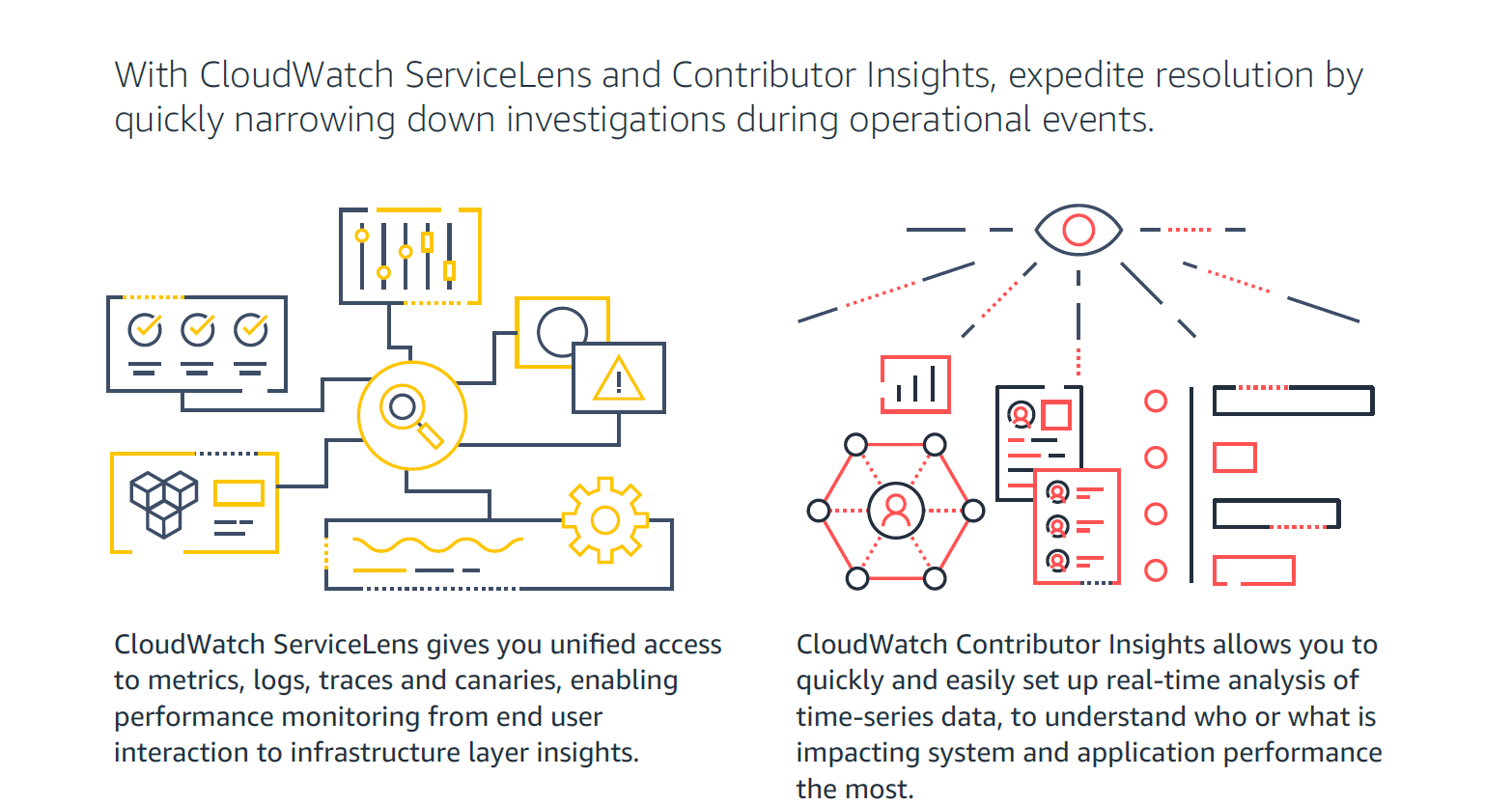
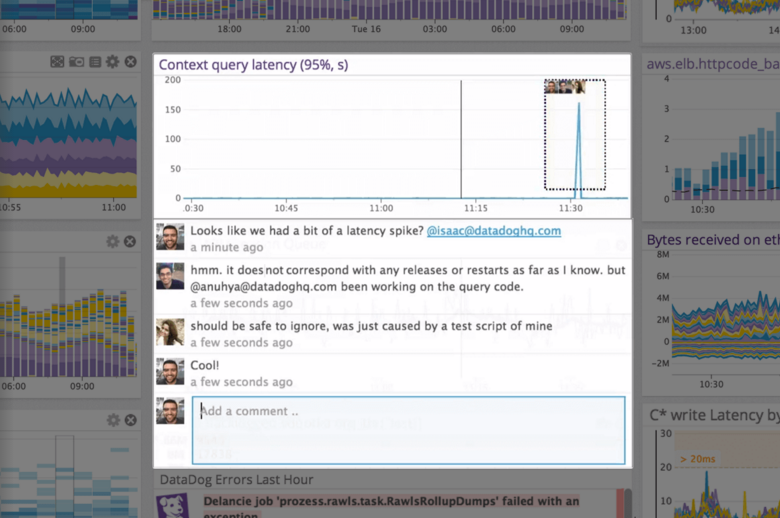
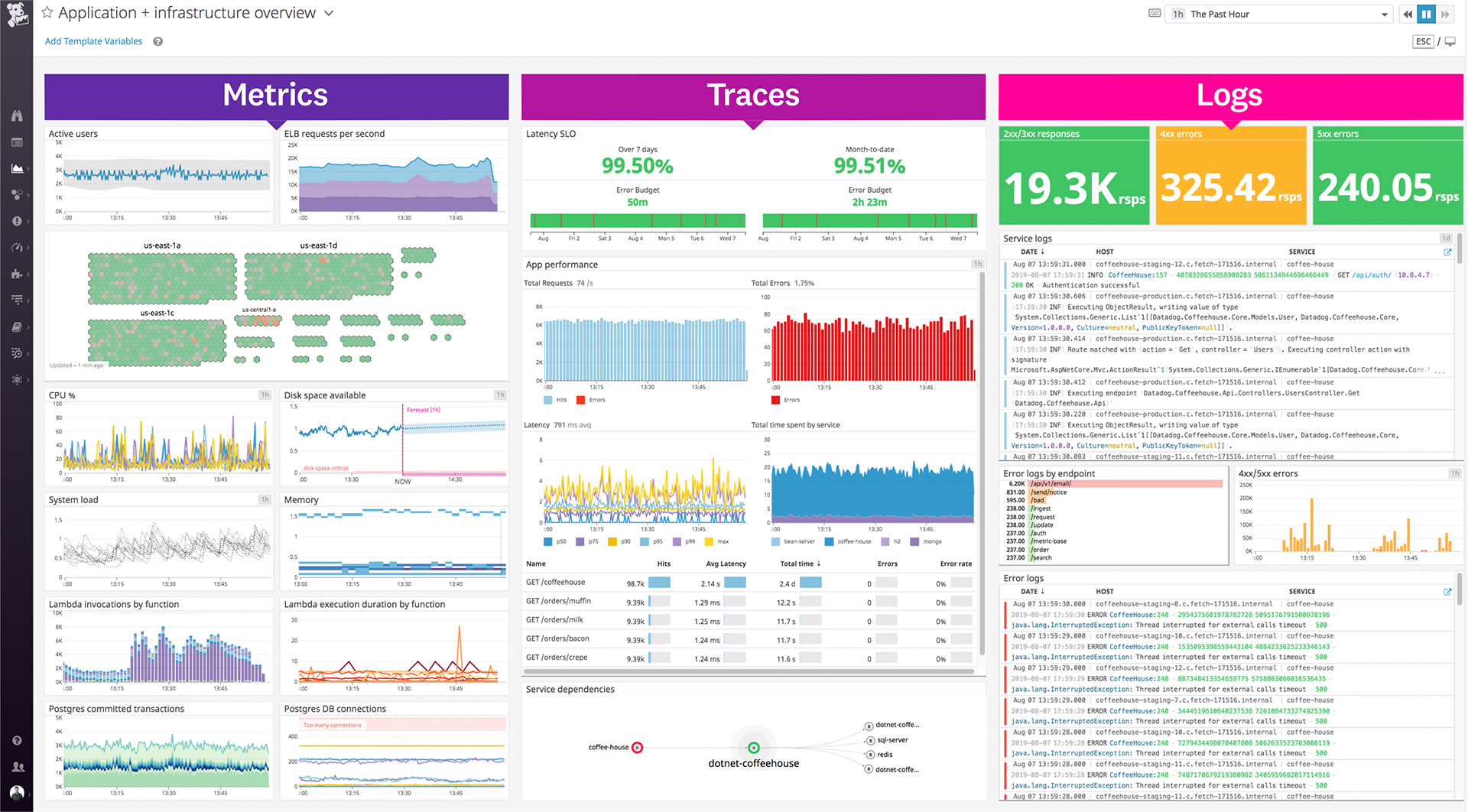
Amazon CloudWatch is a native AWS monitoring tool for AWS programs. It provides data collection and resource monitoring capabilities.
