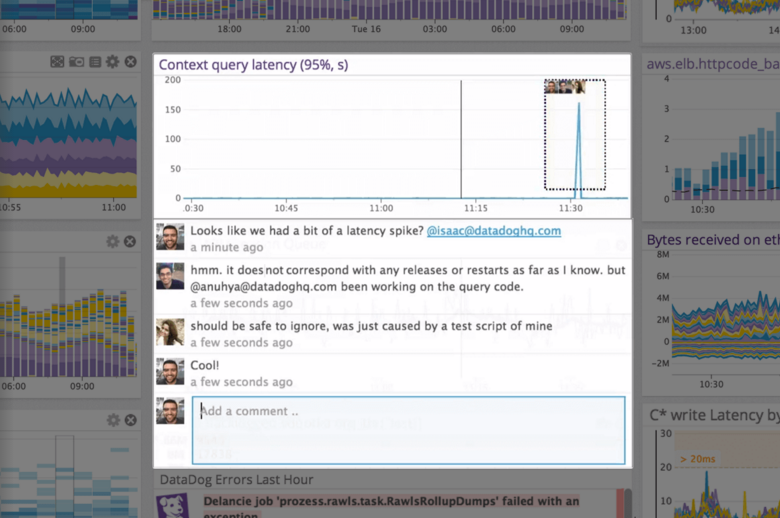
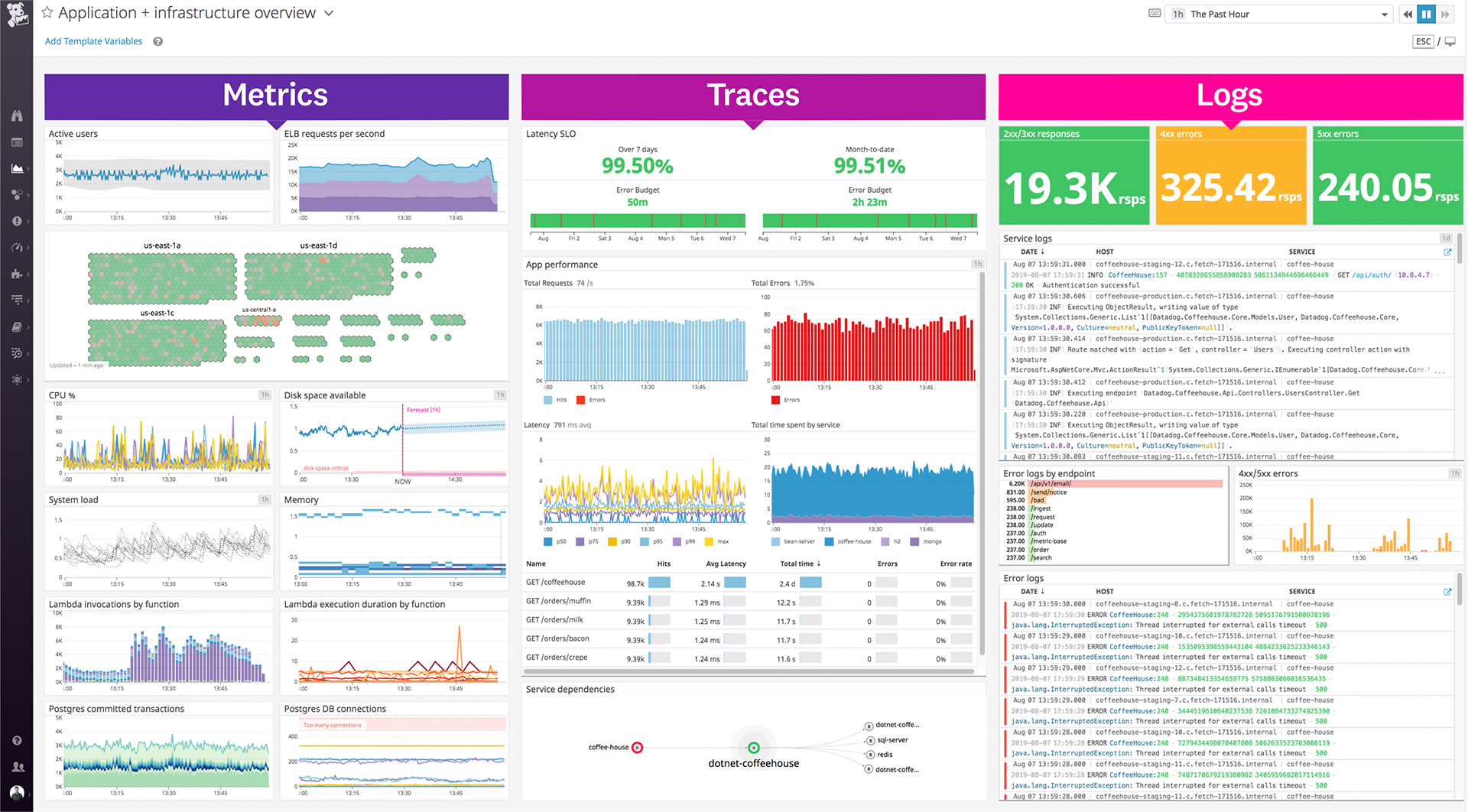
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
SolarWinds Loggly
Score 7.5 out of 10
Mid-Size Companies (51-1,000 employees)
Loggly is a cloud-based log management service provider. It does not require the use of proprietary software agents to collect log data. The service uses open source technologies, including ElasticSearch, Apache Lucene 4 and Apache Kafka.
