Chose Datadog
Its the Enterprise level decision, definitely usability and features perspective Datadog is much more advanced.
| Product | Rating | Most Used By | Product Summary | Starting Price |
|---|---|---|---|---|
 Datadog | N/A | Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight. | $1.27 per month (billed annually) per host | |
 Splunk Observability Cloud | N/A | Splunk Observability Cloud aims to enable operational agility and better customer experience through real-time AI-driven streaming analytics allowing accurate alerts in seconds. It is designed to shorten MTTD and MTTR by providing real-time visibility into cloud infrastructure and services. | $15 per month (billed annually) per host |
| Datadog | Splunk Observability Cloud | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Editions & Modules |
|
| ||||||||||||||
| Offerings |
| |||||||||||||||
| Entry-level Setup Fee | Optional | No setup fee | ||||||||||||||
| Additional Details | Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo). | — | ||||||||||||||
| More Pricing Information | ||||||||||||||||
| Datadog | Splunk Observability Cloud | |
|---|---|---|
| Considered Both Products |  Datadog  Jeffrey van Santen Sr SWE Chose Datadog Datadog is a more complex but complete solution than any of the other Log Aggregation, monitoring, or general observabilty tools that we have trialed. I found it easier to setup following useful and up-to-date documentation provided directly by Datadog instead of scattered …  Vinit Parakh Sr. DevOps Engineer Chose Datadog First think first - it's easy to use, and very easy to implement in any infrastructure. It provides a custom dashboard and monitors. I’ve used or evaluated Grafana, Prometheus, Amazon CloudWatch, and Dynatrace, and each tool has strong capabilities. Prometheus + Grafana provide …  Joe Cardali Head of Engineering Chose Datadog Much more modern and