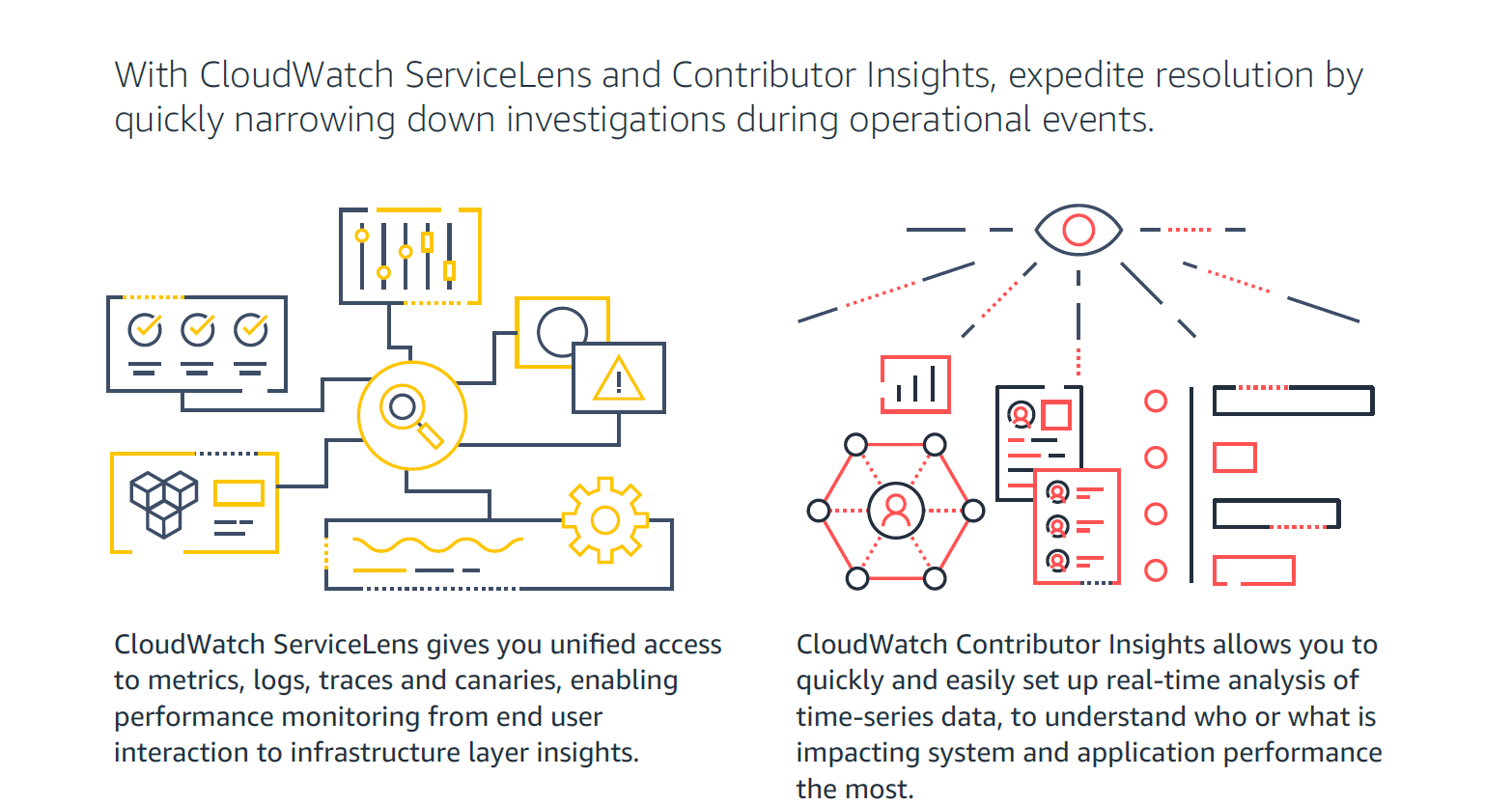
Amazon CloudWatch is a native AWS monitoring tool for AWS programs. It provides data collection and resource monitoring capabilities.
