Chose ControlUp
In four years of using SysTrack I never once felt like I knew where to go in investigate a problem. ControlUp is much easier to use and provide great information.
| Product | Rating | Most Used By | Product Summary | Starting Price |
|---|---|---|---|---|
 ControlUp | N/A | ControlUp, from the company of the same name headquartered in San Francisco, offers an end user experience monitoring focuses on being able to easily find the root cause of IT issues, remediate directly from its UI vs. having to rely on several tools, and strategically analyze historical resources, usage, and issues data. | N/A | |
 Datadog | N/A | Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight. | $1.27 per month (billed annually) per host |
| ControlUp | Datadog | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Editions & Modules | No answers on this topic |
| ||||||||||||||
| Offerings |
| |||||||||||||||
| Entry-level Setup Fee | No setup fee | Optional | ||||||||||||||
| Additional Details | — | Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo). | ||||||||||||||
| More Pricing Information | ||||||||||||||||
| ControlUp | Datadog | |
|---|---|---|
| Considered Both Products |  ControlUp |  Datadog  Jeffrey van Santen Sr SWE Chose Datadog Datadog is a more complex but complete solution than any of the other Log Aggregation, monitoring, or general observabilty tools that we have trialed. I found it easier to setup following useful and up-to-date documentation provided directly by Datadog instead of scattered …  Vinit Parakh Sr. DevOps Engineer Chose Datadog First think first - it's easy to use, and very easy to implement in any infrastructure. It provides a custom dashboard and monitors. I’ve used or evaluated Grafana, Prometheus, Amazon CloudWatch, and