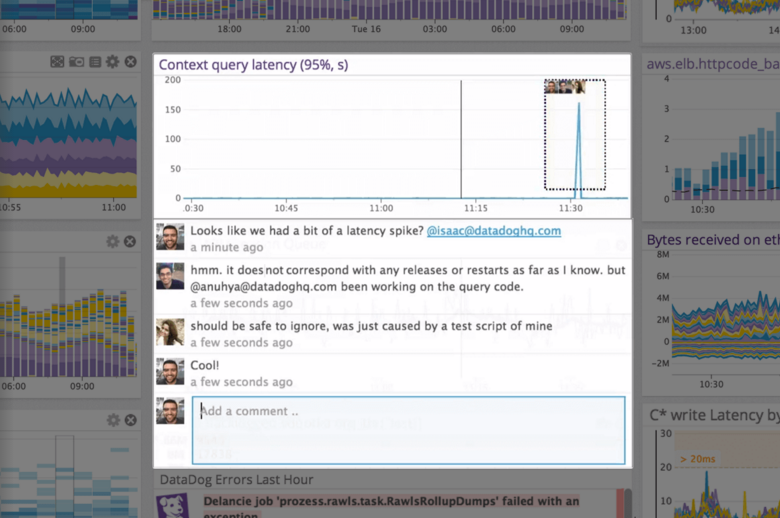
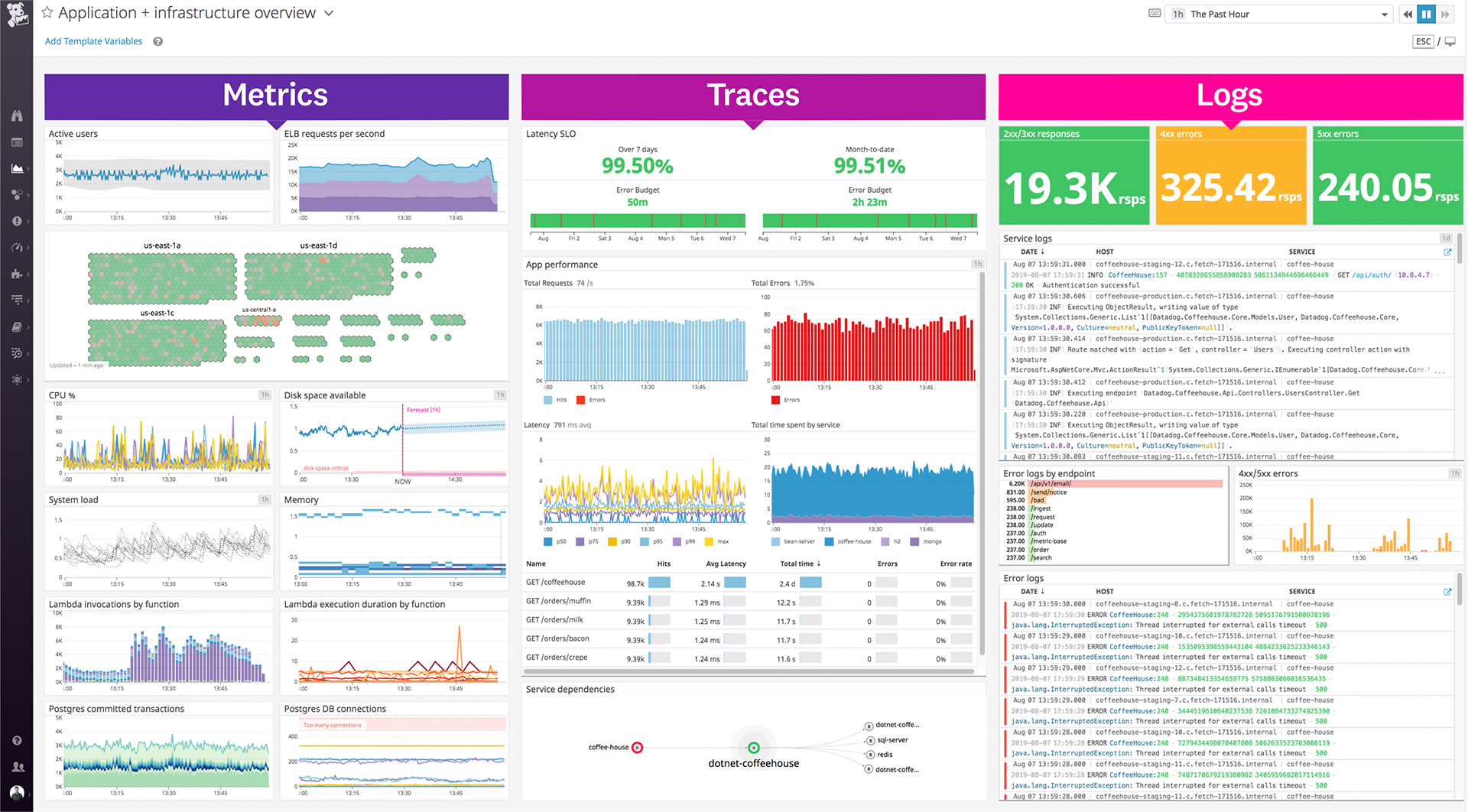
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
Logstash
Score 9.0 out of 10
N/A
N/A
N/A
Nagios Core
Score 7.9 out of 10
N/A
Nagios provides monitoring of all mission-critical infrastructure components. Multiple APIs and community-build add-ons enable integration and monitoring with in-house and third-party applications for optimized scaling.
N/A
Pricing
Datadog
Logstash
Nagios Core
Editions & Modules
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
No answers on this topic
Single License
Free
Single License
Free
Offerings
Pricing Offerings
Datadog
Logstash
Nagios Core
Free Trial
Yes
No
Yes
Free/Freemium Version
Yes
No
Yes
Premium Consulting/Integration Services
No
No
Yes
Entry-level Setup Fee
Optional
No setup fee
No setup fee
Additional Details
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
The first reason for selecting Datadog was of course it's pricing which is quite better in terms of competitor like AppDynamics and splunk. Second thing is versatile services which they are offering on one platform which means entire end to end services can be monitor at one …
Verified User
Director
Chose Datadog
Ultimately, Datadog had the most already-built bridges into our existing infrastructure -- third parties that we're using for certain services are far more likely to work with Datadog than other systems. This means that, while expensive, Datadog has done a tremendous amount of …
