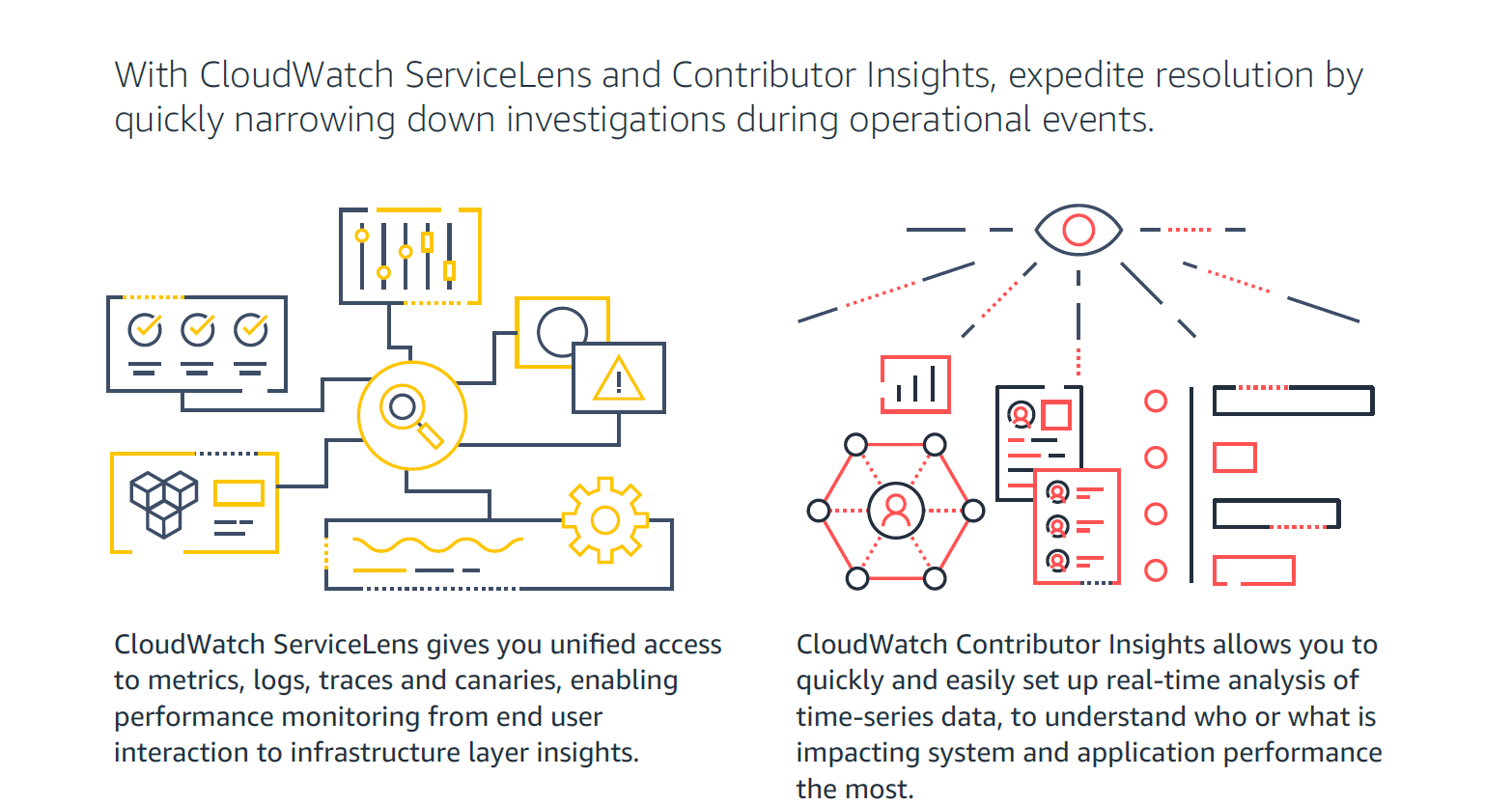
Amazon CloudWatch is a native AWS monitoring tool for AWS programs. It provides data collection and resource monitoring capabilities.