$79
per month/billed annually
Pricing
Datadog
SolarWinds Loggly
Editions & Modules
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
Standard
$79
per month/billed annually
Pro
$159
per month/billed annually
Enterprise
$279
per month/billed annually
Offerings
Pricing Offerings
Datadog
SolarWinds Loggly
Free Trial
Yes
Yes
Free/Freemium Version
Yes
Yes
Premium Consulting/Integration Services
No
Yes
Entry-level Setup Fee
Optional
No setup fee
Additional Details
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
Free trial for Standard and Pro plans for 14 days with all features.
I actually couldn't get anybody from Datadog to engage with me, the main problem we had was that our devices couldn't connect to an encrypted port, but we didn't want to send our logs in plain text over the internet. We implemented an on-net log aggregator which then connects …
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
SolarWinds Loggly is great for capturing and organizing logs from 3rd party sources such as NGINX. Without SolarWinds Loggly it's really difficult to manage the logs overtime, find traffic patterns, and identify issues before they become a problem. Anyone who is routinely searching through massive log files could quickly benefit from the SolarWinds Loggly and it's capabilities.
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Putting our logs in one place and making them searchable. We use AWS, and CloudWatch has always been a little frustrating in this regard (though it has gotten better recently).
Deriving metrics from our logs. I think log-based metrics is such a good idea because your logs are the ultimate source for truth in regards to what the hell is going on inside your app. I have really loved the simplicity with which I can just count certain statements and call that a metric because just through the normal course of development certain log statements just naturally become a straightforward recording of an event having occurred.
Alerts. I actually have a few complaints about email alerts, but just the way I was able to set them up so easily has been huge. Since we started using Loggly, there have been at least 3 bugs that Loggly exposed that were frankly very bad. And withoutt Loggly or without a user reporting them, we would have never known they were happening! This is stuff I tried to set up in CloudWatch in various ways, but because of my own ignorance or perhaps the complexity/limitations of CloudWatch (or the complexity of my stack?), I wasn't getting the information that I needed until I was able to just tell Loggly to send me an email whenever the word "error" showed up.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
We have to use a log aggregating device to ship our logs to Loggly as our network devices can not connect on an encrypted protocol. I would prefer if we could use some sort of VPN-based connector to ship logs securely.
Sometimes when drilled down, it can be difficult to fully reset a search term to back all the way out of a drill down.
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
Loggly's easy setup, very good customer support, and intuitive interface make Loggly very easy to use. User access management is also very easy as we can tailor the experience for each of our developers to access the information they need without having to wade through other information. While there was a slight learning curve in how to view the logs the way some specifically wanted, everything was possible and quite easy to do.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
The support team have been great when we have logged tickets or had issues, most of the time it is down to user training, however we have had a couple of bugs that they have been able to iron out for us.
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
We were using Zabbix. While it is an open-source solution that you can install for free the following things were limitations of the solution. 1) The scale and uptime of the solution are now your own problem. Since we were hosting at AWS this meant we still had a cost of the AWS solution. 2) The product is complicated from a configuration standpoint. In order to get anything meaningful out of it, you had to invest a lot of time and effort. We did consider NewRelic. I have experience with that product and do think that it is a solid alternative. Ultimately experience with the simplicity and speed of deployment with Loggly encouraged me to suggest using this again.
Unfortunately, we hit our logging cap on a weekly basis and we lose logs after that.
We have lost logs after hitting the maximum during service outages. We have become accustomed to not being able to rely on having them, then things go poorly.