Databricks offers the Databricks Lakehouse Platform (formerly the Unified Analytics Platform), a data science platform and Apache Spark cluster manager. The Databricks Unified Data Service provides a platform for data pipelines, data lakes, and data platforms.
$0.07
Per DBU
HPE Data Fabric
Score 9.4 out of 10
N/A
HPE Data Fabric (formerly MapR, acquired by HPE in 2019) is a software-defined datastore and file system that simplifies data management and analytics by unifying data across core, edge, and multicloud sources into a single platform.
N/A
OpenText Magellan
Score 9.0 out of 10
N/A
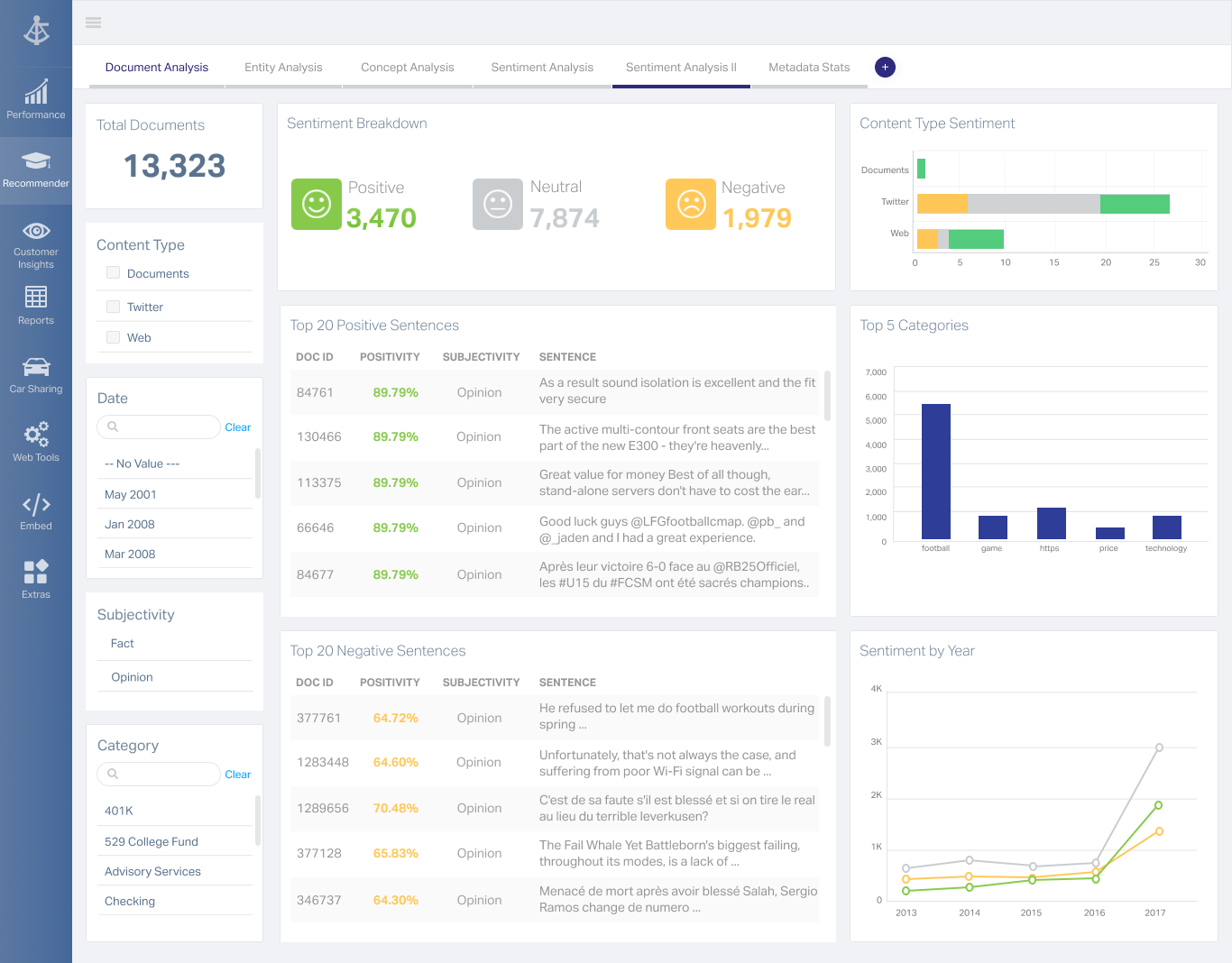
OpenText Magellan Analytics Suite leverages a comprehensive set of data analytics software to identify patterns, relationships and trends through data visualizations and interactive dashboards.