$0
per canary run
ScienceLogic AI Platform
Score 8.8 out of 10
Enterprise companies (1,001+ employees)
ScienceLogic provides a unified IT Operations platform designed to manage operational workflows using high-fidelity Telemetry Data and explainable automation.
The ScienceLogic AI Platform is deployable across On-Premises, Cloud, and Hybrid Environments. The platform consolidates monitoring tools to provide Observability and enables engineers to automate manual processes using Machine Learning capabilities.
The platform utilizes automation for Closed-Loop Remediation and provides insights…
N/A
Pricing
Amazon CloudWatch
ScienceLogic AI Platform
Editions & Modules
Canaries
$0.0012
per canary run
Logs - Analyze (Logs Insights queries)
$0.005
per GB of data scanned
Over 1,000,000 Metrics
$0.02
per month
Contributor Insights - Matched Log Events
$0.02
per month per one million log events that match the rule
Logs - Store (Archival)
$0.03
per GB
Next 750,000 Metrics
$0.05
per month
Next 240,000 Metrics
$0.10
per month
Alarm - Standard Resolution (60 Sec)
$0.10
per month per alarm metric
First 10,000 Metrics
$0.30
per month
Alarm - High Resolution (10 Sec)
$0.30
per month per alarm metric
Alarm - Composite
$0.50
per month per alarm
Logs - Collect (Data Ingestion)
$0.50
per GB
Contributor Insights
$0.50
per month per rule
Events - Custom
$1.00
per million events
Events - Cross-account
$1.00
per million events
CloudWatch RUM
$1
per 100k events
Dashboard
$3.00
per month per dashboard
CloudWatch Evidently - Events
$5
per 1 million events
CloudWatch Evidently - Analysis Units
$7.50
per 1 million analysis units
No answers on this topic
Offerings
Pricing Offerings
Amazon CloudWatch
ScienceLogic AI Platform
Free Trial
Yes
No
Free/Freemium Version
Yes
No
Premium Consulting/Integration Services
No
No
Entry-level Setup Fee
No setup fee
Required
Additional Details
With Amazon CloudWatch, there is no up-front commitment or minimum fee; you simply pay for what you use. You will be charged at the end of the month for your usage.
ScienceLogic SL1 offers four tiers:
SL1 Advanced – Application Health, Automated Troubleshooting and Remediation Workflows
SL1 Base – Infrastructure Monitoring, Topology & Event Correlation
SL1 Premium – AI/ML-driven Analytics, Low-Code Automated Workflow Authoring
SL1 Standard – Infrastructure Monitoring – with Agents, Business Services, Incident Automation, CMDB Synchronization, Behavioral Correlation
We use Cloudwatch for simpler monitoring, but these metrics and logs often feed into bigger ecosystems across our organization. The metrics and logs in Cloudwatch allow our developers quick and easy access to the data they need whilst easily integrating the same data into more …
Grafana is definitely a lot better and flexible in comparison with Amazon CloudWatch for visualisation, as it offers much more options and is versatile. VictoriaMetrics and Prometheus are time-series databases which can do almost everything cloudwatch can do in a better and …
In comparison to its competitors, Amazon CloudWatch is efficient, reliable, and has a fast response time, and it maximizes an application's life while also providing the best load balance and storage. The services that Amazon CloudWatch provides are far better and cheaper for …
We have also tested with SolarWinds NPM, and Zoho Monitors. They seemed to work fine and setup was not as involved as Amazon services, JSON, etc. However, the issue of upgrades made the other solutions incur more downtime overall for maintenance and software upgrades via the …
I think there is no alternative of [Amazon] CloudWatch service. However it provides lot of glue points which you can use to show different metrics, trigger events and update your dashboards.
