The vendor states that Informatica Data Quality empowers companies to take a holistic approach to managing data quality across the entire organization, and that with Informatica Data Quality, users are able to ensure the success of data-driven digital transformation initiatives and projects across users, types, and scale, while also automating mission-critical tasks.
N/A
Matillion
Score 8.5 out of 10
N/A
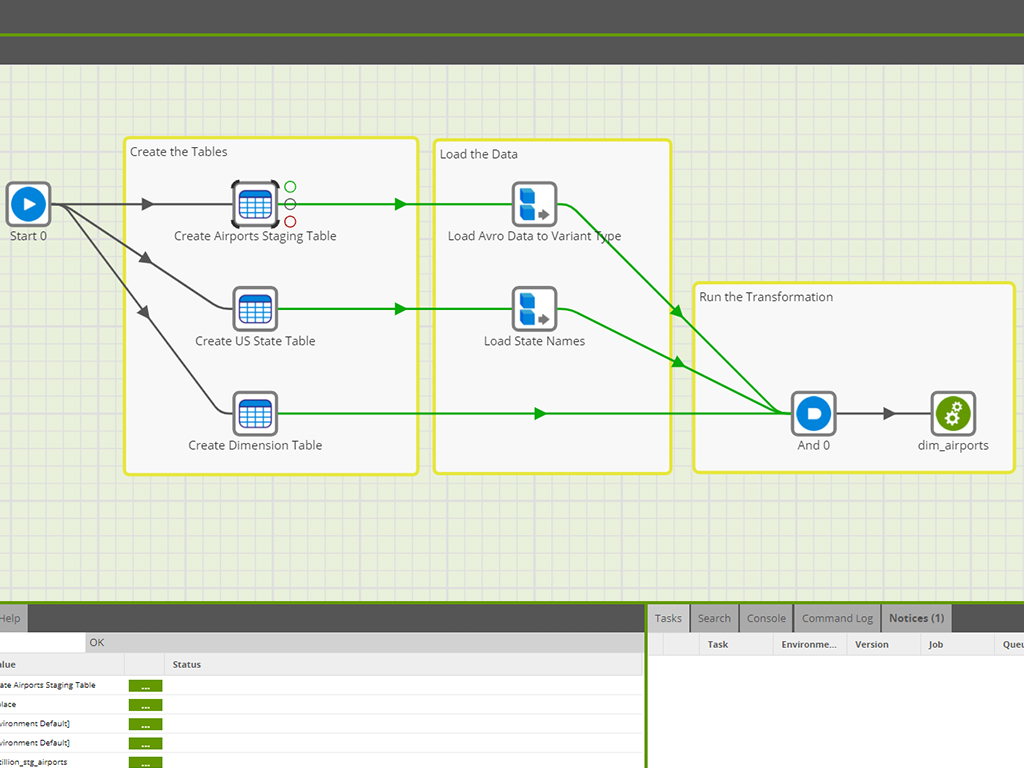
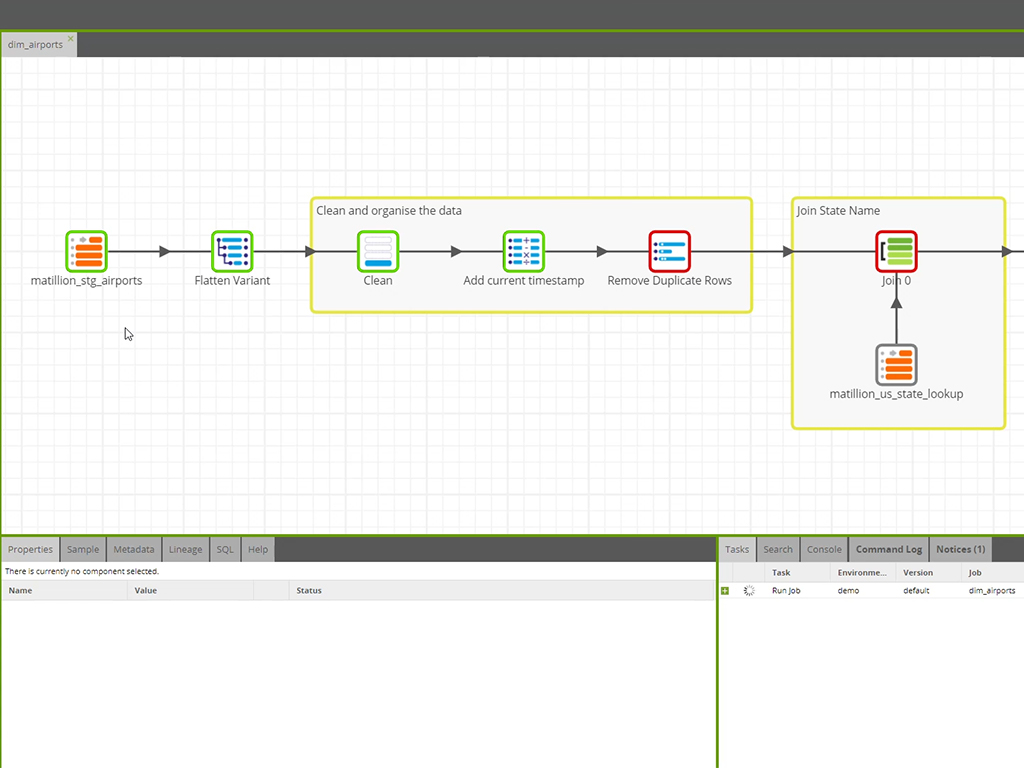
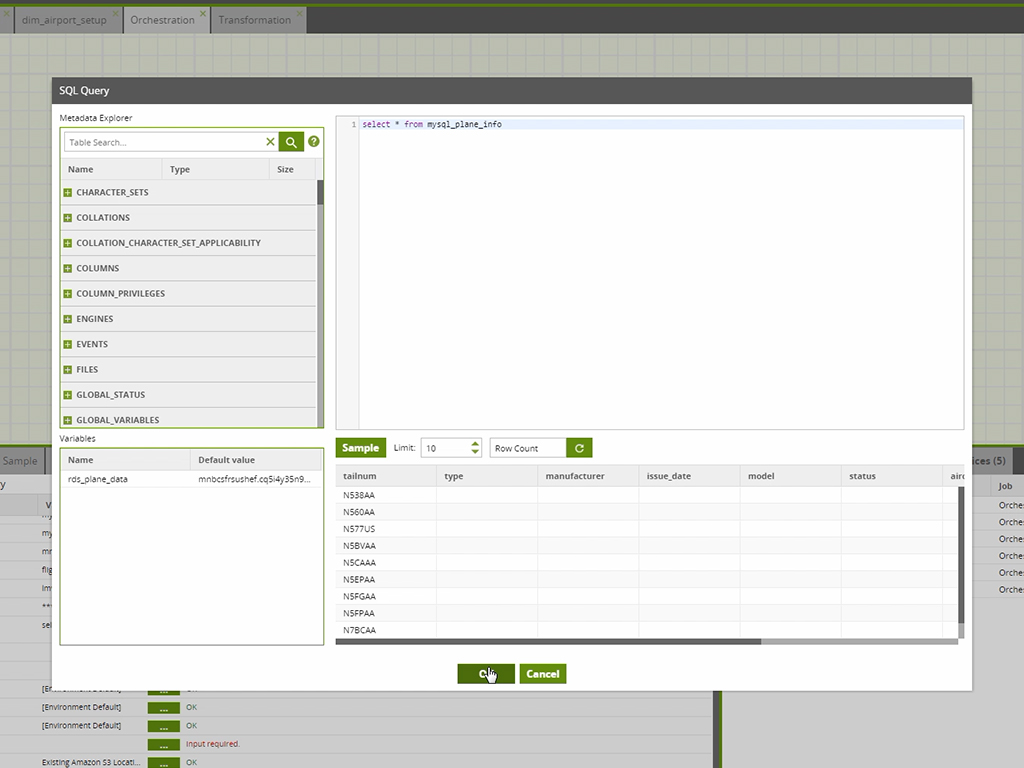
Matillion is a data pipeline platform used to build and manage pipelines. Matillion empowers data teams with no-code and AI capabilities to be more productive, integrating data wherever it lives and delivering data that’s ready for AI and analytics.
$2.50
Pay as you go per user
Pricing
Informatica Cloud Data Quality
Matillion
Editions & Modules
No answers on this topic
Developer: For Individuals
$2.50/credit
Pay as you go per user
Basic
$1000
per month 500 prepaid credits (additional credits: $2.18/credit)
Advanced
$2000
per month 750 prepaid credits (additional credits: $2.73/credit)
Enterprise
Request a Quote
Offerings
Pricing Offerings
Informatica Cloud Data Quality
Matillion
Free Trial
No
Yes
Free/Freemium Version
No
No
Premium Consulting/Integration Services
No
Yes
Entry-level Setup Fee
No setup fee
No setup fee
Additional Details
—
Billed directly via cloud marketplace on an hourly basis, with annual subscriptions available depending on the customer's cloud data warehouse provider.
