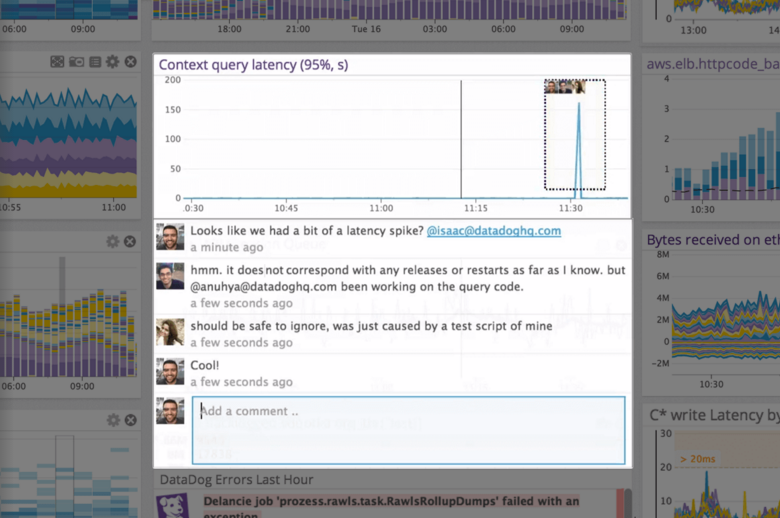
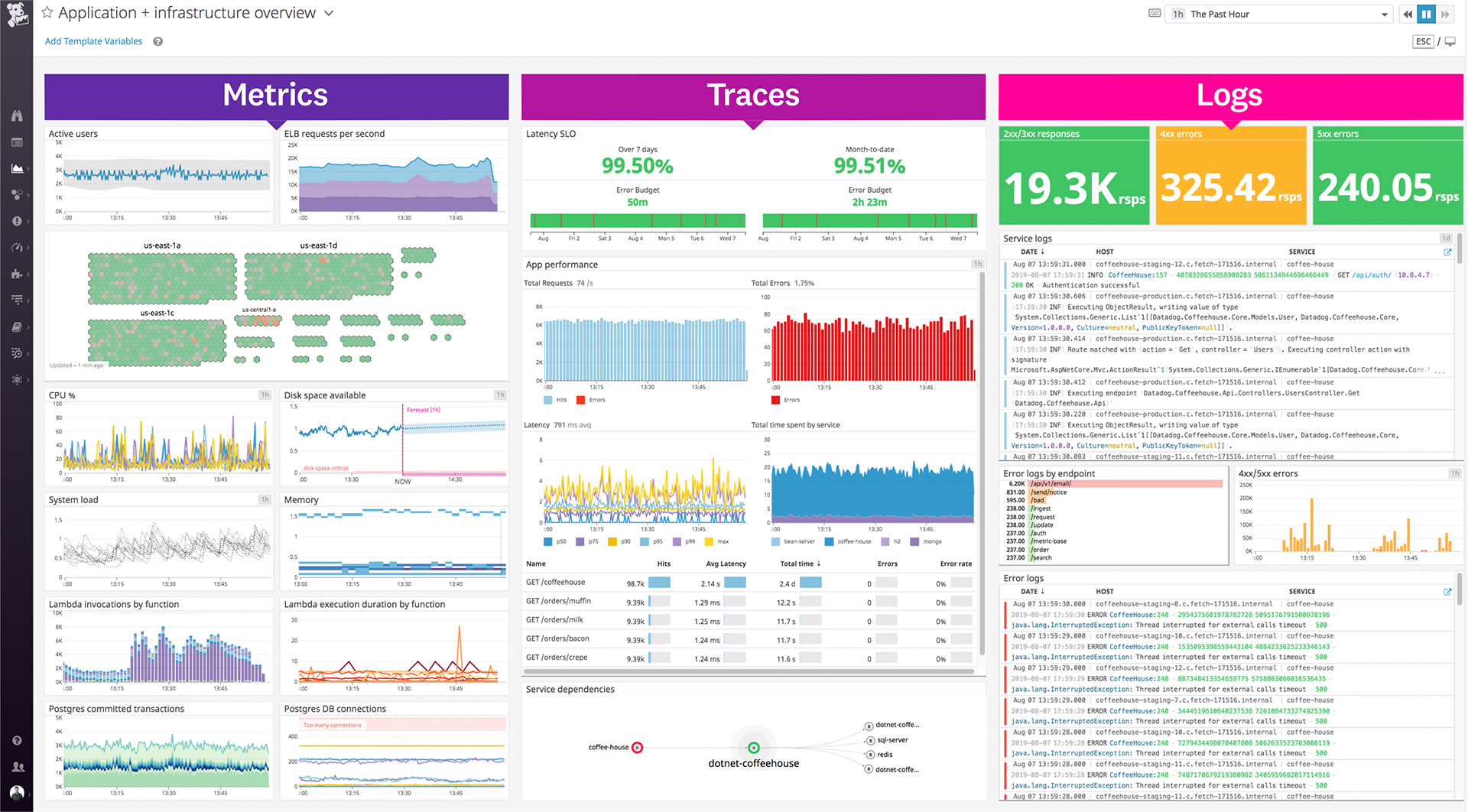
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
Virtana Platform
Score 8.8 out of 10
N/A
Virtana delivers enterprise-grade deep hybrid infrastructure observability, enabling organizations to achieve visibility and control across their entire IT estate. The platform unifies monitoring of on-premises, cloud, and Kubernetes environments, to transform complex infrastructure management into a strategic advantage. Core Platform Capabilities Deep Infrastructure Observability: · Automated topology discovery and mapping · Real…
$5
per month per device
Zabbix
Score 8.5 out of 10
N/A
Zabbix is an open-source network performance monitoring software. It includes prebuilt official and community-developed templates for integrating with networks, applications, and endpoints, and can automate some monitoring processes.
N/A
Pricing
Datadog
Virtana Platform
Zabbix
Editions & Modules
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
Free
$0
Pro
$5
per month per device
No answers on this topic
Offerings
Pricing Offerings
Datadog
Virtana Platform
Zabbix
Free Trial
Yes
No
No
Free/Freemium Version
Yes
Yes
No
Premium Consulting/Integration Services
No
No
No
Entry-level Setup Fee
Optional
No setup fee
No setup fee
Additional Details
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
Volume discounts are available (600+ devices / month)
A device is any running AWS EC2 or Azure VM evaluated by Virtana Optimize in a given month
Ultimately, Datadog had the most already-built bridges into our existing infrastructure -- third parties that we're using for certain services are far more likely to work with Datadog than other systems. This means that, while expensive, Datadog has done a tremendous amount of …
Datadog empowers us to create dashboards and visualize the state of our infrastructure in real time. It gives us control over what we want to view and how. The graphs provide deep insight into trends and anamoly detectives. These features are lacking in some of the other …