advanced  Fernando Battistella DevOps Engineer Chose Datadog ease of use and implementation, other than new relic (which I think is terrible in every possible way), the other two support opentelemetry better, have more manageable costs and comparable basic services, but they do not have the breadt of services dd does. |  Splunk Observability Cloud  Dhaval Bhalgamadiya Devops Engineer Chose Splunk Observability Cloud Datadog pushes intom proprietary ecosystem and pricing structure.Compared to self hosted prometheus and grafarna but it gave headache og managing our own monitoring infrastructure at scale.Prometheus is excellent for scraping cluster metrics but it doesnt handle distributed …  Ruben Martinez Information Systems Security Officer Chose Splunk Observability Cloud It's able to quickly detect and resolve issues across the entire spectrum of deployments including on-premises, public cloud, private cloud, hybrid cloud and multicloud  Brennan Fuller Systems Engineer Chose Splunk Observability Cloud Splunk is superior in many ways to these solutions when I'm comes to ingesting, storing, manipulating, and using data, but dynatraces automatic agents do make it much easier to use out of the box. Nagios seems much cheaper but does not provide as much functionality as Splunk. …  Giuseppe Cusello GRC Director Chose Splunk Observability Cloud Splunk requires less work for data in gestion and parsing. Splunk has more efficient data display features.  Mayank Thirani Senior Software Engineer Chose Splunk Observability Cloud Splunk Log Observer provides easy setup and ease of admin features and direction of product was better compared to Lightstep  Anuj Rai Performance Engineer Chose Splunk Observability Cloud We are having other monitoring tools like AppDynamics, Dynatrace, Datadog and already using their end-user monitoring capability. Most of our customers are looking for agent-free