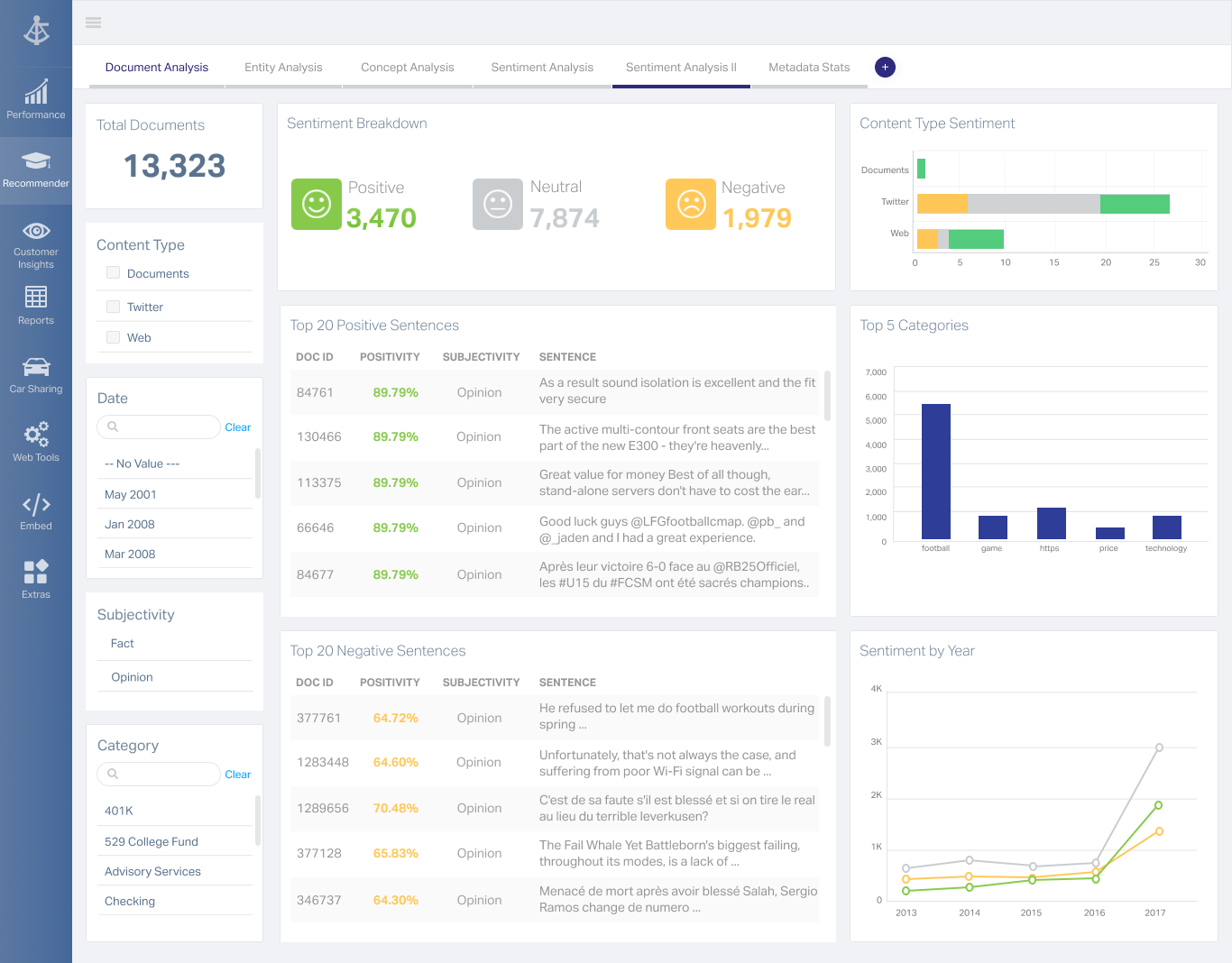
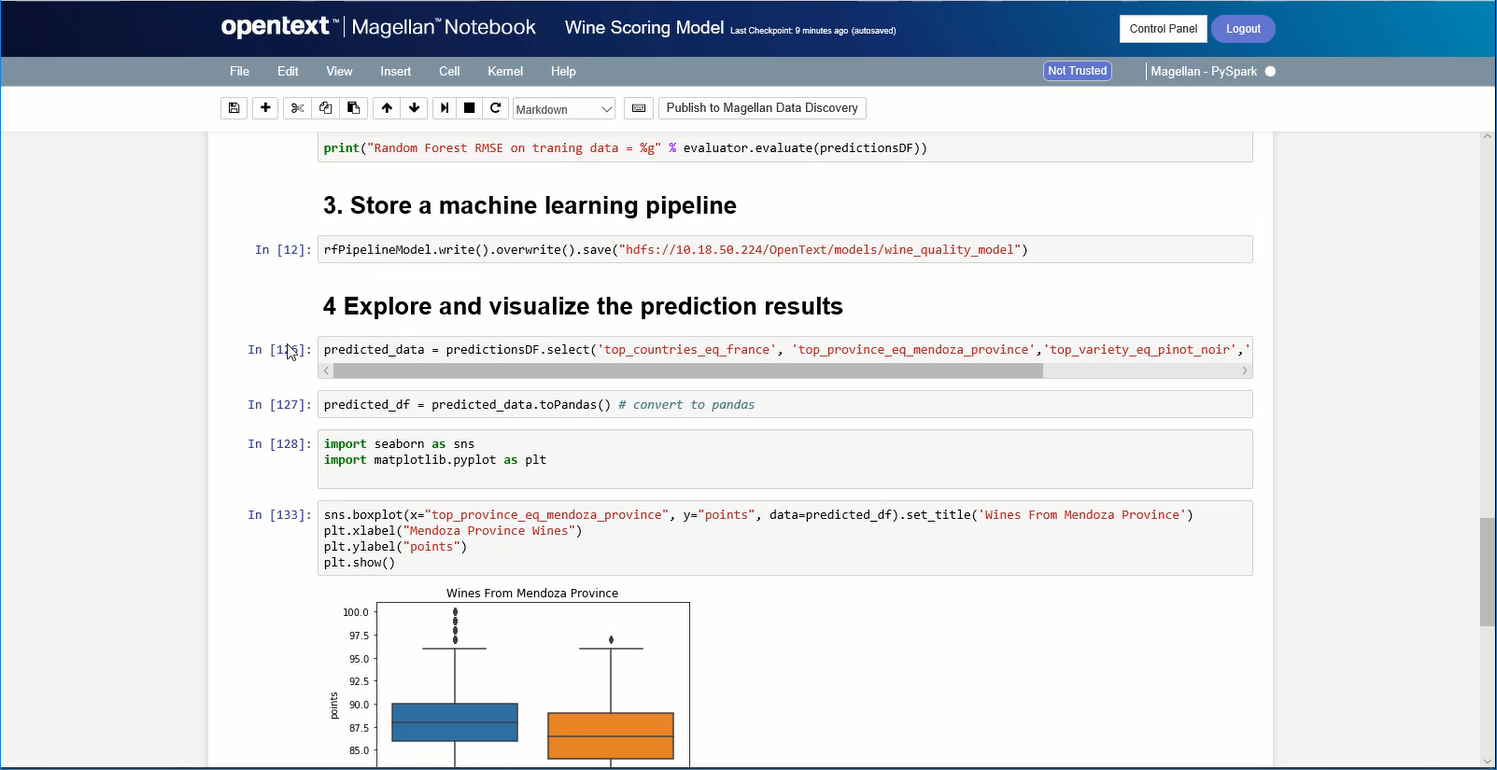
OpenText Magellan Analytics Suite leverages a comprehensive set of data analytics software to identify patterns, relationships and trends through data visualizations and interactive dashboards.
Well suited: To most of the local run of datasets and non-prod systems - scalability is not a problem at all. Including data from multiple types of data sources is an added advantage. MLlib is a decently nice built-in library that can be used for most of the ML tasks. Less appropriate: We had to work on a RecSys where the music dataset that we used was around 300+Gb in size. We faced memory-based issues. Few times we also got memory errors. Also the MLlib library does not have support for advanced analytics and deep-learning frameworks support. Understanding the internals of the working of Apache Spark for beginners is highly not possible.
If you do not have a large budget and are a large organization, I would steer clear of Actuate. If you are looking to do very complex washboarding, I would not use them. Your developers have to be very skilled to work with this. Plan to bring in consultants if necessary to help your process. Adhoc reporting is weak. If your pricing is user based and you expand, this could be very expensive.
I am no longer working for the company that was using Actuate but I believe they would continue to use it because the stitching costs would be to high. It would require a complete rewrite of the reports and the never version of Actuate (BIRT) even required an almost complete report rewrite
The only thing I dislike about spark's usability is the learning curve, there are many actions and transformations, however, its wide-range of uses for ETL processing, facility to integrate and it's multi-language support make this library a powerhouse for your data science solutions. It has especially aided us with its lightning-fast processing times.
It is quite intuitive to use. It is fit specifically for doing sentiment, emotion, and intention analysis as well as text classification and text summarization. I would have given 10 if it is fit for the purpose of doing image processing and analysis as well. There is a huge market to analyze video and image data.
