Datadog vs. FortiMonitor
Datadog vs. FortiMonitor
| Product | Rating | Most Used By | Product Summary | Starting Price |
|---|---|---|---|---|
 Datadog | N/A | Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight. | $18 per month per host | |
 FortiMonitor | N/A | FortiMonitor is a comprehensive, SaaS-based digital experience monitoring (DEM) platform that helps organizations modernize their performance-monitoring tools. It provides visibility into endpoint application performance and digital experience—no matter where the user resides or where the application is hosted. It is based on Panopta, which was acquired by Fortinet in late 2020. | N/A |
| Datadog | FortiMonitor | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Editions & Modules |
| No answers on this topic | ||||||||||||||
| Offerings |
| |||||||||||||||
| Entry-level Setup Fee | Optional | No setup fee | ||||||||||||||
| Additional Details | Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo). | Our simple, usage-based pricing model is ideal whether you have five servers, or 500 hundred. You’ll be charged monthly per the number of instances monitored, and any additional features you’re using, such as CounterMeasures and synthetic checks. Standard Instances - $6/Instance Network Devices - $9/Device Containers - $2/Container | ||||||||||||||
| More Pricing Information | ||||||||||||||||
| Datadog | FortiMonitor |
|---|
| Datadog | FortiMonitor | |
|---|---|---|
| Likelihood to Recommend | 8.8 (63 ratings) | 8.0 (1 ratings) |
| Likelihood to Renew | 1.0 (1 ratings) | - (0 ratings) |
| Usability | 8.8 (42 ratings) | - (0 ratings) |
| Support Rating | 5.0 (7 ratings) | - (0 ratings) |
| Implementation Rating | 1.0 (1 ratings) | - (0 ratings) |
| Datadog | FortiMonitor | |
|---|---|---|
| Likelihood to Recommend |  Datadog
| Fortinet
 Tomasz Lipinski Director of New Technologies and Development |
| Pros | Datadog
| Fortinet
Tomasz Lipinski Director of New Technologies and Development |
| Cons | Datadog
| Fortinet
Tomasz Lipinski Director of New Technologies and Development |
| Likelihood to Renew | Datadog
| Fortinet No answers on this topic |
| Usability | Datadog
 Jeffrey van Santen Sr SWE | Fortinet No answers on this topic |
| Support Rating | Datadog
| Fortinet No answers on this topic |
| Implementation Rating | Datadog
| Fortinet No answers on this topic |
| Alternatives Considered | Datadog
| Fortinet
Tomasz Lipinski Director of New Technologies and Development |
| Return on Investment | Datadog
| Fortinet
Tomasz Lipinski Director of New Technologies and Development |
| ScreenShots | Datadog Screenshots 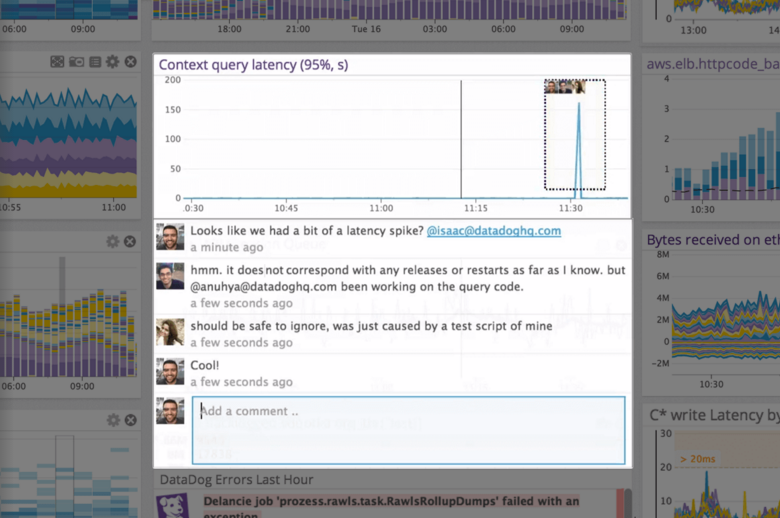 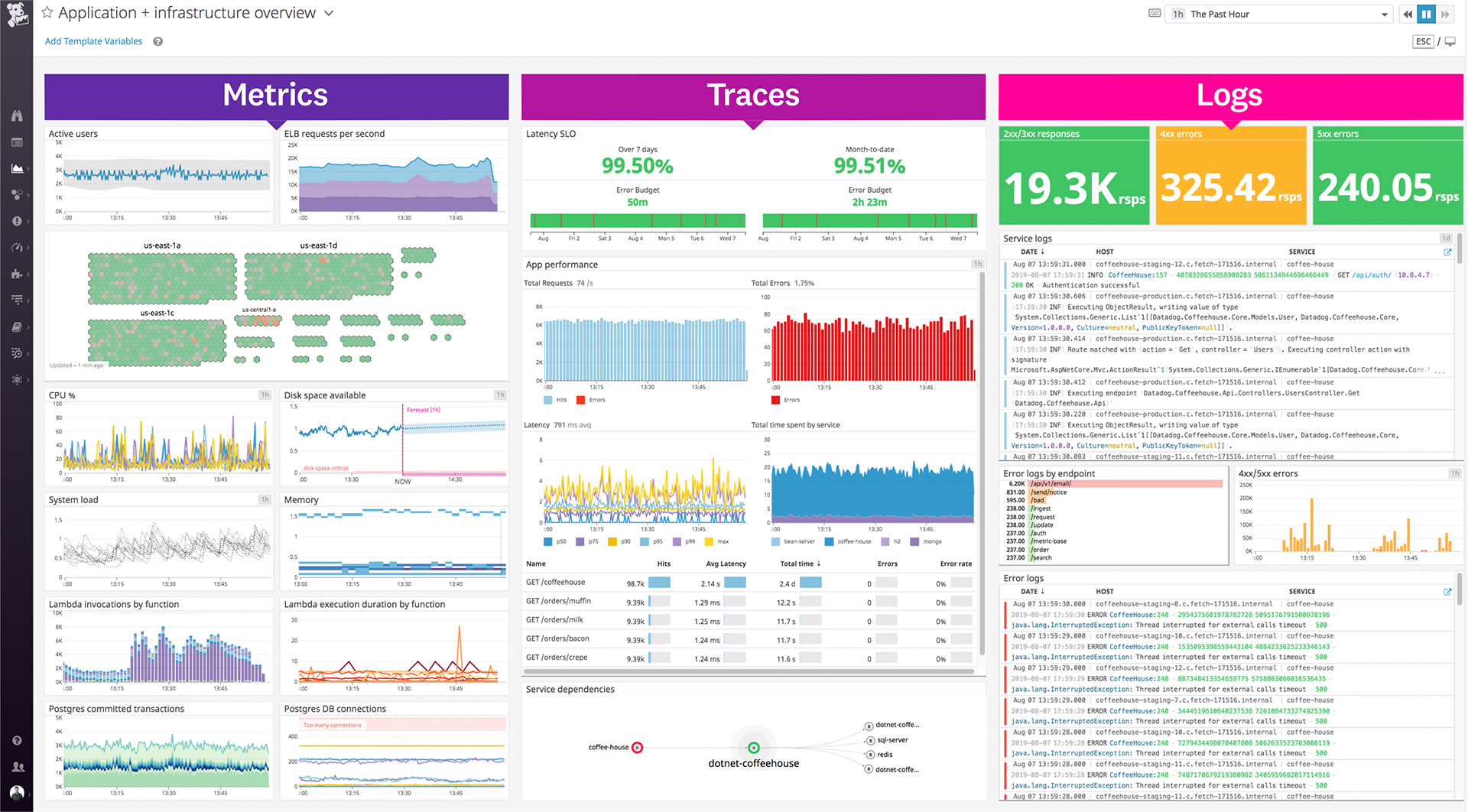    | FortiMonitor Screenshots      |