N/A
Pricing
Databricks Data Intelligence Platform
HPE Data Fabric
OpenText Magellan
Editions & Modules
Standard
$0.07
Per DBU
Premium
$0.10
Per DBU
Enterprise
$0.13
Per DBU
No answers on this topic
No answers on this topic
Offerings
Pricing Offerings
Databricks Data Intelligence Platform
HPE Data Fabric
OpenText Magellan
Free Trial
No
No
No
Free/Freemium Version
No
No
No
Premium Consulting/Integration Services
No
No
No
Entry-level Setup Fee
No setup fee
No setup fee
No setup fee
Additional Details
—
—
—
More Pricing Information
Community Pulse
Databricks Data Intelligence Platform
HPE Data Fabric
OpenText Magellan
Features
Databricks Data Intelligence Platform
HPE Data Fabric
OpenText Magellan
BI Standard Reporting
Comparison of BI Standard Reporting features of Product A and Product B
Databricks Data Intelligence Platform
-
Ratings
HPE Data Fabric
-
Ratings
OpenText Magellan
7.0
2 Ratings
16% below category average
Customizable dashboards
00 Ratings
00 Ratings
7.02 Ratings
Report Formatting Templates
00 Ratings
00 Ratings
7.01 Ratings
Ad-hoc Reporting
Comparison of Ad-hoc Reporting features of Product A and Product B
Databricks Data Intelligence Platform
-
Ratings
HPE Data Fabric
-
Ratings
OpenText Magellan
8.3
3 Ratings
3% above category average
Drill-down analysis
00 Ratings
00 Ratings
8.03 Ratings
Formatting capabilities
00 Ratings
00 Ratings
8.03 Ratings
Integration with R or other statistical packages
00 Ratings
00 Ratings
9.01 Ratings
Report sharing and collaboration
00 Ratings
00 Ratings
8.02 Ratings
Report Output and Scheduling
Comparison of Report Output and Scheduling features of Product A and Product B
Databricks Data Intelligence Platform
-
Ratings
HPE Data Fabric
-
Ratings
OpenText Magellan
8.3
2 Ratings
1% above category average
Publish to Web
00 Ratings
00 Ratings
8.02 Ratings
Publish to PDF
00 Ratings
00 Ratings
8.02 Ratings
Report Versioning
00 Ratings
00 Ratings
9.02 Ratings
Report Delivery Scheduling
00 Ratings
00 Ratings
8.02 Ratings
Data Discovery and Visualization
Comparison of Data Discovery and Visualization features of Product A and Product B
Medium to Large data throughput shops will benefit the most from Databricks Spark processing. Smaller use cases may find the barrier to entry a bit too high for casual use cases. Some of the overhead to kicking off a Spark compute job can actually lead to your workloads taking longer, but past a certain point the performance returns cannot be beat.
If you do not have a large budget and are a large organization, I would steer clear of Actuate. If you are looking to do very complex washboarding, I would not use them. Your developers have to be very skilled to work with this. Plan to bring in consultants if necessary to help your process. Adhoc reporting is weak. If your pricing is user based and you expand, this could be very expensive.
MapR had very fast I/O throughput. The write speed was several times faster than what we could achieve with the other Hadoop vendors (Cloudera and Hortonworks). This is because MapR does not use HDFS, which is essentially a "meta filesystem". HDFS is built on top of the filesystem provided by the OS. MapR has their filesystem called MapR-FS, which is a true filesystem and accesses the raw disk drives.
The MapR filesystem is very easy to integrate with other Linux filesystems. When working with HDFS from Apache Hadoop, you usually have to use either the HDFS API or various Hadoop/HDFS command line utilities to interact with HDFS. You cannot use command line utilities native to the host operation system, which is usually Linux. At least, it is not easily done without setting up NFS, gateways, etc. With MapR-FS, you can mount the filesystem within Linux and use the standard Unix commands to manipulate files.
The HBase distribution provided by MapR is very similar to the Apache HBase distribution. Cloudera and Hortonworks add GUIs and other various tools on top of their HBase distributions. The MapR HBase distribution is very similar to the Apache distribution, which is nice if you are more accustomed to using Apache HBase.
