Apache Kafka is an open-source stream processing platform developed by the Apache Software Foundation written in Scala and Java. The Kafka event streaming platform is used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
N/A
RabbitMQ
Score 9.1 out of 10
N/A
RabbitMQ, an open source message broker, is part of Pivotal Software, a VMware company acquired in 2019, and supports message queue, multiple messaging protocols, and more.
RabbitMQ is available open source, however VMware also offers a range of commercial services for RabbitMQ; these are available as part of the Pivotal App Suite.
N/A
HPE Zerto Software
Score 8.9 out of 10
Enterprise companies (1,001+ employees)
HPE Zerto Software aims to enable customers to run an always-on business by simplifying the protection, recovery, and mobility of on-premises and cloud applications.
N/A
Pricing
Apache Kafka
RabbitMQ
HPE Zerto Software
Editions & Modules
No answers on this topic
No answers on this topic
No answers on this topic
Offerings
Pricing Offerings
Apache Kafka
RabbitMQ
HPE Zerto Software
Free Trial
No
No
Yes
Free/Freemium Version
No
No
No
Premium Consulting/Integration Services
No
No
No
Entry-level Setup Fee
No setup fee
No setup fee
Optional
Additional Details
—
—
—
More Pricing Information
Community Pulse
Apache Kafka
RabbitMQ
HPE Zerto Software
Considered Multiple Products
Apache Kafka
Verified User
Engineer
Chose Apache Kafka
I would only use RabbitMQ over Kafka when you need to have delay queues or tons of small topics/queues around. I don't know too much about Pulsar - currently evaluating it - but it's supposed to have the same or better throughput while allowing for tons of queues. Stay tuned - I …
Kafka is not a real messaging broker implementation as RabbitMQ or TIBCO EMS/JMS are. Although it can be used as messaging, we like the idea behind the Kafka (data isn't "passing by," instead it remains centra, so the client can revisit the data if necessary). This also …
Apache Kafka is built for scale. From high throughput and real-time data streaming, it has a strong advantage over RabbitMQ with its low latency. This put Apache Kafka at the forefront as the platform of choice for large datasets messaging and ensuring scalability when data …
We really needed to get away from using a SQL database to act as a queue for processing records, so a new solution was needed. Kafka is a leading software application initially designed for queuing messages which is essentially what we were looking for. It has a great user …
Confluent Cloud is still based on Apache Kafka but it has a subscription fee so, from a long term perspective, it is wiser to deploy your own Kafka instance that spans public and private cloud. Amazon Kinesis, Google Cloud Pub/Sub do not do well for a very number of messages …
It is very easy to use as it has a simple function to connect and use RabbitMQ. It is having Fast Learning curve, Any newbies can learn it in a week or month. It is having proper documentation, we are able to find all the details about its functionality and usage of it. The …
Honestly, though we're still trying out Kafka and Pulsar, I'd go with them for message broker and as traffic buffers. We are only still using RabbitMQ because it's hard to transition off after writing tons of code custom-built for RabbitMQ. Kafka is better because it's way more …
Apache Kafka is well-suited for most data-streaming use cases. Amazon Kinesis and Azure EventHubs, unless you have a specific use case where using those cloud PaAS for your data lakes, once set up well, Apache Kafka will take care of everything else in the background. Azure EventHubs, is good for cross-cloud use cases, and Amazon Kinesis - I have no real-world experience. But I believe it is the same.
It is highly recommended that if you have microservices architecture and if you want to solve 2 phase commit issue, you should use RabbitMQ for communication between microservices. It is a quick and reliable mode of communication between microservices. It is also helpful if you want to implement a job and worker mechanism. You can push the jobs into RabbitMQ and that will be sent to the consumer. It is highly reliable so you won't miss any jobs and you can also implement a retry of jobs with the dead letter queue feature. It will be also helpful in time-consuming API. You can put time-consuming items into a queue so they will be processed later and your API will be quick.