I believe that CloudWatch is a better solution to use with AWS services and resources in terms of cost and ease of integration with AWS infrastructure services. But keep in mind that Elasticsearch is better at aggregating application-level metrics. We chose CloudWatch because of …
We found that CloudWatch is the best solution to use with AWS services in terms of cost and ease of integration with AWS infrastructure services. While Elasticsearch is better at aggregating application-level metrics, CloudWatch wins out in its capabilities to tightly integrate …
CloudWatch is the minimum viable product that is used as your baseline. Once you graduate beyond the basic needs, there is a wide range of tools from other AWS partners that go well above and beyond. However the cost of those tools is typically considerably more.
We thought about using Logstash for capturing our data. But we encountered several configuration issues, so as I mentioned before, if you're using AWS, the best way to do this is using the service they offer, as you don't encounter configuration problems. This is why I consider …
I think Amazon has put more efforts to develop AWS CloudWatch features to monitor each kind of AWS service you can use instead of Dynatrace One Agent that just can monitor some variables of Computing services and FaaS, unless Dynatrace One Agent integration with AWS CloudWatch …
Out of the box monitoring which compliments workloads implemented from infrastructure as code so we have standardized metrics across all our monitoring for our AWS workloads. Also incredibly easy to implement via the console which can be done in minutes oppose to hours of …
We choose Amazon CloudWatch because, first, we use AWS and we need a monitoring tool. That is why we considered CloudWatch as soon as we started deploying AWS services to our company. Second, CloudWatch is a great, handy tool to monitor our services. Its strength is obvious …
Currently, we only tried and used Cloud Watch, but for AWS it is perfect. Since this is an Amazon product monitoring Amazon services, integration is great. If we decide in the future to move away from AWS, we would reconsider changing alarm monitoring. AWS can be costly …
Amazon CloudWatch is fully integrated into your existing AWS account, and provides easy hooks into several different services to make a cohesive infrastructure. Unfortunately, using other services will not allow you to get into the weeds to do everything Amazon CloudWatch can …
CloudWatch is incredibly cheap compared to new relic and much more intuitive and easy to use than Nagios. It requires no setup, expertise, or otherwise extensive knowledge to use.
We used to use Miscosoft Azure, however when we came across Amazon CloudWatch, and all the features it can provide, it seemd no brainer to switch. We transitioned from Azure to CloudWatch within 2 years of using Azure, And may not go back. Hopefully Amazon will keep adding more …
Amazon CloudWatch is great in terms of the CloudWatch Logs feature, it integrates easily with other AWS services (CloudFormation, S3, Lambda, etc.) and is reasonably low cost, so it was a no-brainer for that area. For alerting, CloudWatch didn't offer much in the way of …
I feel that CloudWatch will always remain the backbone of log analytics, events, and alarms. However, we can use other products in conjunction with it for better log analytics and monitoring. In my organization, we also ingest logs from CloudWatch to Splunk and ELK. This way we …
real-time data monitoring, scalability of a complex environment is the key feature. For any new requirement, powerpack installation is very easy & handful.
Both of the tools we used before were with agents, so there was a need to configure the agent initially, before it could be used. Sometimes, there were issues with the service or the configuration of the agent, and deep troubleshooting was necessary to find the mistake in …
Restorepoint is a great tool and perfectly integrated with ScienceLogic SL1. However, PowerFlow implementation is not smooth and don't have enough resources to help build out the features necessary for a successful implementation. Also, documentation is not well written.
ScienceLogic SL1 supports large scale of IT Infrastructure devices and vendors. Was the single tool providing multiple functionalities at same time and allowed to remove additional legacy tools used for monitoring. Allowed integration with incident management and CMDB. Allowed …
From a capability perspective they stack up very similar but from a look and feel, ScienceLogic SL1 one is miles behind the curve on all three. We chose SL because we already had elements of the service in place on our infrastructure from our previous MSP so they were a …
I see great potential and infact i do strongly beleive it offers even beter capabilities than the traditional tools out there but again it comes down to how well you have trained us on how to unlock these capabilities. I suggest incentives for techs for providing feedback for …
Geneos is more complicated and 'heavy' to setup. It requires a lot of expertise in setting up. Also the dashboards are not great. ScienceLogic SL1 works well for customer facing dashboards.