We don't have much to say bad about other services. We just found that Metricly was a good fit for us. And their customer support is really really good. So if we get stuck we simply reach out for help which hasn't been very often. We didn't get that kind of support from other …
We strongly prefer Metricly for AWS Cost Analysis -- whereas other tools are easier to use on a traditional monitoring basis. To be clear, Merticly's monitoring tools are GREAT, but they require tuning and manual setup that we didn't have the time for on a small Platform …
Zabbix is a great, free solution. While not everything is discovered and configured out of the box, it is a powerful tool that allows for complete customization to what your organization needs as far as a monitoring solution. We've invested the time to make Zabbix powerful, …
Zabbix was much better at handling traditional systems, and in ease of customization, both in the system itself, and customizing data sources, such as adding deep MySQL or JMX integrations. It's very good for organizing large-scale (hundreds or thousands of servers) systems; …
I personally prefer Zabbix over any other monitoring software that I have ever tried. Zabbix is so customizable that if there is a feature I need, I can easily implement it. I can then add that feature to a template in no time and have it applied to hundreds, or even thousands, …
More extensive and customizable than SaaS solutions. Much less learning curve than Nagios. Cost is very much lower than SaaS monitoring especially at scales over 1000 hosts ($15,000/month for SaaS!!) Templating systems allows for easy management and monitoring of groups of …
Zabbix is cost effective maybe and certainly a good tool but not the best. The other ones have features that Zabbix is missing and we use couple of them.