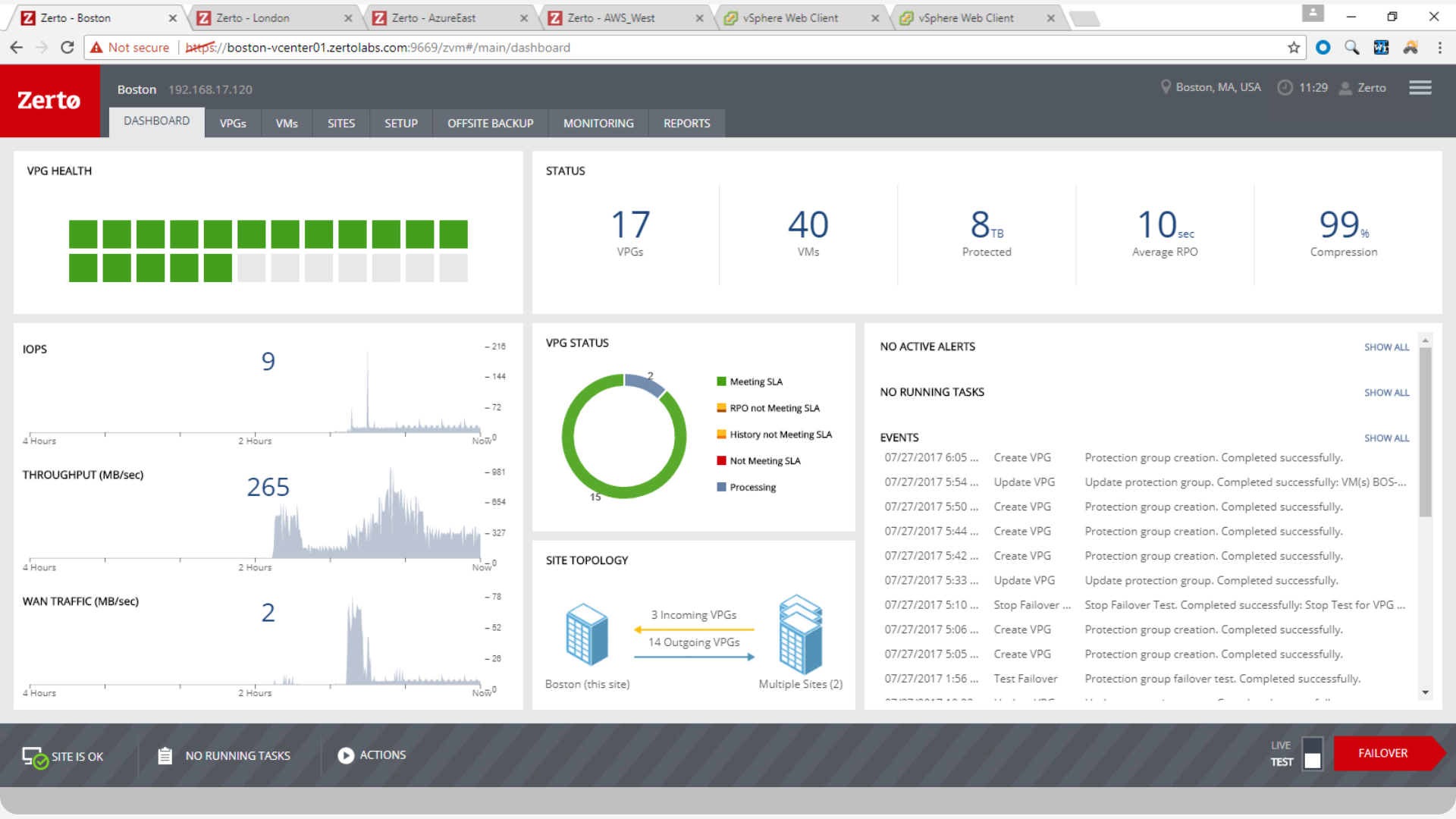
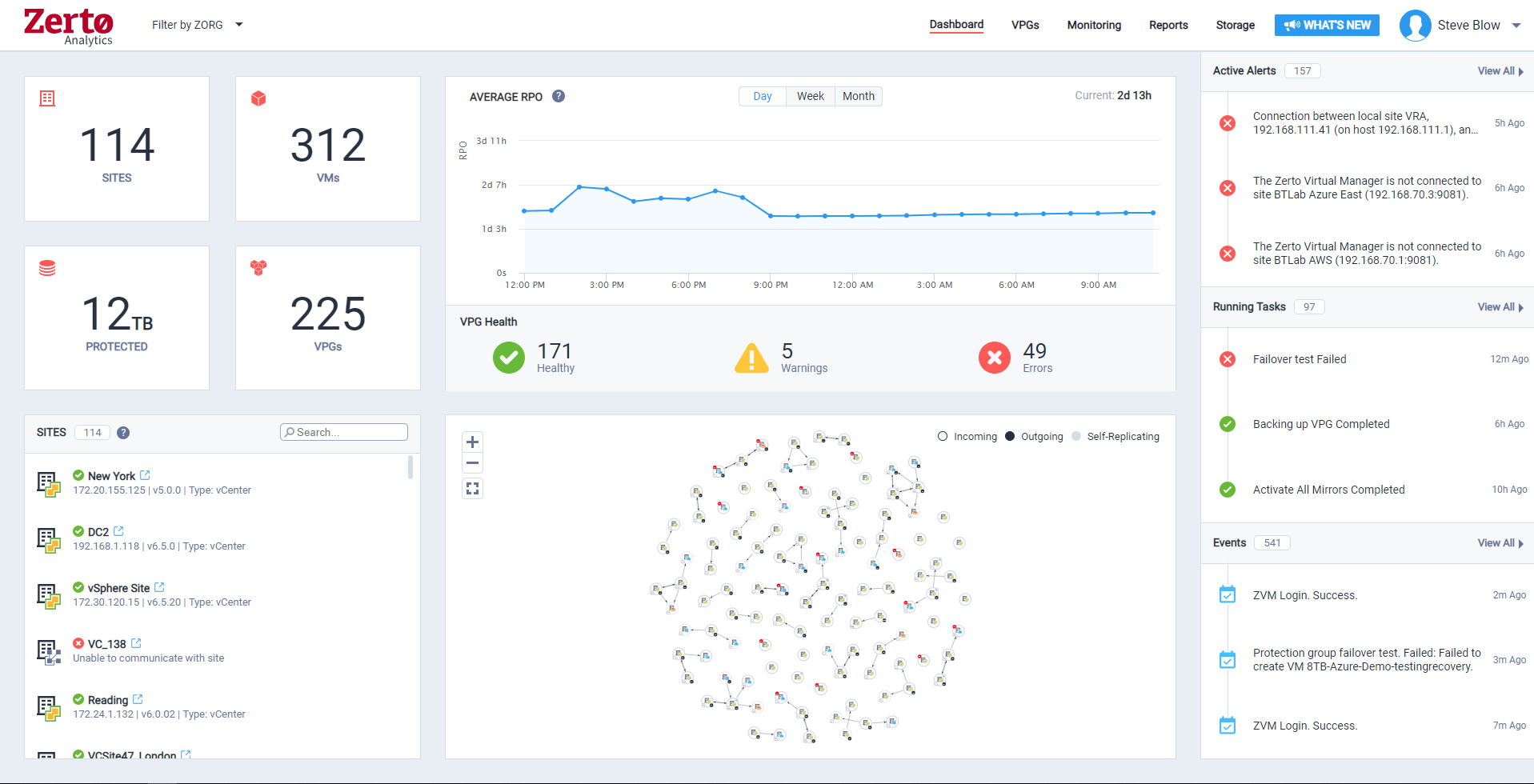
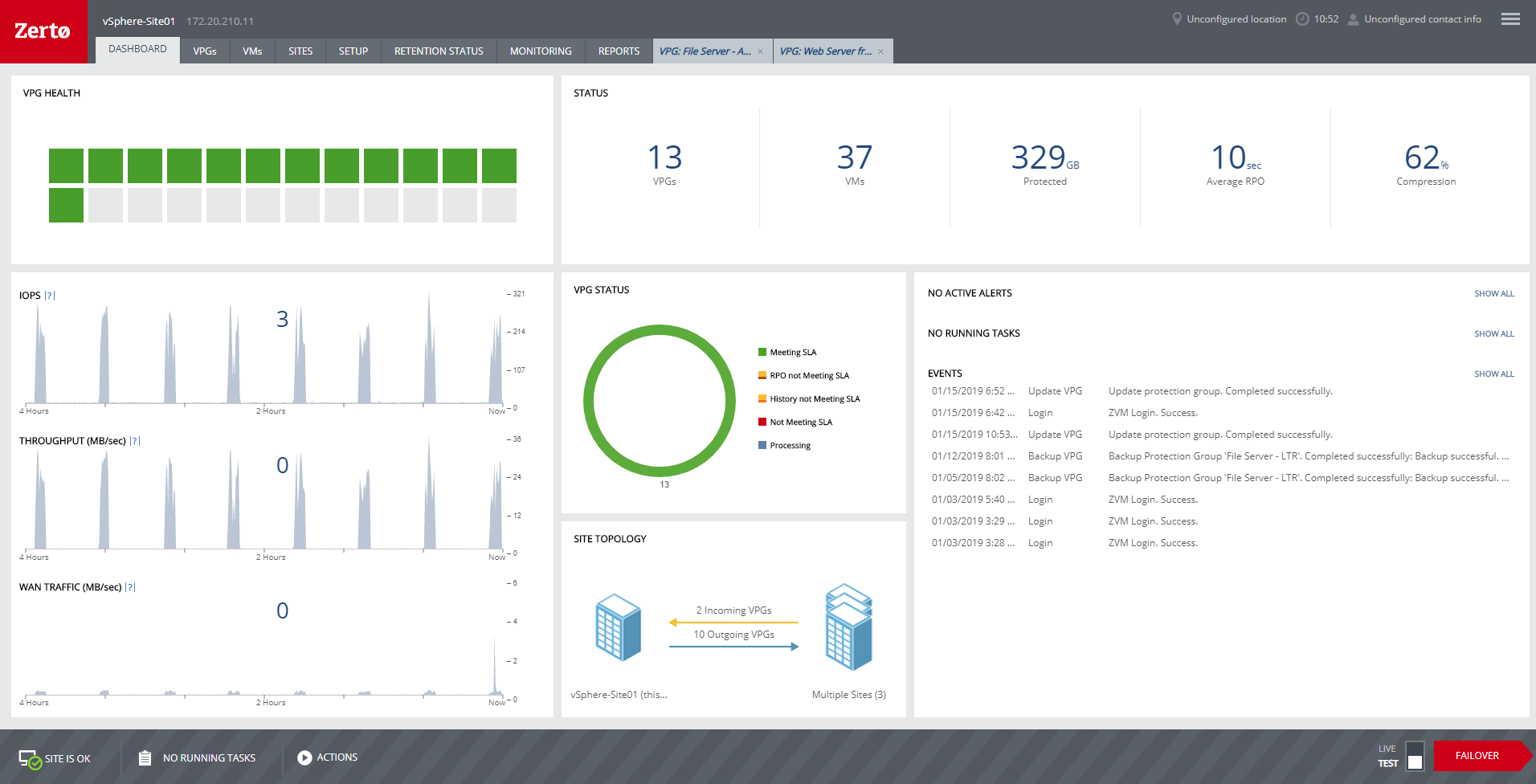
Zerto is well suited for disaster recovery and virtual machine replication between multiple data centers. DR testing for audit or regulations is much easier with Zerto, great reporting, dashboard etc. It is not well suited for physical server replication for disaster recovery or as a primary backup solution.
Really easy to configure. I've used other message brokers such as RabbitMQ and compared to them, Kafka's configurations are very easy to understand and tweak.
Very scalable: easily configured to run on multiple nodes allowing for ease of parallelism (assuming your queues/topics don't have to be consumed in the exact same order the messages were delivered)
Not exactly a feature, but I trust Kafka will be around for at least another decade because active development has continued to be strong and there's a lot of financial backing from Confluent and LinkedIn, and probably many other companies who are using it (which, anecdotally, is many).
