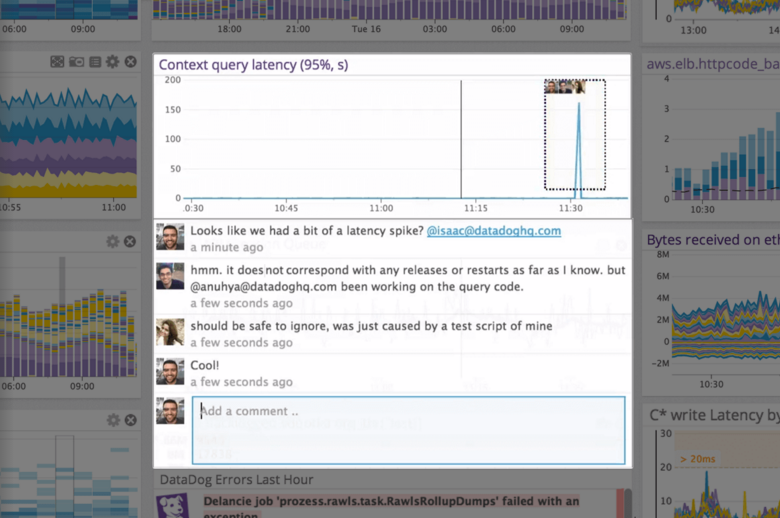
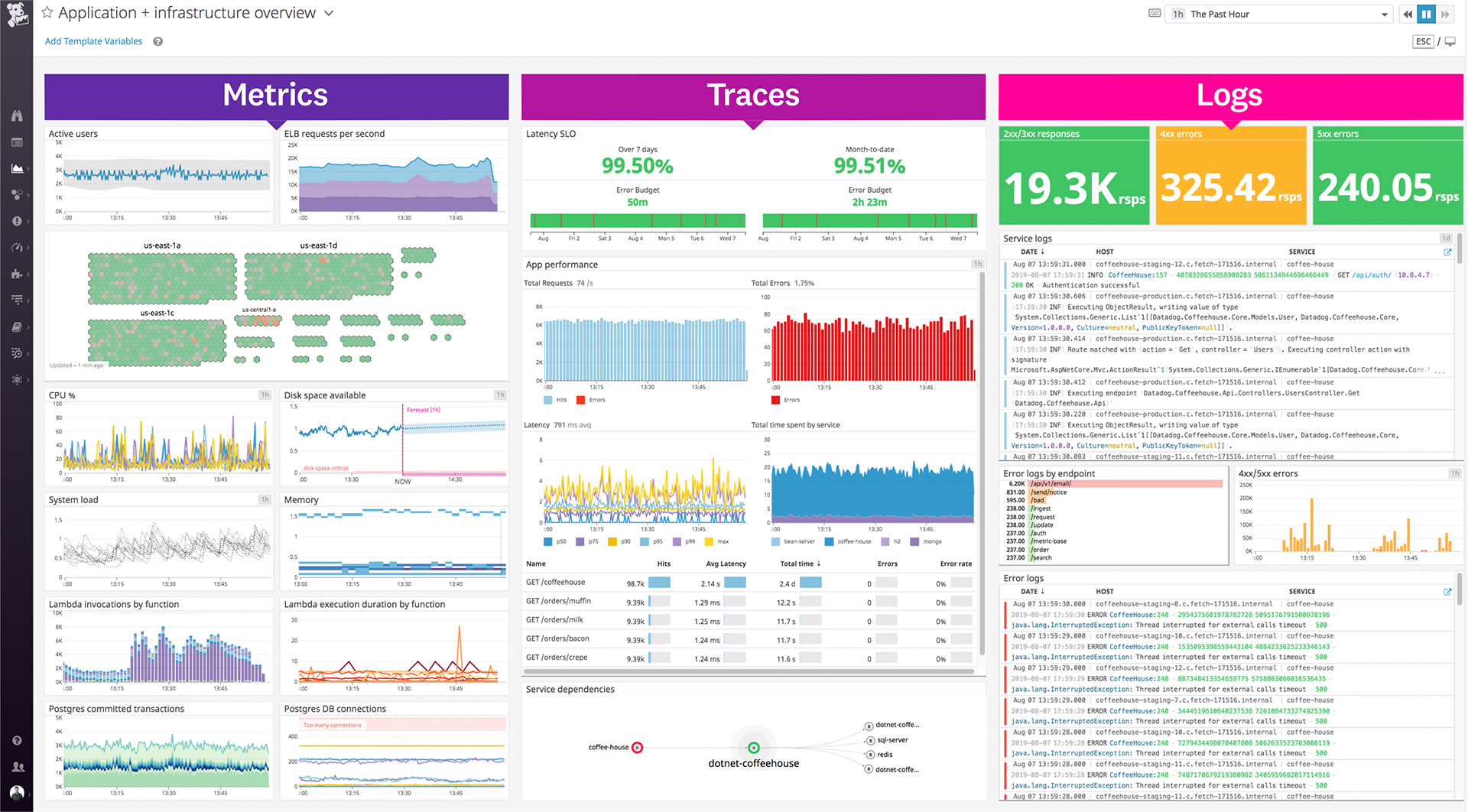
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
Icinga
Score 8.8 out of 10
N/A
Icinga is an open source network monitoring platform. It includes automation, modularized integration packages, and prebuilt alerts and reporting capabilities.
N/A
Prometheus
Score 8.0 out of 10
N/A
Prometheus is a service monitoring and time series database, which is open source.