$0
per canary run
Cisco ThousandEyes
Score 8.9 out of 10
N/A
Cisco ThousandEyes empowers organizations to assure every digital experience across every network, everywhere, every time.
N/A
Datadog
Score 8.6 out of 10
N/A
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
Pricing
Amazon CloudWatch
Cisco ThousandEyes
Datadog
Editions & Modules
Canaries
$0.0012
per canary run
Logs - Analyze (Logs Insights queries)
$0.005
per GB of data scanned
Over 1,000,000 Metrics
$0.02
per month
Contributor Insights - Matched Log Events
$0.02
per month per one million log events that match the rule
Logs - Store (Archival)
$0.03
per GB
Next 750,000 Metrics
$0.05
per month
Next 240,000 Metrics
$0.10
per month
Alarm - Standard Resolution (60 Sec)
$0.10
per month per alarm metric
First 10,000 Metrics
$0.30
per month
Alarm - High Resolution (10 Sec)
$0.30
per month per alarm metric
Alarm - Composite
$0.50
per month per alarm
Logs - Collect (Data Ingestion)
$0.50
per GB
Contributor Insights
$0.50
per month per rule
Events - Custom
$1.00
per million events
Events - Cross-account
$1.00
per million events
CloudWatch RUM
$1
per 100k events
Dashboard
$3.00
per month per dashboard
CloudWatch Evidently - Events
$5
per 1 million events
CloudWatch Evidently - Analysis Units
$7.50
per 1 million analysis units
No answers on this topic
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
Offerings
Pricing Offerings
Amazon CloudWatch
Cisco ThousandEyes
Datadog
Free Trial
Yes
Yes
Yes
Free/Freemium Version
Yes
No
Yes
Premium Consulting/Integration Services
Yes
Yes
No
Entry-level Setup Fee
No setup fee
Optional
Optional
Additional Details
With Amazon CloudWatch, there is no up-front commitment or minimum fee; you simply pay for what you use. You will be charged at the end of the month for your usage.
—
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
CloudWatch's log search features are impoverished compared to PaperTrail's or Loggly's. However, CloudWatch aggregates logs from Lambda, ECS, API Gateway and more out-of-the-box. You do not need to manage anything. You do not need to worry about an errant logging configuration …
As CloudWatch is integrated into AWS already, its ready to go. External products such as Nagios require a fair bit of work to actually get the metrics into the dashboards. Products like SolarWinds and Datadog provide quite a high level of very easy integration which allows for …
Amazon CloudWatch is fully integrated into your existing AWS account, and provides easy hooks into several different services to make a cohesive infrastructure. Unfortunately, using other services will not allow you to get into the weeds to do everything Amazon CloudWatch can …
I feel that CloudWatch will always remain the backbone of log analytics, events, and alarms. However, we can use other products in conjunction with it for better log analytics and monitoring. In my organization, we also ingest logs from CloudWatch to Splunk and ELK. This way we …
ThousandEyes include a wide range of monitoring features focusing on network and DEM. Alerts on outage on time. While we face some issues in the Datadog agent, we do not face any issues with integrating the agent with other platforms, and this feature surely makes it worth it. …
ThousandEyes compared to Datadog provides so much information. Sometimes a little bit too much information but against its competitors ThousandEyes is very easy to setup for teams that are small or lack the skillset in doing so. This is a product that comes ready to use out of …
No one is better than the other. I can get different data and sometimes similar data, it's important to compare values and verify the data between the tools. Additionally, there are other functionalities that ThousandEyes has that the others don't, but it is also the other way …
ThousandEyes provides end to end path visibility from end users all the way to the applications from remote locations through the WAN to the Cloud. No other platforms provides such visibility to identify issues that impact end user experience.