I am listing how Datadog is better than below chosen NotSensu - Datadog has more integrations and easy to use UI. Prometheus - Datadog Integration are more in number than, simple installation process
Datadog empowers us to create dashboards and visualize the state of our infrastructure in real time. It gives us control over what we want to view and how. The graphs provide deep insight into trends and anamoly detectives. These features are lacking in some of the other …
Nagios was the best in the past and why I chose it for many of the companies I've worked for. Also, coming in to a company, there is almost always a Nagios server installed and since everyone knows the software it's easy to write plugins for it. But, in 2015, Nagios is a …
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
Perfect for projects where Elasticsearch makes sense: if you decide to employ ES in a project, then you will almost inevitably use LogStash, and you should anyways. Such projects would include: 1. Data Science (reading, recording or measure web-based Analytics, Metrics) 2. Web Scraping (which was one of our earlier projects involving LogStash) 3. Syslog-ng Management: While I did point out that it can be a bit of an electric boo-ga-loo in finding an errant configuration item, it is still worth it to implement Syslog-ng management via LogStash: being able to fine-tune your log messages and then pipe them to other sources, depending on the data being read in, is incredibly powerful, and I would say is exemplar of what modern Computer Science looks like: Less Specialization in mathematics, and more specialization in storing and recording data (i.e. Less Engineering, and more Design).
