Apache Solr is an open-source enterprise search server.
N/A
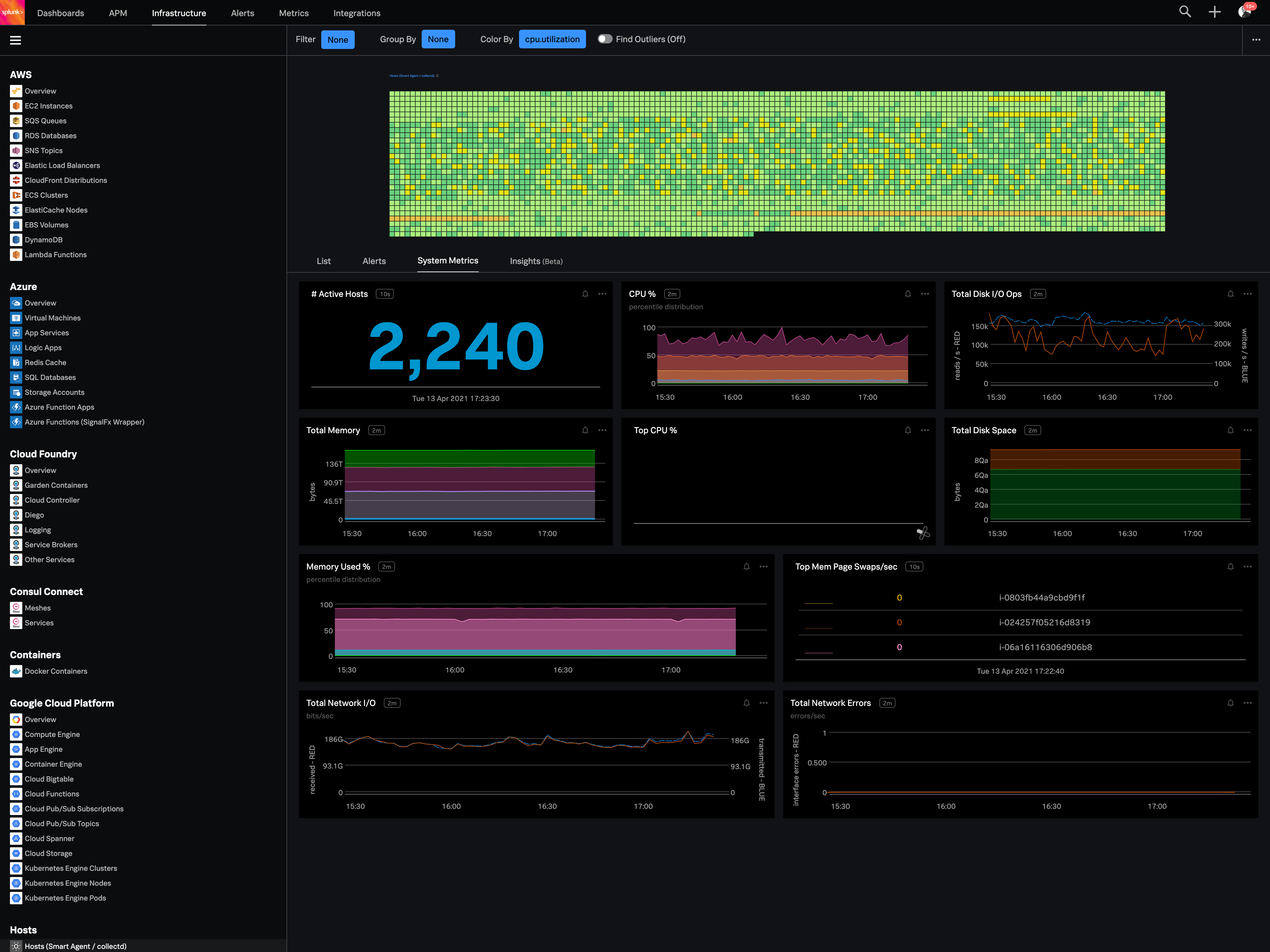
Splunk Observability Cloud
Score 8.2 out of 10
N/A
Splunk Observability Cloud aims to enable operational agility and better customer experience through real-time AI-driven streaming analytics allowing accurate alerts in seconds. It is designed to shorten MTTD and MTTR by providing real-time visibility into cloud infrastructure and services.