Nagios has some advantages over Zabbix like "flapping" detection and multiple alert levels - Error, Warning and OK. However, the disadvantages of Nagios like needing an addon (NRPE) to monitor remote system internals (open files, running processes, memory, etc), no charting of …
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
Overall I would say that we have been very happy with Zenoss. It has been a great server monitoring tool. There are certain aspects that we would like to expand into, such as Capacity Planning, Network Performance Monitoring, and log analysis. We have coupled Zenoss logs with Splunk for external log management, but would like to start using some of the built-in analysis tools.
Zabbix is great for monitoring your servers and seeing alerts when the system uses too much CPU or memory. This allowed the system Engineer to be proactive and add resources to these systems to avoid interrupting the services. Especially servers running operations applications and services. This is one of the best usages for Zabbix.
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Collecting hardware data - CPU, Memory, Network, and Disk Metrics are collected and reported on.
Flexible design - It is very easy to build out even very large environments via the templating system. You can also start where you are - network monitoring, server monitoring, etc. and then build it out from there as time and resources permit.
Provides a "plugin architecture" (via XML templates) to allow end users to extend it to monitor all kinds of equipment, software, or other metrics that are not already added into the software already.
Very complete documentation. Almost every aspect of Zabbix has been documented and reported on.
Cost - Zabbix is FOSS software and always free. Support is reasonably priced and readily available.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
It is free. It didn't cost anything to implement (other than my time and the cost incurred for it) and it is filling a badly needed gap in our IT infrastructure. Support is available if we have issues and can be done annually or paid for on a per incident basis as needed. Expansion, updates, and all other future lifecycle activities are likewise free of cost, so as long as someone is able to implement/maintain the software (and the OSS project is maintained) then I imagine the company will never leave it.
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
I think every organization, especially the IT department, needs a tool like this. I know of another product like Zabbix that gives a similar or the same solution, but its range makes it very useful. You can see almost all the device info in one place: disk usage, disk space, network usage, etc.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
The setup is the most time-consuming portion of using zabbix. It takes a lot of effort to shape it into a usable format and even then it can get very messy. It's not exactly intuitive and as mentioned the UI seems a bit antiquated. If I was to roll out a monitoring solution from scratch, I'd probably look for alternatives which are easier to use and maintain.
We are a mainly Windows environment, so it would be useful if we could have used Active Directory to deploy agents. As of version 4.2, Zabbix has announced a new agent MSI file to allow exactly that. Unfortunately, we didn't have that option. Also, for Linux and MAC deployments, there is no simple way to deploy that. Using remote scripts you may be able to create something, but most places will opt for either SNMP (agentless) or manual installation of agents to add to Zabbix. A way of deploying agents via discovery would go a long way to helping in the adoption of the tool.
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
We strongly prefer Metricly for AWS Cost Analysis -- whereas other tools are easier to use on a traditional monitoring basis. To be clear, Merticly's monitoring tools are GREAT, but they require tuning and manual setup that we didn't have the time for on a small Platform Operations team. We have worked closely with Metricly to expand on their cost analysis capabilities, and plan to use them going forward.
We're using the Solarwinds suite as our global monitoring standard, but it is very complex and its licensing model makes it difficult to monitor a wide range of technologies. So, we're using Zabbix as a complement on our monitoring process. Zabbix is a way more flexible and has free integrations to a wide range of technologies. It is also more 'user friendly' and easy to manage.
We're a reseller/Integrator, so this question has a somewhat different meaning to our business. For us, Zenoss Cloud allows us to provide a single Cloud-based monitoring platform that can address virtually all our clients' use cases, dramatically simplifying our training and staffing requirements. Instead of training Engineers on several platforms, including the installation of physical hardware/software, we can focus on a single platform.
The faster time-to-deployment and always-on cloud platform is a great fit for DevOps environments and newer software-defined data center platforms. The ability of Zenoss to support these environments solves what has been a major blind spot, slowing adoption of platforms that have been difficult to effectively manage with legacy monitoring platforms.
For clients, the ability to consolidate from multiple prem-based tools to a single cloud-based platform is huge. Eliminating multiple licenses and ongoing hardware & administration costs can show a 1-2 year ROI.