What RabbitMQ does well is what it's advertised to do. It is good at providing lots of high volume, high availability queue. We've seen it handle upwards of 10 million messages in its queues, spread out over 200 queues before its publish/consume rates dipped. So yeah, it can definitely handle a lot of messages and a lot of queues. Depending on the size of the machine RabbitMQ is running on, I'm sure it can handle more.
Decent number of plugins! Want a plugin that gives you an interface to view all the queues and see their publish/consume rates? Yes, there's one for that. Want a plugin to "shovel" messages from one queue to another in an emergency? Check. Want a plugin that does extra logging for all the messages received? Got you covered!
Lots of configuration possibilities. We've tuned over 100 settings over the past year to get the performance and reliability just right. This could be a downside though--it's pretty confusing and some settings were hard to understand.
Anyone with a large disk (VMDK) knows the issues of VMware snapshots. Most backup software is a "point in time backup" that uses snapshots. While the backup can be run multiple times per day the stress of the snapshot on the host and storage is eliminated by the continuous protection of Zerto log replication.
A client had a the disks on a VM go missing for some reason. We had them "flip the switch" for a real fail over and press the fail over button. The VM on our DR site started to come alive as the VM at the customer site was brought down. When the DR VM was fully up, automatic reverse replication started. The DR machine was available in a few minutes (to take into account different host hardware) for access. One the vm at both sites were in sync, we had the customer again repeat the fail over process and the DR site VM was turned off and the Production site VM was brought back on line. This was a 200 GB VM and the whole process was finished in about 3 hours.
Zerto also allows for "Test" fail overs that can be configured on many different functions, such as host, datastore, network and IP usage. Configuring the IPs is crucial to avoid inadvertent site cross contamination of the same VM.
Zerto can also retrieve files from any VM disk on the DR site without starting a VM. Very handy for retrieving files or directories.
Since Zerto is running continuous log replication, changes on the production VM are nearly instantaneously copied to the DR site. As with any data process, having sufficient bandwidth for "churn" peaks minimizes the delay in updating the DR site.