I am no longer working for the company that was using Actuate but I believe they would continue to use it because the stitching costs would be to high. It would require a complete rewrite of the reports and the never version of Actuate (BIRT) even required an almost complete report rewrite
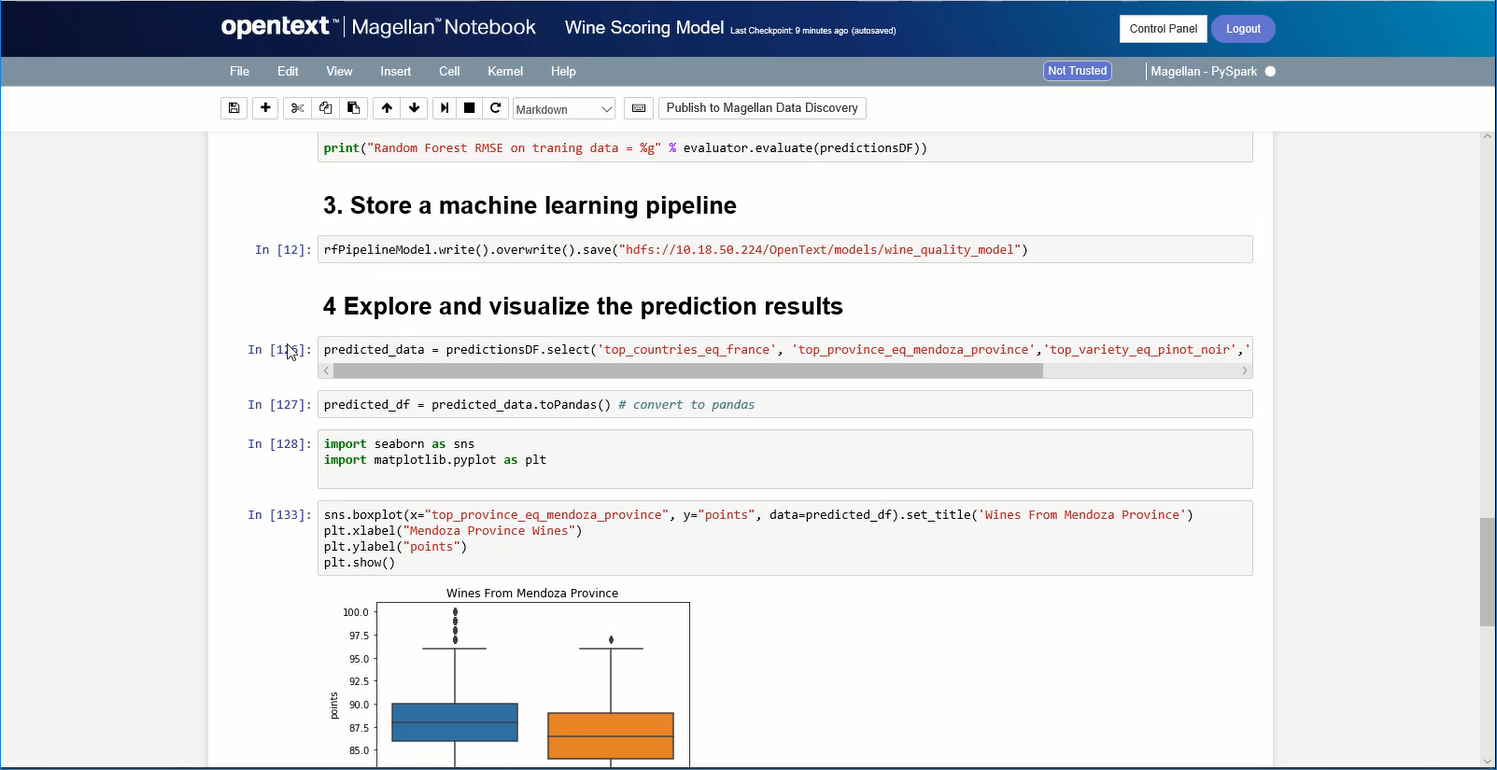
Because it is an amazing platform for designing experiments and delivering a deep dive analysis that requires execution of highly complex queries, as well as it allows to share the information and insights across the company with their shared workspaces, while keeping it secured.
in terms of graph generation and interaction it could improve their UI and UX
It is quite intuitive to use. It is fit specifically for doing sentiment, emotion, and intention analysis as well as text classification and text summarization. I would have given 10 if it is fit for the purpose of doing image processing and analysis as well. There is a huge market to analyze video and image data.
One of the best customer and technology support that I have ever experienced in my career. You pay for what you get and you get the Rolls Royce. It reminds me of the customer support of SAS in the 2000s when the tools were reaching some limits and their engineer wanted to know more about what we were doing, long before "data science" was even a name. Databricks truly embraces the partnership with their customer and help them on any given challenge.
The most important differentiating factor for Databricks Lakehouse Platform from these other platforms is support for ACID transactions and the time travel feature. Also, native integration with managed MLflow is a plus. EMR, Cloudera, and Hortonworks are not as optimized when it comes to Spark Job Execution. Other platforms need to be self-managed, which is another huge hassle.
It is vastly superior to these in many ways, for complex reporting it is a much more sophisticated solution. Visualizations are very good. Javascript extensibility is very powerful, others don't support this or as well. Pentaho and MS are both OLAP oriented. Pentaho is moving more toward big data, which was not our primary focus. Others are stuck in the Crystal Reports Band metaphor.
Increased employee efficiency for sure. Our clients have various levels of expertise in their deployment and user teams, and we never receive complaints about MapR.
MapR is used by one of our financial services clients who uses it for fraud detection and user pattern analysis. They are able to turn around data much faster than they previously had with in-house applications
Actuate can handle 50 to 60 sub reports inside a report very well.
Dynamically creating the datasource, chart, graph, reports are the main advantages. We can do any level of drilling, and can create a performance matrix dashboard efficiently.