Dynatrace is an APM scaled for enterprises with cloud, on-premise, and hybrid application and SaaS monitoring. Dynatrace uses AI-supported algorithms to provide continual APM self-learning and predictive alerts for proactive issue resolution.
$0
per synthetic request
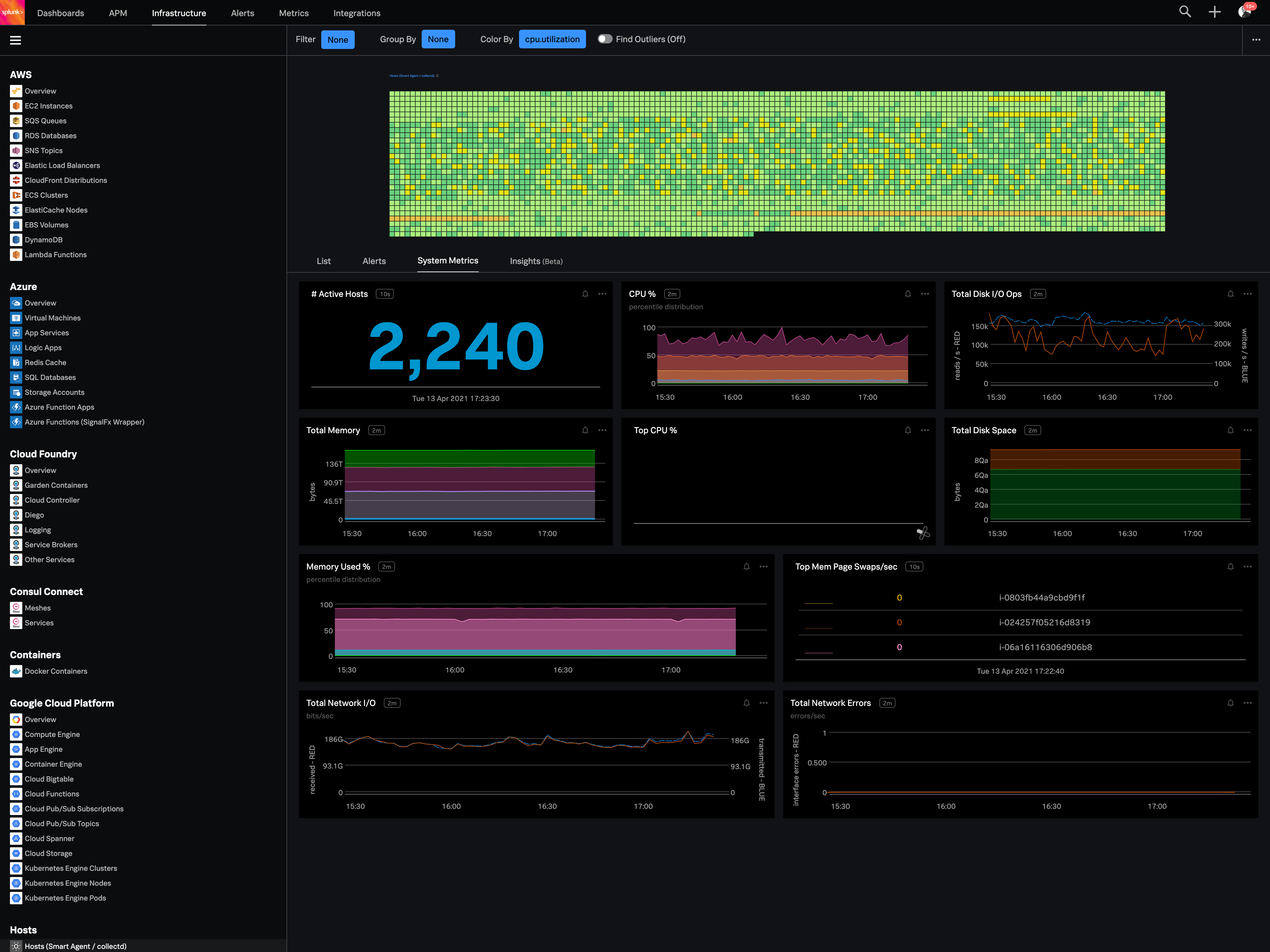
Splunk Observability Cloud
Score 8.4 out of 10
N/A
Splunk Observability Cloud aims to enable operational agility and better customer experience through real-time AI-driven streaming analytics allowing accurate alerts in seconds. It is designed to shorten MTTD and MTTR by providing real-time visibility into cloud infrastructure and services.
