







SL1 A Reliable User-Friendly.

Use Cases and Deployment Scope
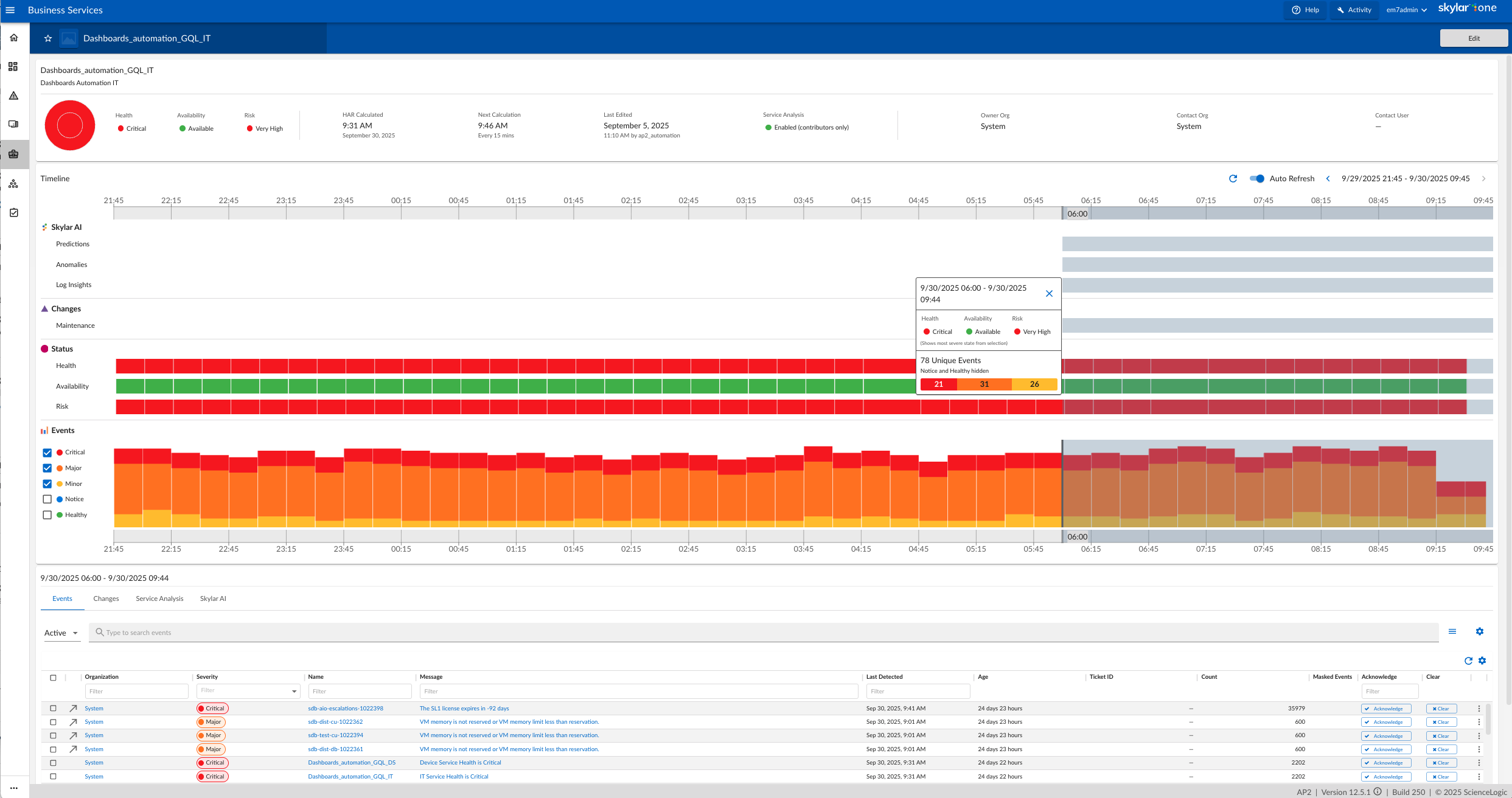
To monitor any type of network device, it's very user-friendly & easy to understand. We can explore much & have real-time troubleshooting. Log analysis is very efficient. Dashboard customization & report fetching based on user requirements can also be done very proficiently.
Pros
- Monitors of any type of network nodes.
- Delivering unified visibility across hybrid and multi-vendor environments.
- Observability
Cons
- Event parsing & ticket generation can be more efficient.
Return on Investment
- Time saving.
- Power flow.
- Enhanced visibility.
- Observability
Other Software Used
Splunk Enterprise Security












