.g. read load balancing can be achieved by using a common HTTPS load balancer).
I have no experience with this but from the blogs and news what I believe is that in businesses where there is high demand for scalability, Cassandra is a good choice to go for.
Since it works on CQL, it is quite familiar with SQL in understanding therefore it does not prevent a new employee to start in learning and having the Cassandra experience at an industrial level.