Entuity was lacking a lot of custom reporting and also the out of the box automation and RBA was also less. Our customers were mainly looking for devices which are next gen like sdwan which Entuity doesn't support. When it come to ScienceLogic SL1 it will support all sets of …
As a fresher, this is my first organization, and they use SL1. So, I don’t have more knowledge of other tools. But I do know Grafana, which is predominantly used for dashboards. I think compared to that, the SL1 dashboard gives more details about devices. So, I feel SL1 would …
Galileo analyzes storage arrays and backups more thoroughly, but SL1 is much better for host and network monitoring. SL1 has some storage monitoring features for some storage arrays, but they are not as detailed.
I was not part of the team selecting ScienceLogic SL1. Our goal was to increase event visibility in our server environment. We were using scripting which created many false events. SolarWinds is primarily used in the Network space to monitor network gear.
Agentless product that can integrate easily with other product and also allow us to automate tasks, example closing tickets when events are cleared automatically which user interactions.
Just because Science logic provides much more better enhancement and getting improved everyday. The autonomous integration and overall customization provided by the SL1 Platform is outstanding. In every sections be it in Monitoring or checking system logs and provide the best …
If you use any AWS services, CloudWatch is the natural choice to monitor & troubleshoot your workload. Thankfully, for most AWS services, CloudWatch is either built-in or very easy to set up. However, being proficient in browsing & tracking the log events would take some training & practice. Having some experienced people on the team would help immensely, especially in spreading the skill to the rest of the team.
Appropriate if you are setting up a monitoring suite in new Infrastructure Environment. Definitely NOT suited for Migration Projects. ScienceLogic SL1 cannot cater to a lot of monitoring requirements which already would have been configured in old monitoring suite. Plus, limited support for customizations and having to go to "Feature Requests" route makes in extremely complicated.
It provides lot many out of the box dashboard to observe the health and usage of your cloud deployments. Few examples are CPU usage, Disk read/write, Network in/out etc.
It is possible to stream CloudWatch log data to Amazon Elasticsearch to process them almost real time.
If you have setup your code pipeline and wants to see the status, CloudWatch really helps. It can trigger lambda function when certain cloudWatch event happens and lambda can store the data to S3 or Athena which Quicksight can represent.
Memory metrics on EC2 are not available on CloudWatch. Depending on workloads if we need visibility on memory metrics we use Solarwinds Orion with the agent installed. For scalable workloads, this involves customization of images being used.
Visualization out of the box. But this can easily be addressed with other solutions such as Grafana.
By design, this is only used for AWS workloads so depending on your environment cannot be used as an all in one solution for your monitoring.
Creating powerpacks from scratch for new devices may be straightforward but will rarely be easy. Rewarding when completed, but not easy.
Developer documentation needs a rethink. While the information may be there (it isn't always) it is not easy to find. This is not helped by using different terms for the same things.
A developer console/dashboard for monitoring data collection from powerpacks instances without having to switch webpages or have to monitor multiple webpages.
We migrated away from our 20-year-old homegrown solution and have no back-tracking capability. ScienceLogic is demonstrating new capabilities that we would not have been able to do on our own using our legacy system. We understand the capabilities of competitors based on our bake-off selection where ScienceLogic won on capabilities and future near-term potential (expandability, platform growth). We know that those competitors are not really close to where we have been able to push ScienceLogic (as a partner).
