I find Qubole is well suited for getting started analyzing data in the cloud without being locked in to a specific cloud vendor's tooling other than the underlying filesystem. Since the data itself is not isolated to any Qubole cluster, it can be easily be collected back into a cloud-vendor's specific tools for further analysis, therefore I find it complementary to any offerings such as Amazon EMR or Google DataProc.
Redis has been a great investment for our organization as we needed a solution for high speed data caching. The ramp up and integration was quite easy. Redis handles automatic failover internally, so no crashes provides high availability. On the fly scaling scale to more/less cores and memory as and when needed.
Easy for developers to understand. Unlike Riak, which I've used in the past, it's fast without having to worry about eventual consistency.
Reliable. With a proper multi-node configuration, it can handle failover instantly.
Configurable. We primarily still use Memcache for caching but one of the teams uses Redis for both long-term storage and temporary expiry keys without taking on another external dependency.
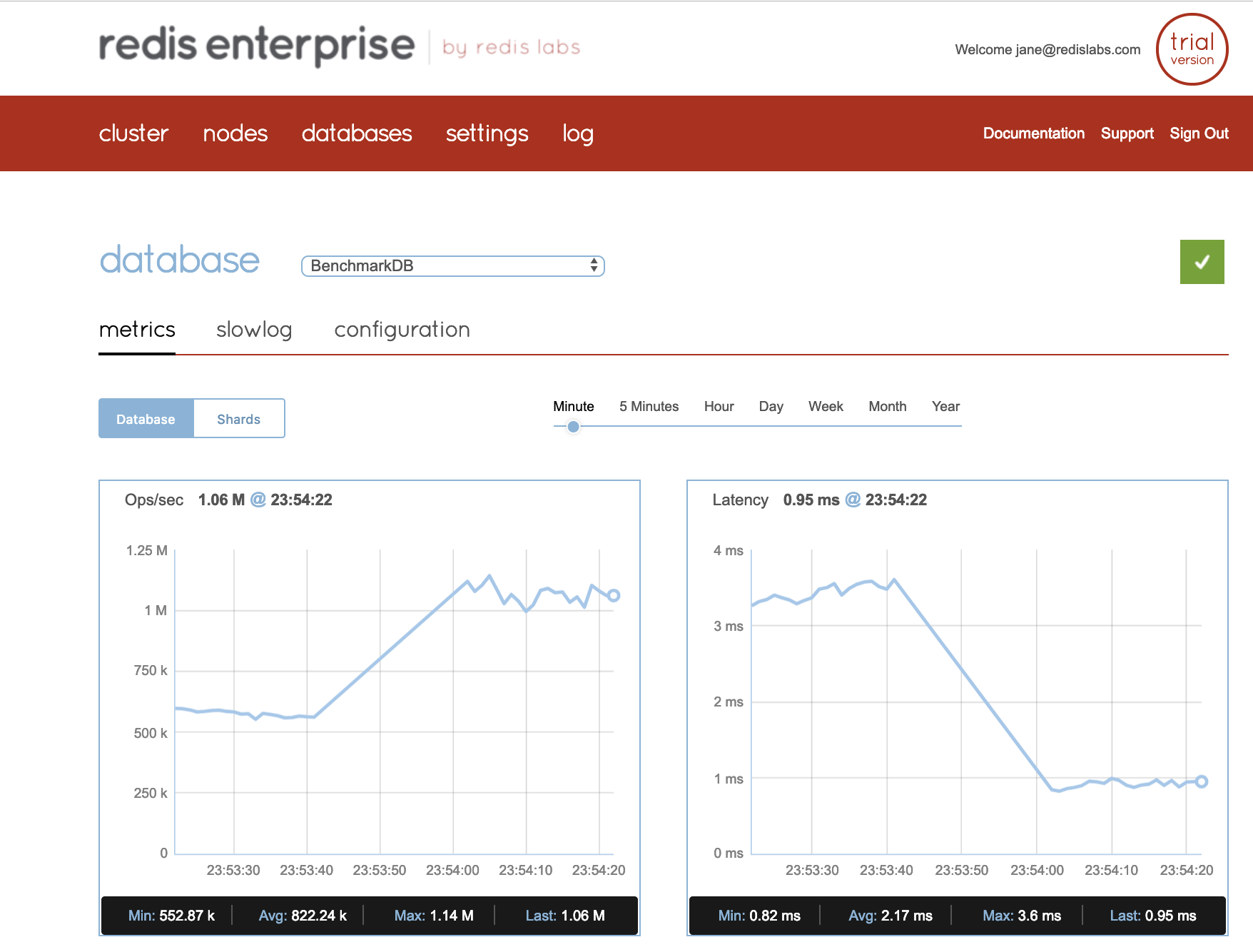
Fast. We process tens of thousands of RPS and it doesn't skip a beat.