1. It integrates very well with scala or python. 2. It's very easy to understand SQL interoperability. 3. Apache is way faster than the other competitive technologies. 4. The support from the Apache community is very huge for Spark. 5. Execution times are faster as compared to others. 6. There are a large number of forums available for Apache Spark. 7. The code availability for Apache Spark is simpler and easy to gain access to. 8. Many organizations use Apache Spark, so many solutions are available for existing applications.
All the above systems work quite well on big data transformations whereas Spark really shines with its bigger API support and its ability to read from and write to multiple data sources. Using Spark one can easily switch between declarative versus imperative versus functional type programming easily based on the situation. Also it doesn't need special data ingestion or indexing pre-processing like Presto. Combining it with Jupyter Notebooks (https://github.com/jupyter-incubator/sparkmagic), one can develop the Spark code in an interactive manner in Scala or Python
It is vastly superior to these in many ways, for complex reporting it is a much more sophisticated solution. Visualizations are very good. Javascript extensibility is very powerful, others don't support this or as well. Pentaho and MS are both OLAP oriented. Pentaho is moving more toward big data, which was not our primary focus. Others are stuck in the Crystal Reports Band metaphor.
Faster turn around on feature development, we have seen a noticeable improvement in our agile development since using Spark.
Easy adoption, having multiple departments use the same underlying technology even if the use cases are very different allows for more commonality amongst applications which definitely makes the operations team happy.
Performance, we have been able to make some applications run over 20x faster since switching to Spark. This has saved us time, headaches, and operating costs.
Actuate can handle 50 to 60 sub reports inside a report very well.
Dynamically creating the datasource, chart, graph, reports are the main advantages. We can do any level of drilling, and can create a performance matrix dashboard efficiently.