For effective data collaboration, systematic verification of customer information, and address, among others, Informatica Data Quality is a fruitful application to consider. Besides, Informatica Data Quality controls quality through a cleansing process, giving the company a professional outline of candid data profiling and reputable analytics. Finally, Informatica Data Quality allows the simplistic navigation of content, with a dashboard that supports predictability.
Great: Need to query simpler APIs, or utilize well known services such as GSheets etc.? Matillion has got some of the best and easiest to use connectors out there. Not so great: Do you need have a competent CI/CD flow that you will be able to update / compare from Matillion as well as other sources at the same time? Good luck, you will need to be extra careful, as you might have to have a deeper dive into your servers Terminal each time you have a git conflict.
The matching algorithms in IDQ are very powerful if you understand the different types that they offer (e.g., Hamming Distance, Jaro, Bigram, etc..). We had to play around with it to see which best suit our own needs of identifying and eliminating duplicate customers. Setting up the whole process (e.g., creating the KeyGenerator Transformation, setting up the matching threshold, etc..) can be somewhat time consuming and a challenge if you don't first standardize your data.
The integration with PowerCenter is great if you have both. You can either import your mappings directly to PowerCenter or to an XML file. The only downside is that some of the transformations are unique to IDQ, so you are not really able to edit them once in PowerCenter.
The standardizer transformation was key in helping us standardize our customer data (e.g., names, addresses, etc..). It was helpful due to having create a reference table containing the standardized value and the associated unstandardized values. What was great was that if you used Informatica Analyst, a business analyst could login and correct any of the values.
Matillion is brilliant at importing data -- it would be amazing to have more ways to export data, from emailed exports to API pushes.
Any Python that takes more than a few lines of code requires an external server to run it. It would be great to have more integration (perhaps in a connected virtual environment) to easily integrate customized code.
Troubleshooting server logs requires quite a bit of technical expertise. More human readable detailed error handling would be greatly appreciated.
As pointed out earlier, due all the robust features IDQ has, our use f the product is successful and stable. IDQ is being used in multiple sources (from CRM application and in batch mode). As this is an iterative process, we are looking to improve our system efficiency using IDQ.
With the current experience of Matillion, we are likely to renew with the current feature option but will also look for improvement in various areas including scalability and dependability. 1. Connectors: It offers various connectors option but isn't full proof which we will be looking forward as we grow. 2. Scalability: As usage increase, we want Matillion system to be more stable.
We are able to bring on new resources and teach them how to use Matillion without having to invest a significant amount of time. We prefer looking for resources with any type of ETL skill-set and feel that they can learn Matillion without problem. In addition, the prebuilt objects cover more than 95% of our use cases and we do not have to build much from scratch.
Overall, I've found Matillion to be responsive and considerate. I feel like they value us as a customer even when I know they have customers who spend more on the product than we do. That speaks to a motive higher than money. They want to make a good product and a good experience for their customers. If I have any complaint, it's that support sometimes feels community-oriented. It isn't always immediately clear to me that my support requests are going to a support engineer and not to the community at large. Usually, though, after a bit of conversation, it's clear that Matillion is watching and responding. And responses are generally quick in coming.
IDQ is used by a department at my organisation to ensure and enhance the data quality. The usage was started with address standardization and now it had been brought to altogether a next level of quality check where it fixes duplicates, junk characters, standardize the names, streets, product descriptions. In the past we had issues mainly with duplicate customers and products and this were affecting the sales projection and estimates.
Fivetran offers a managed service and pre-configured schemas/models for data loading, which means much less administrative work for initial setup and ongoing maintenance. But it comes at a much higher price tag. So, knowing where your sweet spot is in the build vs. buy spectrum is essential to deciding which tool fits better. For the transformation part, dbt is purely (SQL-) code-based. So, it is mainly whether your developers prefer a GUI or code-based approach.
We're using Matillion on EC2 instances, and we have about 20 projects for our clients in the same instance. Sometimes, we're struggling to manage schedules for all projects because thread management is not visible, and we can't see the process at the instance level.