In all cases, each separate solution did OK on their own, but ThousandEyes went deeper and usually wider. They also provide world-class support 24/7. I have never been left stranded or uninformed. They took the time to learn our business, provide excellent thought on how to …
First think first - it's easy to use, and very easy to implement in any infrastructure. It provides a custom dashboard and monitors. I’ve used or evaluated Grafana, Prometheus, Amazon CloudWatch, and Dynatrace, and each tool has strong capabilities. Prometheus + Grafana provide …
Datadog is significantly more user-friendly than CloudWatch.In terms of capabilities, they're similar. I would not call either of the best-in-class for any single feature, but Datadog feels more polished and ready to use overall.Multi-cloud monitoring is a clear differentiator …
Datadog seems to be the most feature-rich of all the alternatives we've considered, however due to problems outlined earlier, some of the others have benefits. OpenTel can give us a way to make our platforms compatible with a variety of vendors, and can be done without …
Datadog is a more complex but complete solution than any of the other Log Aggregation, monitoring, or general observabilty tools that we have trialed. I found it easier to setup following useful and up-to-date documentation provided directly by Datadog instead of scattered …
UI of the Datadog is easy to understand and integration steps are easy to understand. It also provides the troubleshooting steps which are easy to understand. Supports multi cloud integrations which is very important for all the customers to know about the cloud service's …
Verified User
Engineer
Chose Datadog
I selected Datadog because of its features and the wide range of integration support. As I already told it supports more that 600+ integrations which helps and organization to keep everything in a single place and also its AI feature which is reducing the time for root cause …
For out business we find that AWS Cloudwatch is good at providing real-time metrics for monitoring and analysing the performance and usage of our platform by customers. It is possible to create custom metrics from log events, such people adding items to a basket, checking out or abandoning their orders.
Unified communications real-time analysis is one of the biggest points of the solution. You can see your traffic path and find issues before, during and after the calls. This is very useful for analyzing VoIP and video conferencing problems like in WebEx, Microsoft Teams and Zoom. It helps to see network issues like packet loss, jitter, or latency that can make call quality bad. Another good use case is checking cloud apps and SaaS services. Many companies use external platforms like Microsoft Azure, 365, Salesforce, or AWS. It lets Networking teams see the network path from users to these services so they can find if problems come from the company network, the internet provider, or the cloud service. Also, it is good for companies using mix of on-prem and cloud. It shows how traffic moves between different parts of the network, so IT teams can see where a problem happens and fix it faster. There are different types of agents that we can use in Cisco ThousandEyes. Enterprise agents can be use for a relative big amount of synthetic test. Endpoint agents are install in user PC or MAC laptops to check network quality from the client side. WebEx devices also have built-in agents that help to see performance problems in meetings, making it easy to find what is causing a bad call. Maybe it's not the best solution if what you want to measure is not HTTPs based or hasn't an API. Also if your scenario is Zoom Rooms, you won't have the same level of integration that it has for WebEx and Microsoft solutions.
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
It provides lot many out of the box dashboard to observe the health and usage of your cloud deployments. Few examples are CPU usage, Disk read/write, Network in/out etc.
It is possible to stream CloudWatch log data to Amazon Elasticsearch to process them almost real time.
If you have setup your code pipeline and wants to see the status, CloudWatch really helps. It can trigger lambda function when certain cloudWatch event happens and lambda can store the data to S3 or Athena which Quicksight can represent.
Cisco ThousandEyes does the holistic discovery of the end components, the network components, and it's really fast at identifying where the issue is, which is not normally identified by the classic monitoring tools. So it's quite a fast identifying the issue of the networks and Cisco ThousandEyes also provides a very good real user end user monitoring experience for the end customers. So those are the two real life and also very good examples for Cisco ThousandEyes.
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
Memory metrics on EC2 are not available on CloudWatch. Depending on workloads if we need visibility on memory metrics we use Solarwinds Orion with the agent installed. For scalable workloads, this involves customization of images being used.
