Icinga is an open source network monitoring platform. It includes automation, modularized integration packages, and prebuilt alerts and reporting capabilities.
N/A
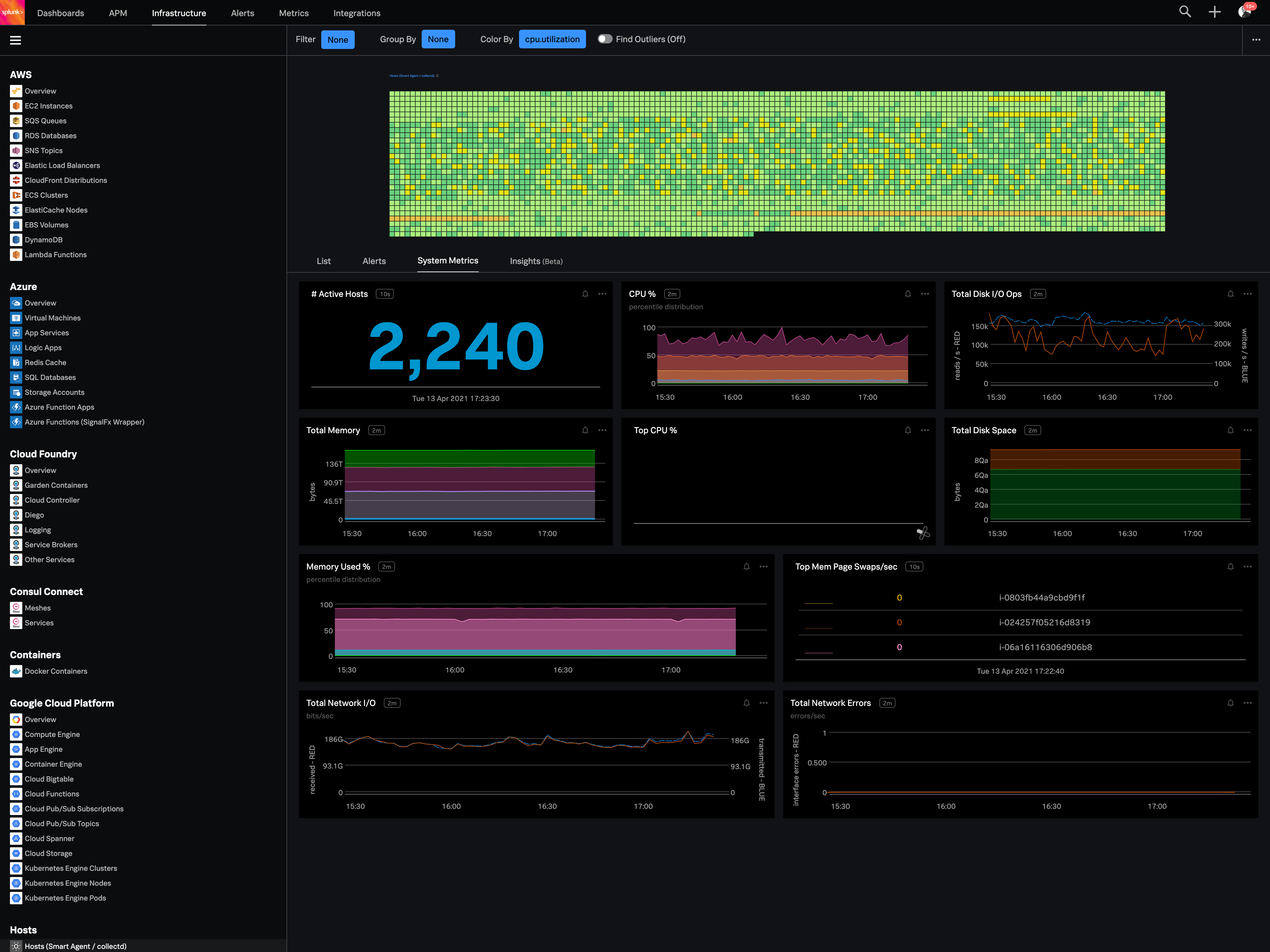
Splunk Infrastructure Monitoring
Score 8.7 out of 10
N/A
SignalFX is Real-Time Cloud Monitoring and Observability for Infrastructure, Microservices and Applications. SignalFX was acquired by Splunk in August 2019. SignalFX Infrastructure Monitoring provides real-time cloud monitoring and observability platform for infrastructure, microservices and DevOps. A new SignalFX product, SignalFx Microservices APM, was released March 2020 to detect issues, provide real-time app troubleshooting, and future-proof expectations.
Icinga is a world-class monitoring system. It can be used for most general monitoring situations. It is not a silver bullet, however, and there are instances where domain-specific monitoring systems are necessary. However, the output from those monitoring systems can be funneled into Icinga as a central monitoring and alerting system.
Splunk Infrastructure Monitoring is well suited for any complicated environment where you have apps and servers across multiple clouds and platforms and products. If you have a data centre where all your apps and servers are in one single network, you could probably get away with older solutions. But for any modern, complex, hybrid-cloud microservices environment, Splunk Infrastructure Monitoring is a must-have.
SignalFX handles historical metric aggregation exceptionally well, providing a multifaceted approach to event detection based on anomalies.
SignalFX's cost is incredibly flexible with their pricing model of DPM (data-point per minute) vs the traditional "per host" model that most monitoring SaaS use.
SignalFX support is responsive and knowledgeable, very eager to help solve your immediate problems.
SignalFX integrations is vast and constantly growing, making adoption easy even when multiple different open-source technologies are used in your stack.
Icinga is a solid solution which does everything it promises. It is backwards compatible with most Nagios instances, making the transition very easy. Once you get the hang of installing new plugins and editing configuration files expanding its monitoring capabilities are easy.
Good: Stable system with low error rate Easy to use for simple use cases Bad: UI is not very clear for complex usage Mobile view (when logged in from phone) is bad No library for .net
I find that learning the interface can take some time. We need a better show-and-tell on how the Teams pages, Dashboard Groups, Dashboards and charts delay. Advance SignalFlow is sometimes hard to build. Some better samples of advanced SignalFlow would be helpful. For example, Splunk SPL has a vast resource of examples.
Icinga is better than Nagios because of its nicer user interface. New Relic can monitor CPU/memory and disk usage, but it's more of a performance and application troubleshooting tool rather than monitoring
They’re not for the same purpose but we’re using NewRelic and Honeycomb for monitoring purposes. NewRelic is used for HTTP client monitoring for system related throughput, error, database and external client monitoring. Honeycomb is used to monitor actual HTTP request/response values. Splunk [Infrastructure Monitoring] is used for real-time application related throughout and error monitoring.
Caused us to get a lot of spam when we redeployed apps and old instances stopped sending metrics. Muting alerts solves this, but people often forget to do it or do it incorrectly.
Helped us find historical info about instances/apps.