Sometimes it becomes difficult to monitor our Kafka deployments. We've been able to overcome it largely using AWS MSK, a managed service for Apache Kafka, but a separate monitoring dashboard would have been great.
Simplify the process for local deployment of Kafka and provide a user interface to get visibility into the different topics and the messages being processed.
Learning curve around creation of broker and topics could be simplified
It breaks communication if we don't acknowledge early. In some cases our work items are time consuming that will take a time and in that scenario we are getting errors that RabbitMQ broke the channel. It will be good if RabbitMQ provides two acknowledgements, one is for that it has been received at client side and second ack is client is completed the processing part.
We really like the easy setup of this replication solution, as well as the ease of management. Not to mention, our internal IT Economist determined that the Zerto solution would provide the best ROI out of the competing solutions we analyzed. So far, his calculations have been spot on, and we have saved substantially
Apache Kafka is highly recommended to develop loosely coupled, real-time processing applications. Also, Apache Kafka provides property based configuration. Producer, Consumer and broker contain their own separate property file
RabbitMQ is very easy to configure for all supported languages (Python, Java, etc.). I have personally used it on Raspberry Pi devices via a Flask Python API as well as in Java applications. I was able to learn it quickly and now have full mastery of it. I highly recommend it for any IoT project.
Zerto is very easy to implement and support. Uses are broad, only issues are once something doesn't sync it is difficult to get assistance until your reach tier 2 or tier 3 support. Basic file and folder recovery is great. Live and test fail overs are also easy to implement without issue.
Support for Apache Kafka (if willing to pay) is available from Confluent that includes the same time that created Kafka at Linkedin so they know this software in and out. Moreover, Apache Kafka is well known and best practices documents and deployment scenarios are easily available for download. For example, from eBay, Linkedin, Uber, and NYTimes.
I gave it a 10 but we do not have a support contract with any company for RabbitMQ so there is no official support in that regard. However, there is a community and questions asked on StackOverflow or any other major question and answer site will usually get a response.
Overall support is very good. We sometimes get pushback when asking Level 1 support to escalate to Level 2. This causes undue frustrations when you need a more knowledgeable support person to get involved. We've had to escalate to account reps a few times for this scenario. Zerto is very responsive and normally handles our requests very quickly.
I used other messaging/queue solutions that are a lot more basic than Confluent Kafka, as well as another solution that is no longer in the market called Xively, which was bought and "buried" by Google. In comparison, these solutions offer way fewer functionalities and respond to other needs.
RabbitMQ has a few advantages over Azure Service Bus 1) RMQ handles substantially larger files - ASB tops out at 100MB, we use RabbitMQfor files over 200MB 2) RabbitMQ can be easily setup on prem - Azure Service Bus is cloud only 3) RabbitMQ exchanges are easier to configure over ASB subscriptions ASB has a few advantages too 1) Cloud based - just a few mouse clicks and you're up and running
We started out using Backup Exec which was in service until we virtualized our environment where it didn't perform as well at the time. Then we switched to Veeam which worked well, but then as we started needing to do migrations and off-site DR, we found ourselves relying on Zerto more often.
For my organization, the pricing model was an upfront investment for the Zerto licenses. My organization prefers to pay upfront and not deal with month-to-month or year-to-year pricing models that most companies are moving to. But for some, the investment may be more than they can afford, and would prefer the year-to-year pricing model.
I mean, it was 6 years ago, but we were up and going with all applications synchronizing in short order. The longest tasks was getting the 30 TB of application data synchronized between the datacenters.
Positive: Get a quick and reliable pub/sub model implemented - data across components flows easily.
Positive: it's scalable so we can develop small and scale for real-world scenarios
Negative: it's easy to get into a confusing situation if you are not experienced yet or something strange has happened (rare, but it does). Troubleshooting such situations can take time and effort.
Positive: we don't need to keep way too many backend machines around to deal with bursts because RabbitMQ can absorb and buffer bursts long enough to let an understaffed set of backend services to catch up on processing. Hard to put a number to it but we probably save $5k a month having fewer machines around.
Negative: we've got many angry customers due to queues suddenly disappearing and dropping our messages when we try to publish to them afterward. Ideally, RabbitMQ should warn the user when queues expire due to inactivity but it doesn't, and due to our own bugs we've lost a lot of customer data as a result.
Positive: makes decoupling the web and API services from the deeper backend services easier by providing queues as an interface. This allowed us to split up our teams and have them develop independently of each other, speeding up software development.
Zerto is like having the best possible insurance ... it just works, and often provides the backups taken overnight that are key in recovering data/work between overnight backups.
Zerto easily enabled the move of primary datacenters by allowing easy failover to a secondary site, and failback to the primary site.