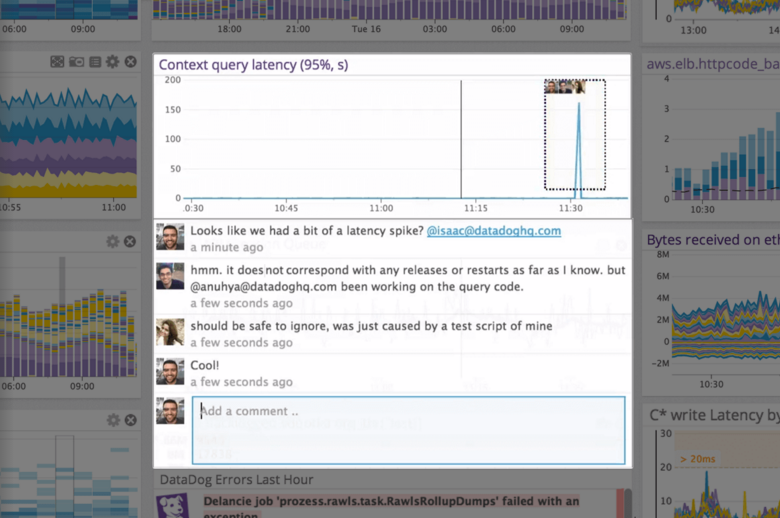
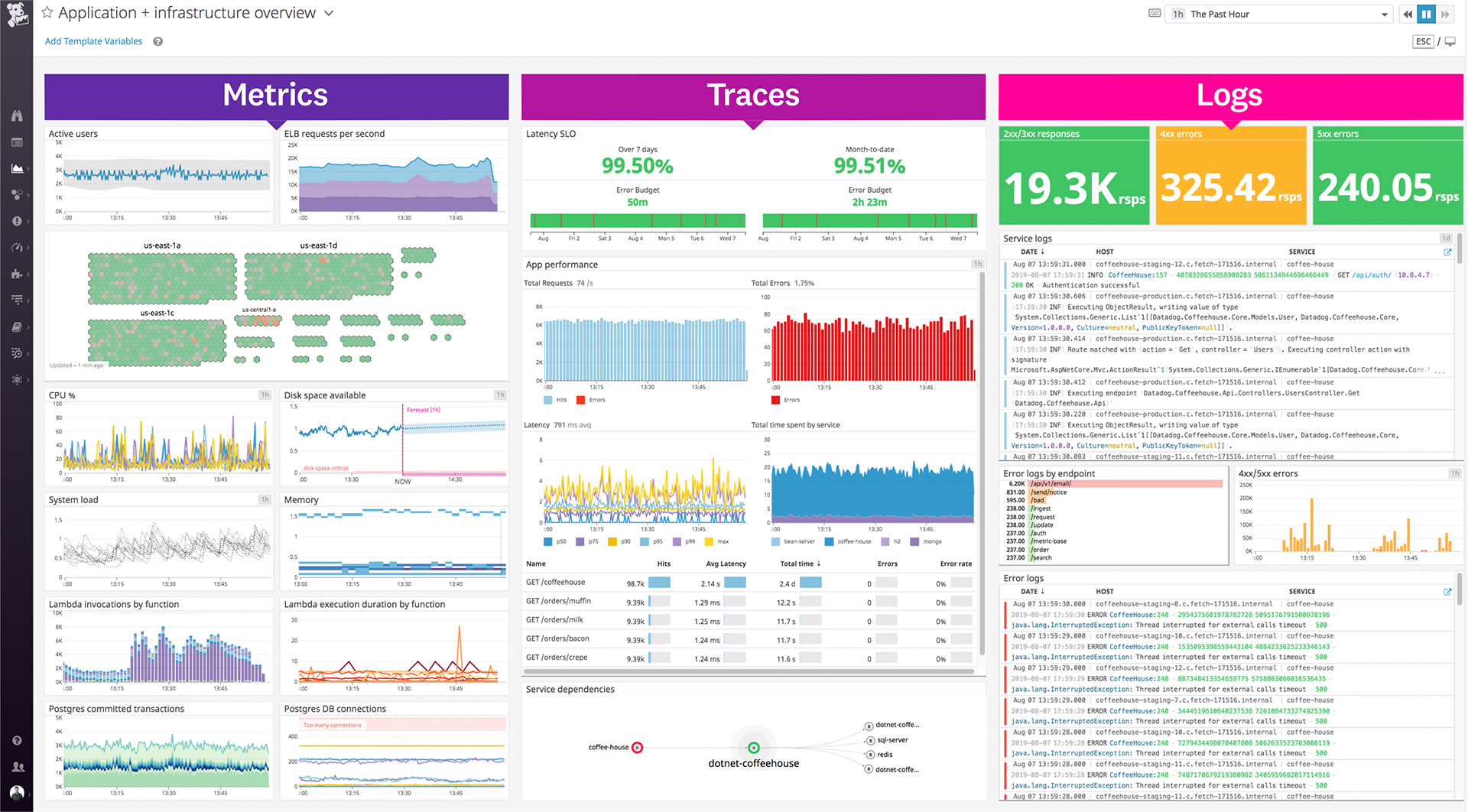
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
PRTG
Score 8.5 out of 10
N/A
PRTG Network Monitor is the flagship offering from German software company Paessler, for monitoring local and wide area networks (LANs & WANs), servers, websites, apps, and more.
