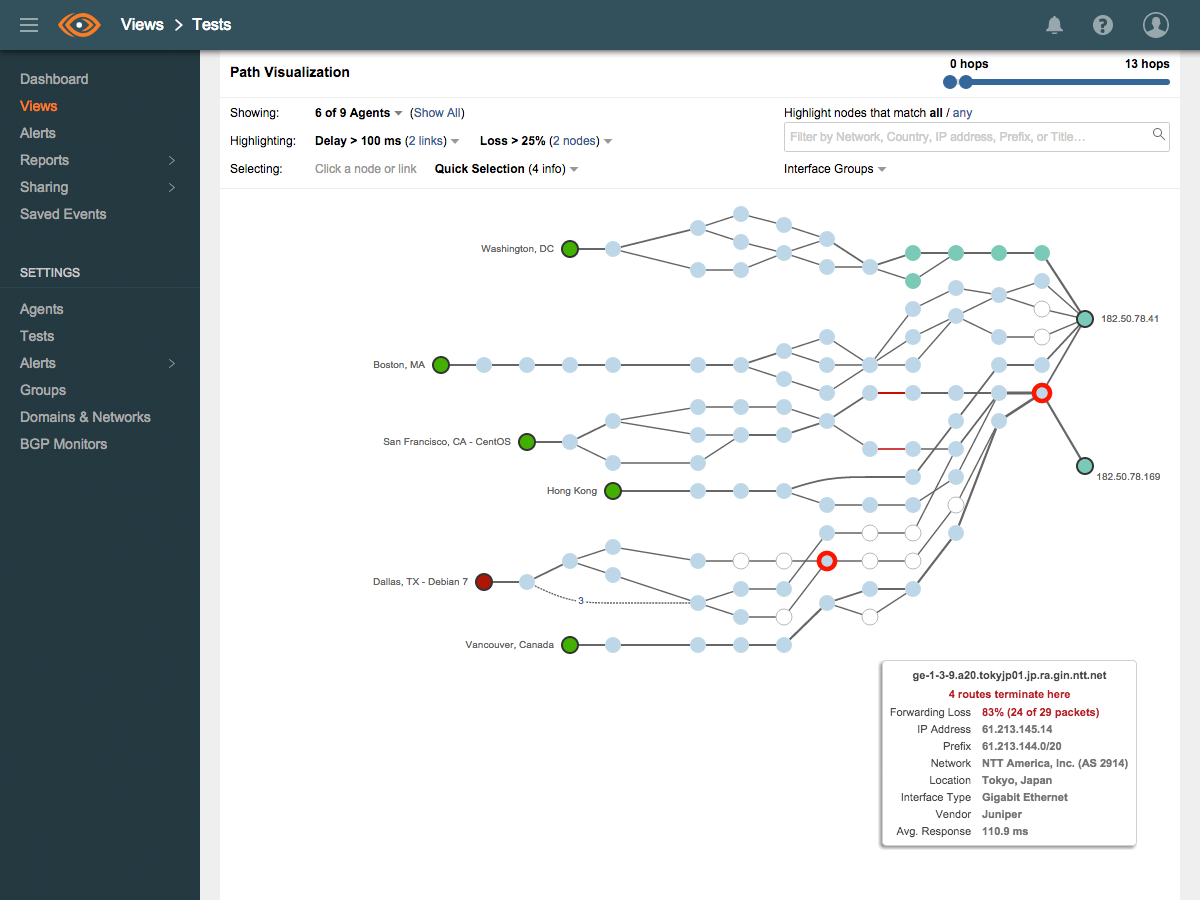
Cisco ThousandEyes offers Digital Experience Monitoring that integrates application performance monitoring within a broader network monitoring platform. It primarily focuses on connectivity monitoring and supports SaaS and hybrid systems monitoring.