Although the tool itself is easy to integrate and is readily available for use, it has its limitations. The key limitations of cloudwatch are with respect to cost incurred on log retention and log querying. While for key use cases this is sufficient, for more advanced use cases, Amazon CloudWatch doesn't work out. Also, obviously it is tightly coupled with AWS, which makes you look away if you need a single tool for all monitoring
We use ScienceLogic SL1 in our organization to serve effective monitoring solutions to our external customers. Our customers depend upon us for critical events/alerts related to their IT infrastructure gears and using SL1, we're able to provide them with a proactive monitoring solution that resolves an issue before an impact is noticed by the customer. There are very few monitoring solutions that can cater to a variety of Cloud platforms like Public Cloud (AWS, Azure) and private cloud simultaneously and SL1 addresses this business problem very well
Science Logic SL1 provides the option of Distributed deployment where multiple instances of each appliance can be deployed to manage the load and availability. SL1 provides a High Availability feature for Database Servers and Data Collection. If one of the Data Collectors in the collector group fails, it will automatically redistribute the devices from the failed Data Collector among the other Data Collectors in the Collector Group. The high availability feature for the Database server ensures that SL1 performs failover automatically to another server without causing the outage to the application.
The performance is entirely dependent on the complexity of the environment/network being used to host the platform. Outside of those factors, the platform runs very efficiently and quickly out of the box. We have integrations with other platforms and neither seem to take a hit from our moderate API usage. Any issues with performance would be experienced by choices made in infrastructure or complexity of things built by the customer to display in the GUI (overly complicated and cluttered dashboards for example)
Support is effective, and we were able to get any problems that we couldn't get solved through community discussion forums solved for us by the AWS support team. For example, we were assisted in one instance where we were not sure about the best metrics to use in order to optimize an auto-scaling group on EC2. The support team was able to look at our metrics and give a useful recommendation on which metrics to use.
So far, it's good as part of my overall experience, except for a couple of use cases. The support team is well knowledgeable, has technical sound, and is efficient. When support escalates to engineering, the issue gets stuck and takes months to resolve.
When I joined our company, I did not know about the in person training at firts. Logging onto the SL University, I realised that there were different sessions being held at different times throughout the year. The training itself was good, but being in a different time zone, made it difficult to attend, but the sessions that I attended was great!
There are a lot of educational materials and courses on the SL1 training site (Litmos university). However the recording quality is sometimes not very good - screen resolution is low. There is a lack of professional rather than user-oriented documents and there are mistakes in documentation and education is not well structured.
Along with the purchase of the solution, we purchased a statement of work with their Professional Services organization to meet our outcomes and fill our critical gaps. The PS team was outstanding, very professional and allowed us to screen share while they built our integrations. In many cases they would teach us how they did certain things within the platform.
We use Cloudwatch for simpler monitoring, but these metrics and logs often feed into bigger ecosystems across our organization. The metrics and logs in Cloudwatch allow our developers quick and easy access to the data they need whilst easily integrating the same data into more prominent platforms for wider analysis, including Service desk support, SecOps, and ITOps monitoring within the organization.
Both of the tools we used before were with agents, so there was a need to configure the agent initially, before it could be used. Sometimes, there were issues with the service or the configuration of the agent, and deep troubleshooting was necessary to find the mistake in configuration before the communication with the endpoint was restored. Once the tools were running, they enabled very smooth reporting of what is running and what not, and the performance impact was lover than with WINRM monitoring.
Our deployment model is vastly different from product expectations. Our global / internal monitoring foot print is 8 production stacks in dual data centers with 50% collection capacity allocated to each data center with minimal numbers of collection groups. General Collection is our default collection group. Special Collection is for monitoring our ASA and other hardware that cannot be polled by a large number of IP addresses, so this collection group is usually 2 collectors). Because most of our stacks are in different physical data centers, we cannot use the provided HA solution. We have to use the DR solution (DRBD + CNAMEs). We routinely test power in our data centers (yearly). Because we have to use DR, we have a hand-touch to flip nodes and change the DNS CNAME half of the times when there is an outage (by design). When the outage is planned, we do this ahead of the outage so that we don't care that the Secondary has dropped away from the Primary. Hopefully, we'll be able to find a way to meet our constraints and improve our resiliency and reduce our hand-touch in future releases. For now, this works for us and our complexity. (I hear that the HA option is sweet. I just can't consume that.)