$2,149
per year
Pricing
Datadog
PRTG Network Monitor
Editions & Modules
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
PRTG 500
$2,149
per year
Hosted 500
$2,149
per year
PRTG 1,000
$3,899
per year
Hosted 1000
$3,899
per year
PRTG 2,500
$8,099
per year
Hosted 2500
$8,099
per year
PRTG 5,000
$14,199
per year
Hosted 5000
$14,199
per year
PRTG 10000
$17,899
per year
PRTG Enterprise
Custom Pricing
subscription license
Offerings
Pricing Offerings
Datadog
PRTG
Free Trial
Yes
Yes
Free/Freemium Version
Yes
No
Premium Consulting/Integration Services
No
Yes
Entry-level Setup Fee
Optional
No setup fee
Additional Details
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
PRTG wins on price. Other tools have similar capabilities. However, there was always some trade-off to make. Products like Zabbix and Nagios are overly complicated to configure, so there is a significant time cost. Tools like Datadog and OpManager just cost too much for a small …
Each tool that we evaluated had their benefits. For a company our size, we were look at something simple, easy to manage, and fast to get started with. PRTG Network Monitor fit that bill the best. If we needed more than just the monitoring, we could potentially choose something …
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
integrates seamlessly with Windows servers via WMI and PowerShell, providing deep insights into resource usage, performance metrics, and system health. It's excellent at tracking CPU, memory, disk space, and event logs, enabling rapid troubleshooting and proactive maintenance. PRTG Network Monitor also effectively monitors Fortigate devices, providing detailed data on firewall health, traffic patterns, bandwidth utilization, VPN status, and security alerts. This visibility helps detect and resolve network security issues promptly.
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
Licensing on a per entity basis can be cumbersome for devices which have a ton of monitoring points like network switches\routers. Each sensor may count against a license, which could be a lot of you were monitoring every TX\RX of an SFP for example
A better method to easily template\copy monitors across devices
The navigation in the web GUI could be a little more straightforward in terms of the hierarchy
I would renew it because the platform has brought us many technical and economic benefits that make the cost-benefit ratio very good. Additionally, to do so does not require large investments in training, licensing or infrastructure, and at the administration level, extensive knowledge is not required to be able to bear it.
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
The tool is very intuitive to use and it is Windows-based (everybody knows how to use Windows) so it's easy to get into. Every time is setup in a hierarchy so if you have a good initial hierarchy design, it will really reduce administrative effort down the road.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
PRTG does everything we need it to do and more. Ease of use, ease of management and maintenance and clarity of monitoring of hundreds of different types of device and service gives this a large advantage over other products on the market that I have tried. I would definitely recommend it to anyone who needs a network monitoring product in their environment and even to people who don't know they need a solution yet!
It's very important that de project's teams have different member of the TI. We have learned too late the importa of Security Analyst at the design architecture moment. We have to rebuild part of the implementation for made this big mistake.
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
PRTG offers more versatility in monitoring when compared to the other solutions we tested. The other solutions were also limited as far as customization options, which made them less adaptable to our networks. When compared to Auvik, for instance, we prefer PRTG as it offers immediate notifications through the desktop client - not limited to email notifications as with Auvik. We also appreciate the fact that PRTG can be self/on-prem hosted vs Auvik's cloud model. This makes for an easier deployment and less firewall adjustments to allow traffic to cloud-hosted solutions.
The ability to analyze multiple pieces of information in one place, especially with historical data, has saved our IT department time and headaches. It would be so much more difficult to trace an issue without PRTG, just relying on event logs and an open task manager window.
The cost is not cheap, so it's an expense that hits the bottom line like everything else. Figure in hardware costs as well, ideally a server outside of your main environment.
I keep saying this, but the historical data piece is worth so much. There's really no good way to collect all of that information in one place without something like PRTG. And that definitely saves time and money in the long run.