Solr spins up nicely and works effectively for small enterprise environments providing helpful mechanisms for fuzzy searches and facetted searching. For larger enterprises with complex business solutions you'll find the need to hire an expert Solr engineer to optimize the powerful platform to your needs. Internationalization is tricky with Solr and many hosting solutions may limit you to a latin character set.
Its great if you need real-time visibility across complex or regulated environments. Also strong for hybrid or multi-cloud setups where uptime, observability and fast IR are required. It’s probably overkill for smaller teams or environments that don’t have constant changes or compliance reporting needs. It's expensive and has a steep learning curve. Also, in my opinion, do not get yourself into a consumption based model. Costs can certainly get out of control quickly.
Easy to get started with Apache Solr. Whether it is tackling a setup issue or trying to learn some of the more advanced features, there are plenty of resources to help you out and get you going.
Performance. Apache Solr allows for a lot of custom tuning (if needed) and provides great out of the box performance for searching on large data sets.
Maintenance. After setting up Solr in a production environment there are plenty of tools provided to help you maintain and update your application. Apache Solr comes with great fault tolerance built in and has proven to be very reliable.
The first one is its Kubernetes container monitoring.
I really like this features because as we know how much K8s is vast and to manually monitor each part of the Kubernetes it takes so much time but Splunk Observability Cloud makes it easier. And even once we integrate K8s with Splunk Observability Cloud it gives us some prebuilt dashboards which gives holistic view of our Cluster and its nodes, pods, etc.
The dashbaord feature of Splunk Observability Cloud, it gives us full flexibility to customize our dashboard with a wide range of predefined chart types.
Now it also supports OTEL, which is a plus point for observability. As now everyone is moving towards Otel and in current market there are only few tools who supports OTEL based integrations, Splunk Observability Cloud is one out of them.
These examples are due to the way we use Apache Solr. I think we have had the same problems with other NoSQL databases (but perhaps not the same solution). High data volumes of data and a lot of users were the causes.
We have lot of classifications and lot of data for each classification. This gave us several problems:
First: We couldn't keep all our data in Solr. Then we have all data in our MySQL DB and searching data in Solr. So we need to be sure to update and match the 2 databases in the same time.
Second: We needed several load balanced Solr databases.
Third: We needed to update all the databases and keep old data status.
If I don't speak about problems due to our lack of experience, the main Solr problem came from frequency of updates vs validation of several database. We encountered several locks due to this (our ops team didn't want to use real clustering, so all DB weren't updated). Problem messages were not always clear and we several days to understand the problems.
You can use table-like functionality to generate dashboards, but these queries are heavy on the system.
It could be easier to give insight into what type of line parsing is used for specific documents in a company-managed environment and/or show ways to gain the insights needed.
I would like to see ways to anonymize specific data for shared reports without pre-formatting this in a dashboard on which reports could be based.
Good: Stable system with low error rate Easy to use for simple use cases Bad: UI is not very clear for complex usage Mobile view (when logged in from phone) is bad No library for .net
It takes some time to deploy and currectly maintein it. And also, to learn how to use and integrate in the enviroment as well. Once you get theses steps done, it usability is very simple, and almost of the time it don't require no further attention on it. Even for maintence, if you deploy it on a cluster mode, it is very reliable and easy to take one host down.
When there is an issue, it’s a win if one can easily identify the root cause. To do the same, it should allow the user to dig deep with multiple data points and compare the data and identify the anomaly. In this use case, it’s good to drive from Splunk 011y.
We tried to use both Elasticsearch and Swiftype with Drupal 8 but there are currently no good modules that integrate Drupal with those solutions. So Solr was really the only option for a Drupal 8 web site. It's not as easy to learn or use as Swiftype, but in the end I think it will be a little less expensive and offer more customization and flexibility.
Splunk Infrastructure Monitoring provides far superior options for anybody using a complex hybrid multi-cloud environment and allows both your SOC and NOC to work together on the same data while driving their own insights. We found other products are still in the old world view of servers and agents residing together within a single data centre, but modern apps are no longer like this.