Dynatrace, and each tool has strong capabilities. Prometheus + Grafana provide …  Joe Cardali Head of Engineering Chose Datadog Much more modern and advanced  Fernando Battistella DevOps Engineer Chose Datadog ease of use and implementation, other than new relic (which I think is terrible in every possible way), the other two support opentelemetry better, have more manageable costs and comparable basic services, but they do not have the breadt of services dd does. |
| ControlUp | Datadog | |
|---|---|---|
| Small Businesses |  SolarWinds Pingdom Score 8.2 out of 10 |  Amazon CloudWatch Score 7.7 out of 10 |
| Medium-sized Companies |  Cisco ThousandEyes Score 9.0 out of 10 |  ManageEngine Site24x7 Score 10.0 out of 10 |
| Enterprises |  Nexthink Score 7.4 out of 10 | ManageEngine Site24x7 Score 10.0 out of 10 |
| All Alternatives | View all alternatives | View all alternatives |
| ControlUp | Datadog | |
|---|---|---|
| Likelihood to Recommend | 10.0 (0 ratings) | 8.9 (0 ratings) |
| Likelihood to Renew | - (0 ratings) | 1.0 (0 ratings) |
| Usability | - (0 ratings) | 8.7 (0 ratings) |
| Support Rating | - (0 ratings) | 5.0 (0 ratings) |
| Implementation Rating | - (0 ratings) | 1.0 (0 ratings) |
| ControlUp | Datadog | |
|---|---|---|
| Likelihood to Recommend |
|
|
| Pros |
|
 Aman Makwana DevOps Engineer |
| Cons |
|
|
| Likelihood to Renew | No answers on this topic |
|
| Usability | No answers on this topic |
|
| Support Rating | No answers on this topic |
|
| Implementation Rating | No answers on this topic |
|
| Alternatives Considered |
|
Jeffrey van Santen Sr SWE |
| Return on Investment |
 Praneet Sardi Lead Infrastructure |
|
| ScreenShots | Datadog Screenshots 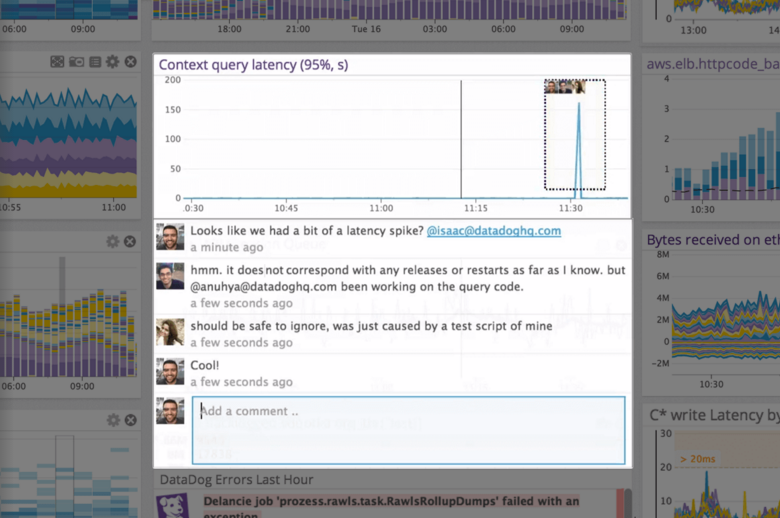 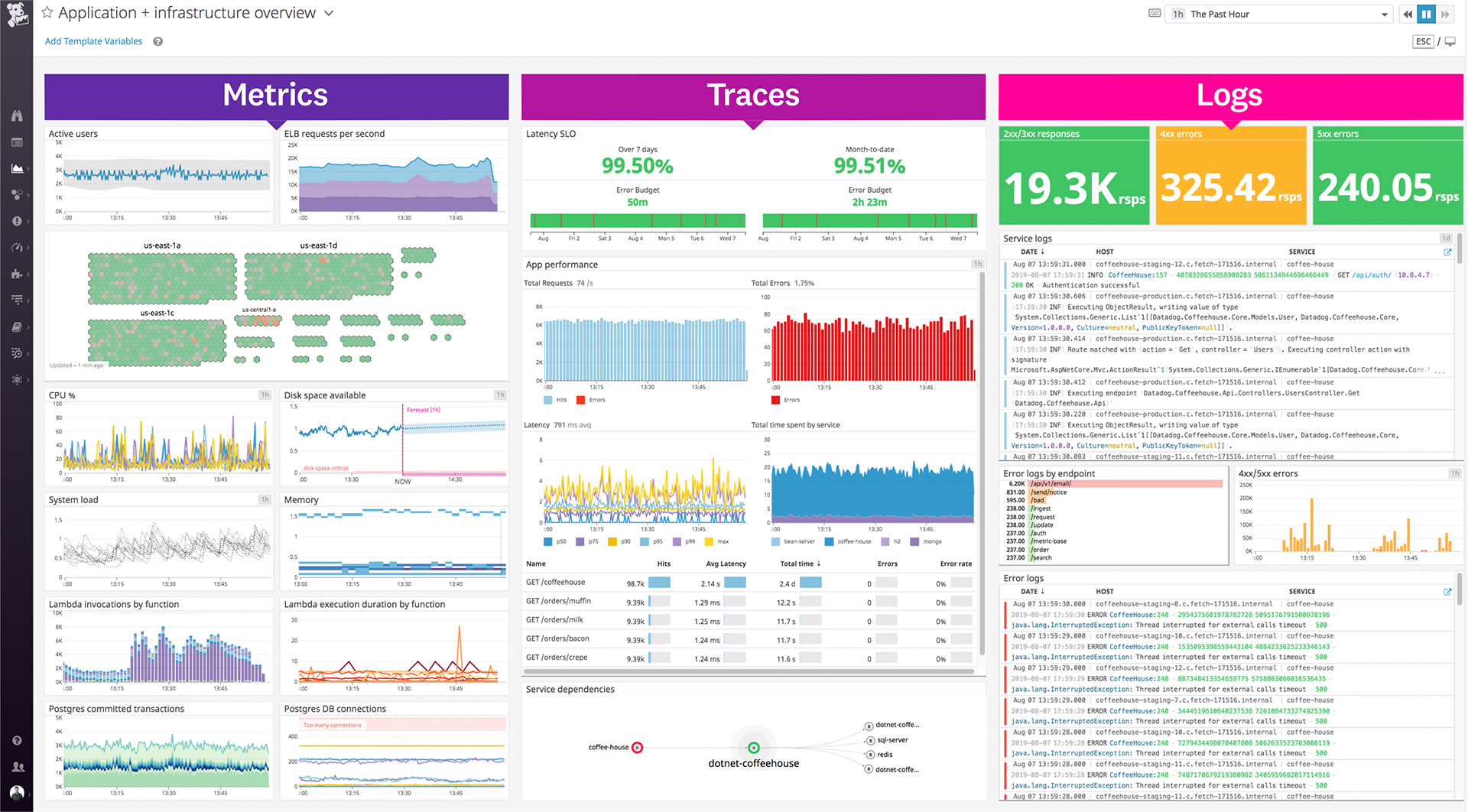    |