Splunk is superior in many ways to these solutions when I'm comes to ingesting, storing, manipulating, and using data, but dynatraces automatic agents do make it much easier to use out of the box. Nagios seems much cheaper but does not provide as much functionality as Splunk. …
I selected Splunk Observability Cloud because it focused so much on OTEL standards which will help us in future as OTEL is covering most of the observability standards. And also it has the best Kubernetes observability as I already explained it has several predefined dashboards …
The use of a single integration and definition of custom metrics, and tags is a great advantage. The ability to use SignalFlow to observe metrics in addition to the vast number of out-of-the-box dashboards is also excellent.
Dynatrace is well suited to a number of tasks. It is important to determine who the end users are and gather good information to tailor their experience accordingly. For instance, business/marketing should not have access to some of the more technical data, and business metrics can be a distraction for IT operations personnel.
Its great if you need real-time visibility across complex or regulated environments. Also strong for hybrid or multi-cloud setups where uptime, observability and fast IR are required. It’s probably overkill for smaller teams or environments that don’t have constant changes or compliance reporting needs. It's expensive and has a steep learning curve. Also, in my opinion, do not get yourself into a consumption based model. Costs can certainly get out of control quickly.
We loved Dynatrace's ability to show the data flow - from the front end points through the back end points straight to the database and various API's. It was advanced in its data visualization. This is useful for debugging - showing when/where the errors are. It can even enable non-technical individuals in the corporation to help debug
Dynatrace has some great highly customizable integration options as well as monitoring. You can configure your layout & integration options to create custom monitoring alerts for your applications performance. Further you can increase the extensibility of using a REST API on your architecture.
Some advanced dev-ops systems are utilizing Kubernetes/docker aswell as Node.JS - Dynatrace was able to log and help understand all of our dev-ops needs. It gave us native alerts based off of deviations from the baseline that we set during initial configuration. These metrics are priceless.
The first one is its Kubernetes container monitoring.
I really like this features because as we know how much K8s is vast and to manually monitor each part of the Kubernetes it takes so much time but Splunk Observability Cloud makes it easier. And even once we integrate K8s with Splunk Observability Cloud it gives us some prebuilt dashboards which gives holistic view of our Cluster and its nodes, pods, etc.
The dashbaord feature of Splunk Observability Cloud, it gives us full flexibility to customize our dashboard with a wide range of predefined chart types.
Now it also supports OTEL, which is a plus point for observability. As now everyone is moving towards Otel and in current market there are only few tools who supports OTEL based integrations, Splunk Observability Cloud is one out of them.
Dynatrace does not monitor easily on a C-based application.
The way DPGR is addressed by Dynatrace is not very complete, and not clear. One thing is to mask the IP and request attributes but is not enough, the replay session feature is great but raises serious questions about user tracking.
You can use table-like functionality to generate dashboards, but these queries are heavy on the system.
It could be easier to give insight into what type of line parsing is used for specific documents in a company-managed environment and/or show ways to gain the insights needed.
I would like to see ways to anonymize specific data for shared reports without pre-formatting this in a dashboard on which reports could be based.
We have already renewed our purchase with the company. They make it easy for us to get a temporary license for our contingency site that is only used for testing twice a year. We are expanding our license with for this tool. We find it very useful and will renew it again.
Good: Stable system with low error rate Easy to use for simple use cases Bad: UI is not very clear for complex usage Mobile view (when logged in from phone) is bad No library for .net
Dynatrace is great to use once you understand how to use it correctly and get used to the layout of it. While I do not actively use it every day, whenever I do use it, I do have to get refamiliarized with it. However, once you have your dashboards setup correctly with the data that you want to see when you first login to Dynatrace, it's amazing.
When there is an issue, it’s a win if one can easily identify the root cause. To do the same, it should allow the user to dig deep with multiple data points and compare the data and identify the anomaly. In this use case, it’s good to drive from Splunk 011y.
Given that Dynatrace has become an informal industry standard, the plethora of information available on forums is massive. Most problems or roadblocks you come across are most likely (almost certainly, in fact) already solved and solutions available on these forums. The tech support at Dynatrace is also quite good, with prompt and knowledgeable people at their end.
Synthetic Monitoring automatically does what other products do only through the use of other tools or through the development of user applications that still have a high cost of maintenance. The other products are not immediately usable and require many customizations. Through the use of configuration automatisms, you can be immediately operational and, in our case, we detected several imperfections in the applications.
Splunk Infrastructure Monitoring provides far superior options for anybody using a complex hybrid multi-cloud environment and allows both your SOC and NOC to work together on the same data while driving their own insights. We found other products are still in the old world view of servers and agents residing together within a single data centre, but modern apps are no longer like this.