$0
per canary run
Datadog
Score 8.6 out of 10
N/A
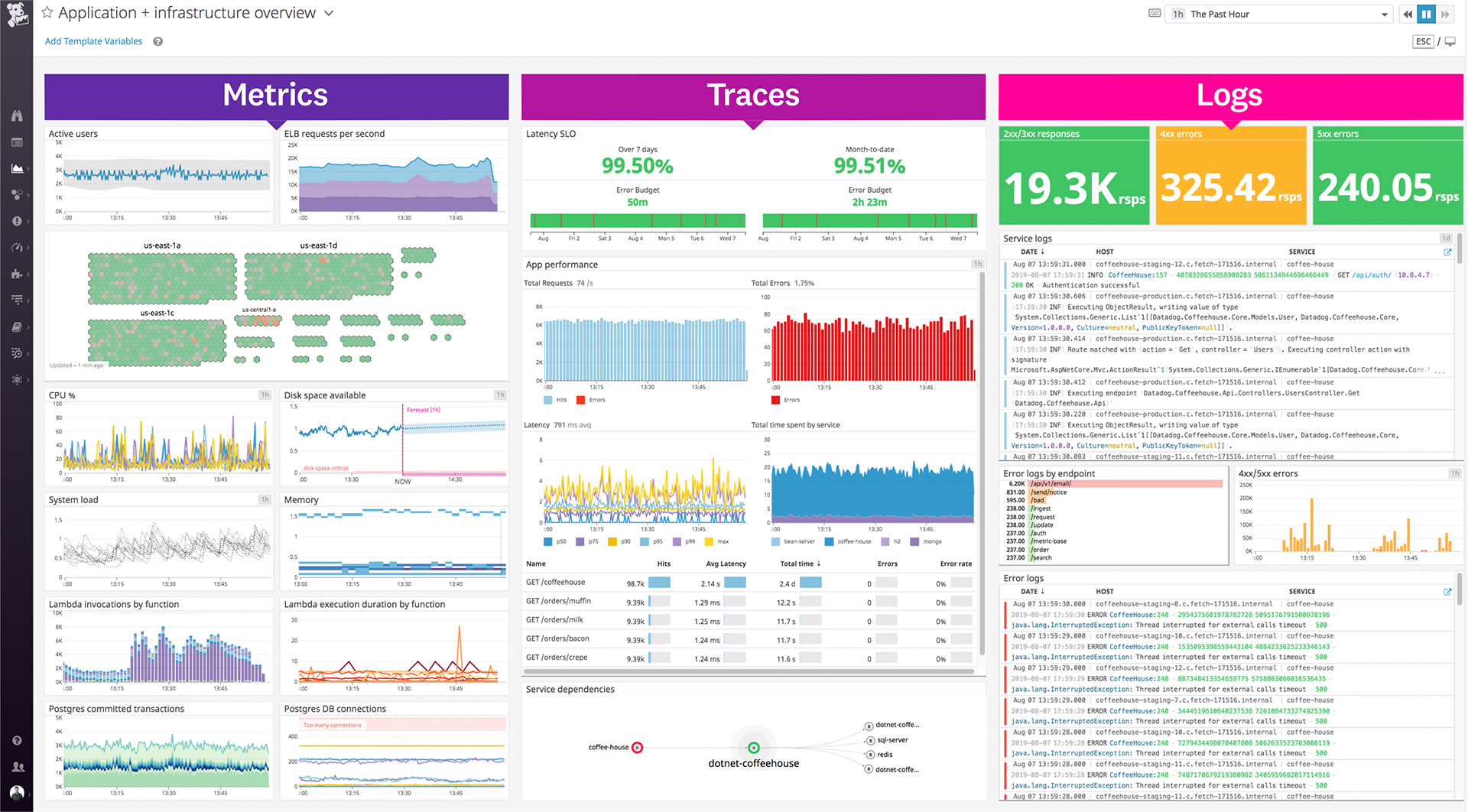
Datadog is a monitoring service for IT, Dev and Ops teams who write and run applications at scale, and want to turn the massive amounts of data produced by their apps, tools and services into actionable insight.