Visualization out of the box. But this can easily be addressed with other solutions such as Grafana.
By design, this is only used for AWS workloads so depending on your environment cannot be used as an all in one solution for your monitoring.
The elephant in the room is going to be cost. ThousandEyes is a great tool, but you will pay for it. There are other services that do a good job at providing a smaller subset of features compared to ThousandEyes. If all you need is that particular subset of features, ThousandEyes may not make fiscal sense for your organization.
As a subset of the cost issue, within the last 18 months or so the pricing on enterprise (local) agents has been modified in a way that seems not to benefit the customer. Previously enterprise agents had a flat monthly cost associated with them with unlimited test usage (the only limit on test usage was based on concurrent tests running at any given point in time). This meant that instead of using a cloud agent and paying per-test, you had the option of spinning up an cheap Digital Ocean droplet and creating your own cloud agent for external testing without using Cloud Agents. When the change was made they eliminated the flat per-agent cost and instead treated the pricing the same as that of the cloud agents but cutting the number of "cloud units" per test in half for tests run from enterprise agents. For organizations with under-utilized enterprise agents, this may be helpful financially, but for organizations that push their local agents to the limit, the cost skyrocketed.
BGP monitor peering sessions have been less than reliable. The data doesn't seem to be an issue, but the sessions seem to bounce or fail altogether on a fairly consistent basis. The routers or servers with which your routers peer sit behind some firewalls that have caused issues in the past.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
The software does it's job extremely well and the system makes it very user friendly to get into. When looking for software I prefer to not need a PHD to operate it. Having a great UI and simple setup makes it easy to include more members of our team to get more value out of the platform.
It's excellent at collecting logs. It's easy to set up. The viewing & querying part could be much better, though. The query syntax takes some time to get used to, & the examples are not helpful. Also, while being great, Log Insights requires manual picking of log streams to query across every time.
There is definitely a learning curve to ThousandEyes, but once you understand how the client deployment works and how to set up monitoring, things go pretty smoothly. I think the initial setting up of clients on endpoints can be a little tricky though.
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
Support is effective, and we were able to get any problems that we couldn't get solved through community discussion forums solved for us by the AWS support team. For example, we were assisted in one instance where we were not sure about the best metrics to use in order to optimize an auto-scaling group on EC2. The support team was able to look at our metrics and give a useful recommendation on which metrics to use.
You have online support from the tool itself 24/7 and they are very responsive. We also have a specific account manager and specific engineer assigned to help us with very specific questions for our environment. The level of response to our requirements is always super high. We have requested specific features to be added and these have been developed and introduced very quick tot he product (within weeks). Their DevOps and agile approach seems to pay off.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
Our Cisco reps actually had someone teach us a few things about the functionality of ThousandEyes, and it helped a lot. The training was good and we had follow-up assistance as well when we had questions about the monitoring and reporting functions. Overall, we were satisfied with the training and support.
Our implementation was pretty straightforward, with some issues loading clients on endpoints. We didn't have any notable issues, and I don't really have any additional insights.
Grafana is definitely a lot better and flexible in comparison with Amazon CloudWatch for visualisation, as it offers much more options and is versatile. VictoriaMetrics and Prometheus are time-series databases which can do almost everything cloudwatch can do in a better and cheaper way. Integrating Grafana with them will make it more capable Elasticsearch for log retention and querying will surpass cloudwatch log monitoring in both performance and speed
No one is better than the other. I can get different data and sometimes similar data, it's important to compare values and verify the data between the tools. Additionally, there are other functionalities that ThousandEyes has that the others don't, but it is also the other way around. I will always recommend to have available not 1 or 2, all possible available for your job.
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
I think this product would be infinitely scalable since it's all cloud hosted and can support thousands of endpoints if needed. We are only using it for a limited number of endpoints, so we never really considered scalability.
Building the trust from our Merchants is core when you come to renewal time. Trust builds partnerships, builds stickiness and allows for easier upsells or contract renewals.
Having a champion in IT that touts your service is important to the business, it removes a large portion of friction in the business to get services implemented and working to its peak.
Flexibility in pricing can be better. How they measure the number of agents being used can get thorny. When you build and tear down virtual servers a lot it can appear there are more agents running than there are. Once we understood how they measure we were able to better utilize the product efficiently.