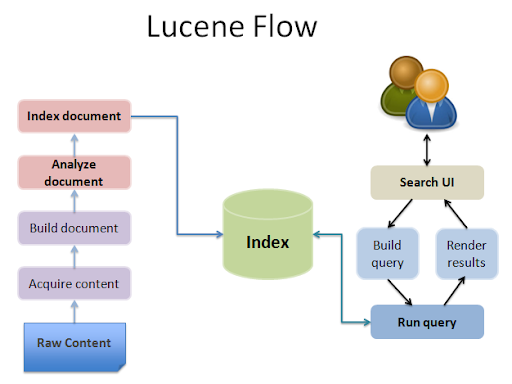
Apache Lucene is an open source and free text search engine library written in Java. It is a technology suitable for applications that requires full-text search, and is available cross-platform.
$0
per month
Azure AI Search
Score 8.8 out of 10
N/A
Azure AI Search (formerly Azure Cognitive Search) is enterprise search as a service, from Microsoft.
As I've mentioned, the biggest competitor to Azure Search is actually Azure SQL Database. It doesn't have as many features, but it's more economical and most .Net applications will have one already. As long as you can arrive at a schema and ranking strategy, it's a "good …
Apache Lucene is a perfect text search implementation where the heap space usage needs to be kept to its minimal. It also enables search based on various search fields and most importantly the search and index process can happen simultaneously. The only scenario where it might be less appropriate would be when the index size grows too big. We have witnessed few scalable issues where the search would take a while when the index size is too large.
It's very useful when used with large file systems, once the models index the files good enough, the suggestions are very impressive and produce grounded answers. Since it can natively work with blob storage the requirement for pre-processing the data is eliminated i.e. the data can be searched in its raw form, this makes Azure AI Search a very powerful tool when used with Azure Stack.
We found Apache Lucene to be extremely performant in querying large amounts of data and retrieving the correct files based on the metadata provided.
The online community offers great support for the product. Even though it is an open source tool, it is not difficult to find help online for it.
When we were creating a proof of concept application, we found that the software worked just as well, while being run locally on a resource-limited PC.
Like virtually all Azure services, it has first-class treatment for .Net as the developer platform of choice, but largely ignores other options. While there is a first-party Python SDK, there are only community packages for other languages like Ruby and Node. Might be a game of roulette for those to be kept up-to-date. This might make it a non-starter for some teams that don't want to do the work to integrate with the REST API directly.
In my opinion, partitions inside of Azure Search don't count as data segregation for customers in a multi-tenant app, so any application where you have many customers with high-security concerns, Azure Search is probably a non-starter.
To elaborate on the multi-tenant issue: Azure Search's approach to pricing is pretty steep. While there is a free tier for small applications (50MB of content or less) the first paid tier is about 14x more expensive than the first SQL Database tier that supports full-text search. For many applications, it makes a lot more economic sense to just run some LIKE or CONTAINS queries on columns in a table rather than going with Azure Search.
I give 10 rating because by using this endpoint and api key only we able to build that chatbot product in a timeline given by our client and also creating the endpoint and keys from the portal is also very easy for Azure AI Search and it doesn't take much time and also scalability is good.
The search and index performance of [Apache] Lucene is excellent and the quality of results is good, if not better. For implementing it with small scale applications it is a no brainer, Lucene is the best and most cost effective solution. Learning curve is not too steep either.
It is good for me, and I want to rate this product 9/10. I hope they continue to improve and also offer a free plan with more benefits to learn Azure AI Search.
Being an open source project we did not have to pay any licensing fees for using Apache Lucene. It has greatly improved our search functionality in our web apps.
When integrated with our existing file system the Azure AI Search helped users tremendously by reducing search times and improve efficacy of intended result.
Since Azure AI Search is a PaaS solution, we had very short ideation to go-live timespan, which ended up reflecting in our product performance.
A rare but not negligible occurrence was correctness of search being questionable when new data was added to the system. The search returns false positive results.