$18
per month per host
Nutanix Cloud Infrastructure
Score 8.9 out of 10
N/A
Nutanix in San Jose, California offers their software-defined Enterprise Cloud as a hyper-converged infrastructure solution. The Nutanix Cloud Infrastructure solution combines the Nutanix Acropolis virtualization solution, Nutanix AHV hypervisor (though Acropolis works with other hypervisors), Prism cluster manager, Nutanix Calm and Nutanix Flow server management, and is available on the Nutanix NX series of server hardware appliances, as well as third-party OEM appliances.
N/A
Pricing
Amazon CloudWatch
Datadog
Nutanix Cloud Infrastructure
Editions & Modules
Canaries
$0.0012
per canary run
Logs - Analyze (Logs Insights queries)
$0.005
per GB of data scanned
Over 1,000,000 Metrics
$0.02
per month
Contributor Insights - Matched Log Events
$0.02
per month per one million log events that match the rule
Logs - Store (Archival)
$0.03
per GB
Next 750,000 Metrics
$0.05
per month
Next 240,000 Metrics
$0.10
per month
Alarm - Standard Resolution (60 Sec)
$0.10
per month per alarm metric
First 10,000 Metrics
$0.30
per month
Alarm - High Resolution (10 Sec)
$0.30
per month per alarm metric
Alarm - Composite
$0.50
per month per alarm
Logs - Collect (Data Ingestion)
$0.50
per GB
Contributor Insights
$0.50
per month per rule
Events - Custom
$1.00
per million events
Events - Cross-account
$1.00
per million events
CloudWatch RUM
$1
per 100k events
Dashboard
$3.00
per month per dashboard
CloudWatch Evidently - Events
$5
per 1 million events
CloudWatch Evidently - Analysis Units
$7.50
per 1 million analysis units
Log Management
$1.27
per month (billed annually) per host
Infrastructure
$15.00
per month (billed annually) per host
Standard
$18
per month per host
Enterprise
$27
per month per host
DevSecOps Pro
$27
per month per host
APM
$31.00
per month (billed annually) per host
DevSecOps Enterprise
$41
per month per host
No answers on this topic
Offerings
Pricing Offerings
Amazon CloudWatch
Datadog
Nutanix Cloud Infrastructure
Free Trial
Yes
Yes
No
Free/Freemium Version
Yes
Yes
No
Premium Consulting/Integration Services
Yes
No
No
Entry-level Setup Fee
No setup fee
Optional
No setup fee
Additional Details
With Amazon CloudWatch, there is no up-front commitment or minimum fee; you simply pay for what you use. You will be charged at the end of the month for your usage.
Discount available for annual pricing. Multi-Year/Volume discounts available (500+ hosts/mo).
CloudWatch's log search features are impoverished compared to PaperTrail's or Loggly's. However, CloudWatch aggregates logs from Lambda, ECS, API Gateway and more out-of-the-box. You do not need to manage anything. You do not need to worry about an errant logging configuration …
As CloudWatch is integrated into AWS already, its ready to go. External products such as Nagios require a fair bit of work to actually get the metrics into the dashboards. Products like SolarWinds and Datadog provide quite a high level of very easy integration which allows for …
Amazon CloudWatch is fully integrated into your existing AWS account, and provides easy hooks into several different services to make a cohesive infrastructure. Unfortunately, using other services will not allow you to get into the weeds to do everything Amazon CloudWatch can …
I feel that CloudWatch will always remain the backbone of log analytics, events, and alarms. However, we can use other products in conjunction with it for better log analytics and monitoring. In my organization, we also ingest logs from CloudWatch to Splunk and ELK. This way we …
First think first - it's easy to use, and very easy to implement in any infrastructure. It provides a custom dashboard and monitors. I’ve used or evaluated Grafana, Prometheus, Amazon CloudWatch, and Dynatrace, and each tool has strong capabilities. Prometheus + Grafana provide …
Datadog is significantly more user-friendly than CloudWatch.In terms of capabilities, they're similar. I would not call either of the best-in-class for any single feature, but Datadog feels more polished and ready to use overall.Multi-cloud monitoring is a clear differentiator …
Datadog seems to be the most feature-rich of all the alternatives we've considered, however due to problems outlined earlier, some of the others have benefits. OpenTel can give us a way to make our platforms compatible with a variety of vendors, and can be done without …
Datadog is a more complex but complete solution than any of the other Log Aggregation, monitoring, or general observabilty tools that we have trialed. I found it easier to setup following useful and up-to-date documentation provided directly by Datadog instead of scattered …
UI of the Datadog is easy to understand and integration steps are easy to understand. It also provides the troubleshooting steps which are easy to understand. Supports multi cloud integrations which is very important for all the customers to know about the cloud service's …
Verified User
Engineer
Chose Datadog
I selected Datadog because of its features and the wide range of integration support. As I already told it supports more that 600+ integrations which helps and organization to keep everything in a single place and also its AI feature which is reducing the time for root cause …
For out business we find that AWS Cloudwatch is good at providing real-time metrics for monitoring and analysing the performance and usage of our platform by customers. It is possible to create custom metrics from log events, such people adding items to a basket, checking out or abandoning their orders.