Nagios monitoring is well suited for any mission critical application that requires per/second (or minute) monitoring. This would probably include even a shuttle launch. As Nagios was built around Linux, most (85%) plugins are Linux based, therefore its more suitable for a Linux environment.
As Nagios (and dependent components) requires complex configurations & compilations, an experienced Linux engineer would be needed to install all relevant components.
Any company that has hundreds (or thousands) of servers & services to monitor would require a stable monitoring solution like Nagios. I have seen Nagios used in extremely mediocre ways, but the core power lies when its fully configured with all remaining open-source components (i.e. MySQL, Grafana, NRDP etc). Nagios in the hands of an experienced Linux engineer can transform the organizations monitoring by taking preventative measures before a disaster strikes.
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Logstash design is definitely perfect for the use case of ELK. Logstash has "drivers" using which it can inject from virtually any source. This takes the headache from source to implement those "drivers" to store data to ES.
Logstash is fast, very fast. As per my observance, you don't need more than 1 or 2 servers for even big size projects.
Data in different shape, size, and formats? No worries, Logstash can handle it. It lets you write simple rules to programmatically take decisions real-time on data.
You can change your data on the fly! This is the CORE power of Logstash. The concept is similar to Kafka streams, the difference being the source and destination are application and ES respectively.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
Nagios could use core improvements in HA, though, Nagios itself recommends monitoring itself with just another Nagios installation, which has worked fine for us. Given its stability, and this work-around, a minor need.
Nagios could also use improvements, feature wise, to the web gui. There is a lot in Nagios XI which I felt were almost excluded intentionally from the core project. Given the core functionality, a minor need. We have moved admin facing alerts to appear as though they originate from a different service to make interacting with alerts more practical.
We're currently looking to combine a bunch of our network montioring solutions into a single platform. Running multiple unique solutions for monitoring, data collection, compliance reporting etc has become a lot to manage.
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
As I said earlier, for a production-grade OpenStack Telco cloud, Logstash brings high value in flexibility, compliance, and troubleshooting efficiency. However, this brings a higher infra & ops cost on resources, but that is not a problem in big datacenters because there is no resource crunch in terms of servers or CPU/RAM
The Nagios UI is in need of a complete overhaul. Nice graphics and trendy fonts are easy on the eyes, but the menu system is dated, the lack of built in graphing support is confusing, and the learning curve for a new user is too steep.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
I haven't had to use support very often, but when I have, it has been effective in helping to accomplish our goals. Since Nagios has been very popular for a long time, there is also a very large user base from which to learn from and help you get your questions answered.
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
Logstash can be compared to other ETL frameworks or tools, but it is also complementary to several, for example, Kafka. I would not only suggest using Logstash when the rest of the ELK stack is available, but also for a self-hosted event collection pipeline for various searching systems such as Solr or Graylog, or even monitoring solutions built on top of Graphite or OpenTSDB.
Because we get all we required in Nagios [Core] and for npm, we have to do lots of configuration as it is not as easy as Comair to Nagios [Core]. On npm UI, there is lots of data, so we are not able to track exact data for analysis, which is why we use Nagios [Core].
Positive: LogStash is OpenSource. While this should not be directly construed as Free, it's a great start towards Free. OpenSource means that while it's free to download, there are no regular patch schedules, no support from a company, no engineer you can get on the phone / email to solve a problem. You are your own Engineer. You are your own Phone Call. You are your own ticketing system.
Negative: Since Logstash's features are so extensive, you will often find yourself saying "I can just solve this problem better going further down / up the Stack!". This is not a BAD quality, necessarily and it really only depends on what Your Project's Aim is.
Positive: LogStash is a dream to configure and run. A few hours of work, and you are on your way to collecting and shipping logs to their required addresses!
With it being a free tool, there is no cost associated with it, so it's very valuable to an organization to get something that is so great and widely used for free.
You can set up as many alerts as you want without incurring any fees.