monitoring where they don't want to instrument any agent on their client-side (as it might …  David Williams CIO (Chief Information Officer) Chose Splunk Observability Cloud Splunk Infrastructure Monitoring provides far superior options for anybody using a complex hybrid multi-cloud environment and allows both your SOC and NOC to work together on the same data while driving their own insights. We found other products are still in the old world view … |
| Datadog | Splunk Observability Cloud | |
|---|---|---|
| Small Businesses |  Amazon CloudWatch Score 7.7 out of 10 | Amazon CloudWatch Score 7.7 out of 10 |
| Medium-sized Companies |  ManageEngine Site24x7 Score 10.0 out of 10 | ManageEngine Site24x7 Score 10.0 out of 10 |
| Enterprises | ManageEngine Site24x7 Score 10.0 out of 10 | ManageEngine Site24x7 Score 10.0 out of 10 |
| All Alternatives | View all alternatives | View all alternatives |
| Datadog | Splunk Observability Cloud | |
|---|---|---|
| Likelihood to Recommend | 8.9 (0 ratings) | 7.8 (0 ratings) |
| Likelihood to Renew | 1.0 (0 ratings) | 9.0 (0 ratings) |
| Usability | 8.7 (0 ratings) | 7.6 (0 ratings) |
| Support Rating | 5.0 (0 ratings) | 10.0 (0 ratings) |
| Implementation Rating | 1.0 (0 ratings) | 10.0 (0 ratings) |
| Datadog | Splunk Observability Cloud | |
|---|---|---|
| Likelihood to Recommend |
|
|
| Pros |
 Aman Makwana DevOps Engineer |
|
| Cons |
|
|
| Likelihood to Renew |
|
|
| Usability |
|
 John Abraham Director of Information Systems - ACOM |
| Support Rating |
|
Giuseppe Cusello GRC Director |
| Implementation Rating |
|
Giuseppe Cusello GRC Director |
| Alternatives Considered |
Jeffrey van Santen Sr SWE | |
| Return on Investment |
|
|
| ScreenShots | Datadog Screenshots 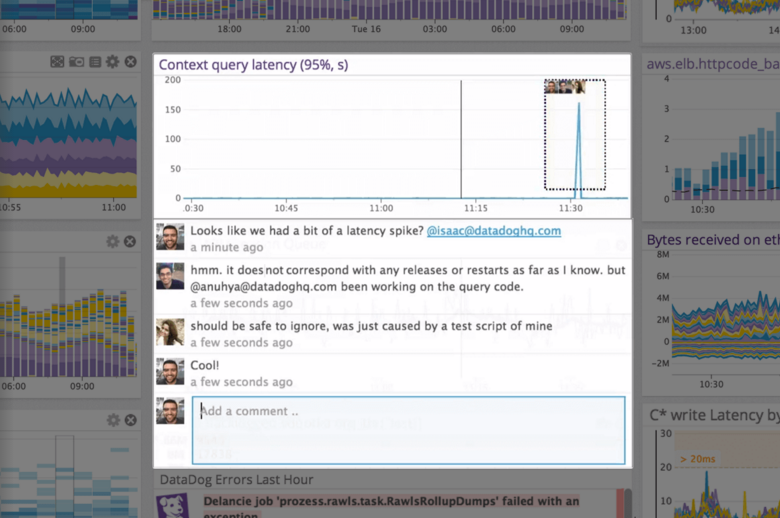 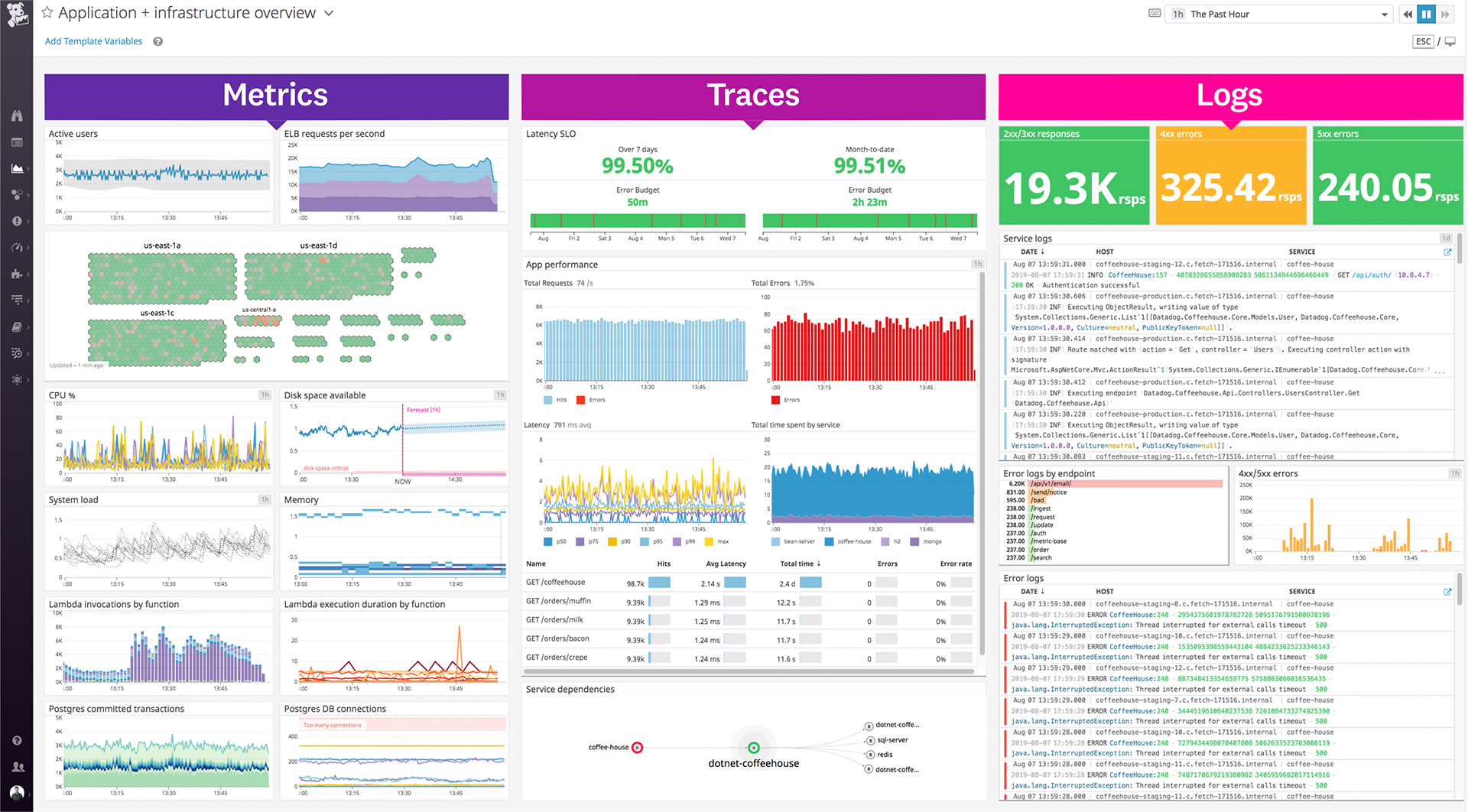    | Splunk Observability Cloud Screenshots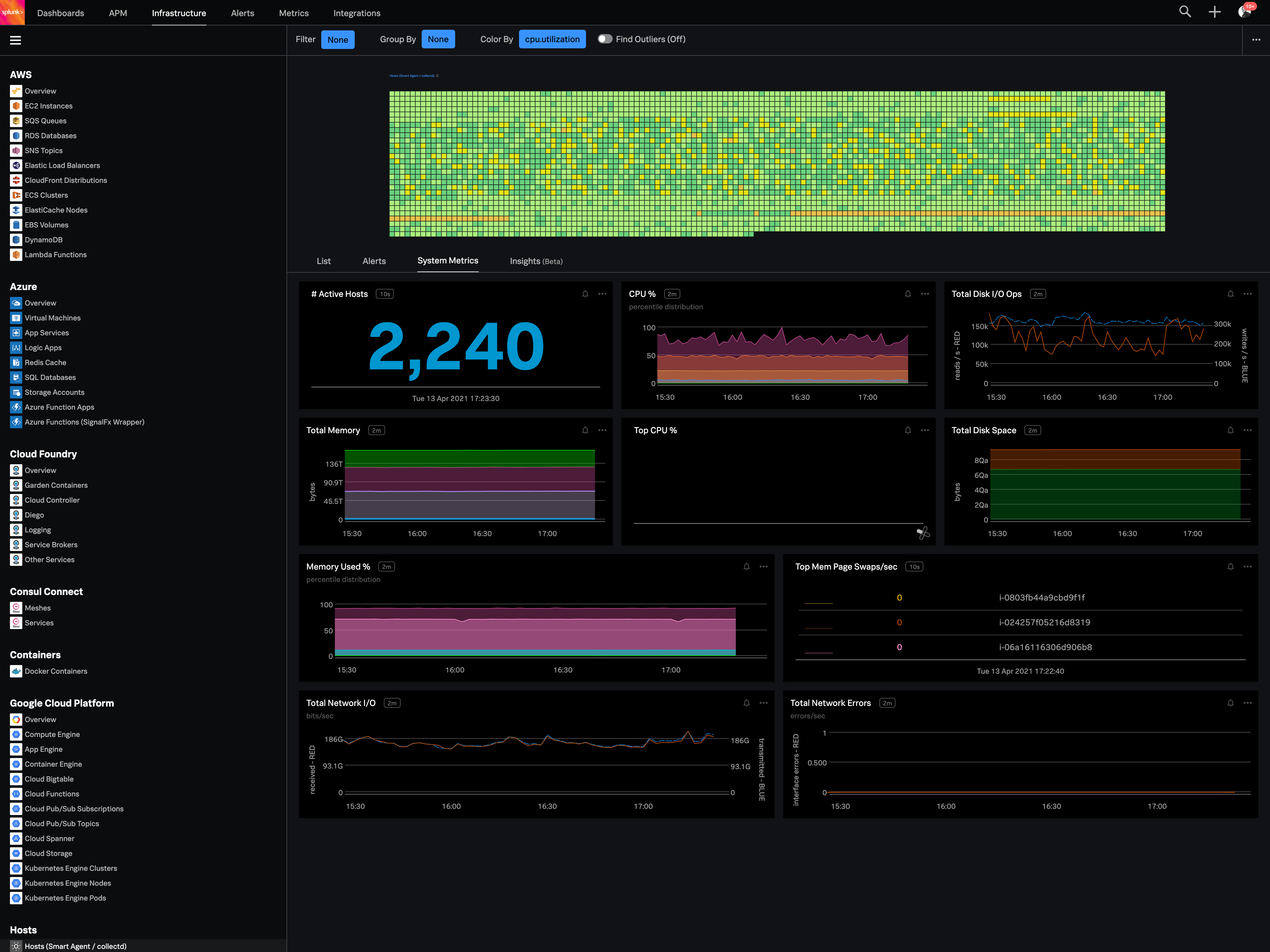 |