Datadog may be better suited for teams that have a more out-of-the-box infrastructure, on the primary platforms Datadog supports. You may also have better results if you have a bigger team dedicated to devops and/or a bigger budget. We found that trying to adapt it to our use case (small team, .NET on AWS Fargate) wasn't feasible. We continually ran into roadblocks that required us to dig through documentation (and at times, having to figure out some documentation was wrong), go back and forth with support, and in my opinion, waste money on excessive and unintended usages due to opaque pricing models and inaccurate usage reports, as well as broken/non-functional rate sampling controls.
For an organization that requires top-notch performance HCI, Nutanix is the best. You may start with 3 nodes and expand the cluster as required. The management through Nutanix Prism Central and Element was so easy that even a Junior Engineer was able to handle it. The Nutanix platform is not suitable for organizations with a small budget and fewer requirements for high-performance infrastructure, as the Nutanix solution itself is suited for enterprises.
It provides lot many out of the box dashboard to observe the health and usage of your cloud deployments. Few examples are CPU usage, Disk read/write, Network in/out etc.
It is possible to stream CloudWatch log data to Amazon Elasticsearch to process them almost real time.
If you have setup your code pipeline and wants to see the status, CloudWatch really helps. It can trigger lambda function when certain cloudWatch event happens and lambda can store the data to S3 or Athena which Quicksight can represent.
The thing which Datadog does really well, one of them are its broad range of services integrations and features which makes it one step observability solution for all. We can monitor all types of our application, infrastructure, hosts, databases etc with Datadog.
Its custom dashboard feature which helps us to visualize the data in a better way . It supports different types of charts through those charts we can create our dashboard more attractive.
Its AI powered alerting capability though that we can easily identify the root cause and also it has a low noise alerting capability which means it correlated the similar type of issues.
One-click upgrades; whether it's hypervisor, firmware, disk or other updates. This feature has drastically decreased complexity and administration time.
Data Locality. Not all hyperconverged technology is created equal. When I first purchased Nutanix they were the only vendor (and as far as I know, still are) that made sure the storage a VM used was on the same host that VM was running on. Given a normal operating state, the [storage] network is literally only used for replication data.
They got rid of traditional RAID. Nutanix uses software to determine where a VM's storage should be written and replicated to. This dramatically decreases I/O when changing the number of nodes in a cluster, be it on purpose or during a failure scenario. Ex. adding a new node: If one uses RAID arrays then enough space has to be set aside to create a new array that includes the new node, then all the information has to be copied over, and the old array destroyed. RAID arrays do not grow and shrink gracefully so Nutanix has designed a better solution.
The Nutanix management interface was built on HTML5. No more flash headaches!
Memory metrics on EC2 are not available on CloudWatch. Depending on workloads if we need visibility on memory metrics we use Solarwinds Orion with the agent installed. For scalable workloads, this involves customization of images being used.
Visualization out of the box. But this can easily be addressed with other solutions such as Grafana.
By design, this is only used for AWS workloads so depending on your environment cannot be used as an all in one solution for your monitoring.