N/A
Pricing
Datadog
Icinga
Prometheus
Editions & Modules
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
No answers on this topic
No answers on this topic
Offerings
Pricing Offerings
Datadog
Icinga
Prometheus
Free Trial
Yes
No
No
Free/Freemium Version
Yes
No
No
Premium Consulting/Integration Services
No
No
No
Entry-level Setup Fee
Optional
No setup fee
No setup fee
Additional Details
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
Dynatrace was cheaper but, in my opinion, its setup, features, and overall user experience do not come close to what Datadog can offer, making it more of a pain to use and not worth the cheaper cost over Datadog (especially if migrating away from Datadog to Dynatrace).
we primarily use Kubernetes, and Prometheus is great for collecting time series metrics, especially in Kubernetes. and Grafana is used for dashboards. As these are open source, we host them and manage them internally. We choose Datadog because of its logs, traces, and …
First think first - it's easy to use, and very easy to implement in any infrastructure. It provides a custom dashboard and monitors. I’ve used or evaluated Grafana, Prometheus, Amazon CloudWatch, and Dynatrace, and each tool has strong capabilities. Prometheus + Grafana provide …
I use Datadog because it concentrates all these features into a single tool, facilitating the learning curve that my platform and development engineering team needs in order to be able to set up the monitors/alerts/SLIs/SLOs as well as to diagnose a production issue. Its easier …
Datadog is best for cloud-native and fast-setup. It is more mature for infrastructure and real-time observability. The UI is more user-friendly and provides wide coverage of app insights.
All other tools dont have all the features which Datadog provides. Easy to use from UI where other may have complicated UI or no UI at all to create monitors. Consider like AWS Grafana, we have limitation to create monitors from UI. There is no recurring downtime for monitors. …
Datadog empowers us to create dashboards and visualize the state of our infrastructure in real time. It gives us control over what we want to view and how. The graphs provide deep insight into trends and anamoly detectives. These features are lacking in some of the other …
While Icinga holds its own against old stalwarts like Nagios and Zabbix, it simply can't compete with the new generation of SaaS service/server monitoring software in terms of ease of use, feature-completeness, integration with things like Cloudwatch, CloudHealth, New Relic, …
We evaluated Datadog and New Relic but cost-wise, these 2 are very expensive. Prometheus does require more leg work to match the feature sets but other than time, the cost is free. Pairing with Grafana, Prometheus can pretty much match features with the big players and still …
It is easier to setup, but learning curve is quite moderately steep. Prometheus is a best-in-class tool for engineers and SREs in cloud-native environments. When extended with tools like Thanos or Cortex, it can rival commercial platforms in scale and capability—but requires …
As I mentioned earlier, Prometheus had an added advantage that we were able to monitor CPU, RAM, Disk Space, process monitoring which other tools did not provide us Some tools were obsolete, and other were costly when we wanted this good feature , only Prometheus delivered on …
Highly customized pricing plans to choose from. Lower pricing for the same features compared to competitors. Easy to reach the support team, which provided detailed documentation and helped set up the Prometheus. Monitoring metrics gets very easy after the integration with …
Since Prometheus is free to use and provides all the features we required we went with Prometheus if any feature is missing then we can consider other paid solutions like data dog.
Prometheus is cheaper, and you can quickly set it up compared to others. It is integrated with most of the open-source monitoring and alerting tools and can help small companies in having a cost-effective solution early in their stage.
Prometheus is similar to some of its competitors but delivers with regards to metrics; being used internally by Google and other cloud-native companies like ours gives us the confidence that the alerting industry stakeholders view it as a long-term solution that the community …
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
Icinga is a world-class monitoring system. It can be used for most general monitoring situations. It is not a silver bullet, however, and there are instances where domain-specific monitoring systems are necessary. However, the output from those monitoring systems can be funneled into Icinga as a central monitoring and alerting system.
This program works from the roots of the problem and creates a professional matrix for each of its users. This will give them more skills and resources to carry out tasks and reduce the difficulties of operating each of the processes of my work, as well as being An ally for the manipulation and operability of all your master data; Prometheus is very easy to recommend since it is a program that fulfills its mission.
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
Customer Service: since this is an open-source tool, customer service is not that great. Generally, you get all answers to your problems in online forums, but in case you got stuck, nobody will assist you in a channelised manner. You will have to find the way out on your own, and it may become frustrating at times.
More metrics for dashboards shall be added per the application being monitored. Standards metrics will work in most cases but may not in specific applications. Therefore, customised metrics shall be created for some of the industry-standard niche applications.
Icinga is a solid solution which does everything it promises. It is backwards compatible with most Nagios instances, making the transition very easy. Once you get the hang of installing new plugins and editing configuration files expanding its monitoring capabilities are easy.
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
It is usable and one can learn if few people in the team are already using it. It can be difficult to understand at the beginning because of non intuitive UI and syntax of the rules. So, I've gone for 7 points as there is some room for improvement in user interface and rules syntax.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
Icinga is better than Nagios because of its nicer user interface. New Relic can monitor CPU/memory and disk usage, but it's more of a performance and application troubleshooting tool rather than monitoring
Highly customized pricing plans to choose from. Lower pricing for the same features compared to competitors. Easy to reach the support team, which provided detailed documentation and helped set up the Prometheus. Monitoring metrics gets very easy after the integration with Grafana. It also has a sophisticated alert setting mechanism to ensure we don't miss anything critical.
The ROI mentioned during the purchase has not been achieved, however this could be due to lack of data from our side. 2 years of implementation is too early to calculate and confirm the ROI.