Providing an open selection of all cloud provider instance types with no explanation as to their ideal use cases causes too much confusion for new users setting up a new cluster. For example, not everyone knows that Amazon's R or X-series models are memory optimized, while the C and M-series are for general computation.
I would like to see more ETL tools provided other than DistCP that allow one to move data between Hadoop Filesystems.
From the cluster administration side, onboarding of new users for large companies seems troublesome, especially when trying to create individual cluster per team within the company. Having the ability to debug and share code/queries between users of other teams / clusters should also be possible.
We had some difficulty scaling Redis without it becoming prohibitively expensive.
Redis has very simple search capabilities, which means its not suitable for all use cases.
Redis doesn't have good native support for storing data in object form and many libraries built over it return data as a string, meaning you need build your own serialization layer over it.
Personally, I have no issues using Amazon EMR with Hue and Zeppelin, for example, for data science and exploratory analysis. The benefits to using Qubole are that it offers additional tooling that may not be available in other cloud providers without manual installation and also offers auto-terminating instances and scaling groups.
We will definitely continue using Redis because: 1. It is free and open source. 2. We already use it in so many applications, it will be hard for us to let go. 3. There isn't another competitive product that we know of that gives a better performance. 4. We never had any major issues with Redis, so no point turning our backs.
It is quite simple to set up for the purpose of managing user sessions in the backend. It can be easily integrated with other products or technologies, such as Spring in Java. If you need to actually display the data stored in Redis in your application this is a bit difficult to understand initially but is possible.
The support team has always been excellent in handling our mostly questions, rarely problems. They are responsive, find the solution and get us moving forward again. I have never had to escalate a case with them. They have always solved our problems in a very timely manner. I highly commend the support team.
Qubole was decided on by upper management rather than these competitive offerings. I find that Databricks has a better Spark offering compared to Qubole's Zeppelin notebooks.
We are big users of MySQL and PostgreSQL. We were looking at replacing our aging web page caching technology and found that we could do it in SQL, but there was a NoSQL movement happening at the time. We dabbled a bit in the NoSQL scene just to get an idea of what it was about and whether it was for us. We tried a bunch, but I can only seem to remember Mongo and Couch. Mongo had big issues early on that drove us to Redis and we couldn't quite figure out how to deploy couch.
We like to say that Qubole has allowed for "data democratization", meaning that each team is responsible for their own set of tooling and use cases rather than being limited by versions established by products such as Hortonworks HDP or Cloudera CDH
One negative impact is that users have over-provisioned clusters without realizing it, and end up paying for it. When setting up a new cluster, there are too many choices to pick from, and data scientists may not understand the instance types or hardware specs for the datasets they need to operate on.
Redis has helped us increase our throughput and server data to a growing amount of traffic while keeping our app fast. We couldn't have grown without the ability to easily cache data that Redis provides.
Redis has helped us decrease the load on our database. By being able to scale up and cache important data, we reduce the load on our database reducing costs and infra issues.
Running a Redis node on something like AWS can be costly, but it is often a requirement for scaling a company. If you need data quickly and your business is already a positive ROI, Redis is worth the investment.