Alert windows cause lag in notifications (e.g. if the alert window is X errors in 1 hour, we won't get alerted until the end of the 1 hour range)
I would appreciate more supportive examples for how to filter and view metrics in the explorer
I would like a more clear interface for metrics that are missing in a time frame, rather than only showing tags/etc. for metrics that were collected within the currently viewed time frame
The one downside I have working with Nutanix is the sales team. They seem to try to add in extra goodies to sales quotes or push for extras that you don't really need and you have to tell them to take them out. Don't be afraid to push back on them.
Need to analyze sizing with sales team to ensure right sizing.
AOS definitely make our dev/test virtual environment management much easier than before. And the consolidation the test/dev environment from Azure and Cisco UCS, we have less need to transfer large amount of data between different hardware platforms which was very big challenge. To expand the capacity is very easy to archive as well.
It's excellent at collecting logs. It's easy to set up. The viewing & querying part could be much better, though. The query syntax takes some time to get used to, & the examples are not helpful. Also, while being great, Log Insights requires manual picking of log streams to query across every time.
There are so many features that it can be hard to figure out where you need to go for your own use case. For example, RUM monitoring us buried in a "Digital Experience" sidebar setting when this is one of our key use cases that I sometimes struggle to find in the application. It appears that ECS + Fargate monitoring was recently released which is great because we had to build a lambda reporting solution for ephemeral task monitoring. But this new feature was never on my radar until I starting clicking around the application.
It's not out of the box easy, but once you get the fundamentals the steep learning curve flattens out and the processes to get things done and how it works becomes very apparent. It's wrapping the slight change in workflow from prior VM management methods took time to unbox and apply the Nutanix Cloud Infrastructure way
The performance is nothing short of amazing. This is an HCI solution, and as any all-flash HCI solution is amazingly fast, Nutanix AOS fills local IO requests until its local IO is saturated before reaching out over the network. This lowers latency substantially compared to vSAN.
Support is effective, and we were able to get any problems that we couldn't get solved through community discussion forums solved for us by the AWS support team. For example, we were assisted in one instance where we were not sure about the best metrics to use in order to optimize an auto-scaling group on EC2. The support team was able to look at our metrics and give a useful recommendation on which metrics to use.
The support team usually gets it right. We did have a rather complicate issue setting up monitoring on a domain controller. However, they are usually responsive and helpful over chat. The downside would be I don’t think they have any phone support. If that is important to you this might not be a good fit.
Our implementation team were great and worked with us and got the program up and running very easily. Every time we called post implementation we immediately talked to an Engineer, which is so unusual in dealing with companies. Everything they have promised they have full filled. I think their support is top notch.
IPv6 is needed for link local discovery. We do not have IPv6 configured on our network so the easiest way to get our nodes configured and discovered by foundation was to configure the IPv4 addressing within the node prior to trying to discover with foundation.
Grafana is definitely a lot better and flexible in comparison with Amazon CloudWatch for visualisation, as it offers much more options and is versatile. VictoriaMetrics and Prometheus are time-series databases which can do almost everything cloudwatch can do in a better and cheaper way. Integrating Grafana with them will make it more capable Elasticsearch for log retention and querying will surpass cloudwatch log monitoring in both performance and speed
Our logs are very important, and Datadog manages them exceptionally well. We frequently use Datadog services for our investigations. Use case: Monitor your apps, infrastructure, APIs, and user experience.
Key features:
Logs, metrics, and APM (Application Performance Monitoring)
Real-time alerting and dashboards
Supports Kubernetes, AWS, GCP, and other integrations
RUM (Real User Monitoring) and Synthetics
✅ Best for backend, server, and distributed systems monitoring.
Nutanix integrates very well with Rubrik for backup and protection of the environment. Nutanix gave us simplicity and scalability compared to VMware and allowed us to extend our infrastructure into the cloud using EC2. One unified management pane for all our workloads, unlike VMWare.
We find that return on investment is probably a better metric in most cases.
ROI analysis is more than an exercise. Companies must outline what their future looks like, even if it’s vastly different from what they’re used to and comfortable with.
As good as your financial analysis might be, displacing status quo infrastructure has a lot of emotions tied to it.