N/A
Nagios Core
Score 8.0 out of 10
N/A
Nagios provides monitoring of all mission-critical infrastructure components. Multiple APIs and community-build add-ons enable integration and monitoring with in-house and third-party applications for optimized scaling.
In all cases, each separate solution did OK on their own, but ThousandEyes went deeper and usually wider. They also provide world-class support 24/7. I have never been left stranded or uninformed. They took the time to learn our business, provide excellent thought on how to …
Nagios is a great tool for the price. Lots of bang for your buck if you know what I mean. The tool installs easily and has a very lightweight footprint. This also allows for great batch installation and configuration. Tags can be applied and pushed throughout the org. …
At least for me, it is a very important tool to diagnose bandwidth / Routing issues. Any global company should have ThousandEyes, it will avoid you many headaches. You'll need to invest in servers (on-prem and remote) in all locations in which you need, you can take advantage of all the monitoring tools.
Nagios monitoring is well suited for any mission critical application that requires per/second (or minute) monitoring. This would probably include even a shuttle launch. As Nagios was built around Linux, most (85%) plugins are Linux based, therefore its more suitable for a Linux environment.
As Nagios (and dependent components) requires complex configurations & compilations, an experienced Linux engineer would be needed to install all relevant components.
Any company that has hundreds (or thousands) of servers & services to monitor would require a stable monitoring solution like Nagios. I have seen Nagios used in extremely mediocre ways, but the core power lies when its fully configured with all remaining open-source components (i.e. MySQL, Grafana, NRDP etc). Nagios in the hands of an experienced Linux engineer can transform the organizations monitoring by taking preventative measures before a disaster strikes.
Alerting on outages. ThousandEyes provides a few different options to receive alerts: you can have alerts emailed to a subset of (or all) users, there is a basic Slack integration, and if more flexibility is required (or your preferred method of being alerted isn't built-in) webhooks can be used to hit another API.
Speeding up mean time to resolution (or mean time to innocence if you're a more siloed and blame-happy organization). Failure alerts can be configured to include the cause of the failure instead of just "resource x is down." For example, the alerts can come out and say that a website was down due to an HTTP 500, which will help prevent staff from spinning their wheels trying to diagnose the network from the client to the web server.
Post mortems and root cause analyses. After an outage has been resolved, it is possible to go back for up to 30 days without losing any level of detail for the test in question, and to view information like the DNS response received, the network path taken by the traffic, and any added latency incurred by an individual link. It can also be used to view Internet routing changes surrounding the incident.
Support. Every ticket or chat I have opened has been met by a friendly and helpful staff member that has been able to provide helpful insight into what is causing a particular issue, and what steps they will take on their side to resolve an issue or provide suggestions of steps to take on our side if necessary.
Continue to innovate and support more and more services. In the world of IOT and point to point traffic being more and more prevalent creating a flexible product is fantastic. Build on the end user product, last mile and even more sharing.
Nagios could use core improvements in HA, though, Nagios itself recommends monitoring itself with just another Nagios installation, which has worked fine for us. Given its stability, and this work-around, a minor need.
Nagios could also use improvements, feature wise, to the web gui. There is a lot in Nagios XI which I felt were almost excluded intentionally from the core project. Given the core functionality, a minor need. We have moved admin facing alerts to appear as though they originate from a different service to make interacting with alerts more practical.
We will definitely renew and maybe even extend our usage of ThousandEyes. We have been using ThousandEyes now for a couple of years and it has shown us major benefits. With the new options it offers for SD-WAN for us it is a no brainer to renew our current licenses
We're currently looking to combine a bunch of our network montioring solutions into a single platform. Running multiple unique solutions for monitoring, data collection, compliance reporting etc has become a lot to manage.
The Nagios UI is in need of a complete overhaul. Nice graphics and trendy fonts are easy on the eyes, but the menu system is dated, the lack of built in graphing support is confusing, and the learning curve for a new user is too steep.
You have online support from the tool itself 24/7 and they are very responsive. We also have a specific account manager and specific engineer assigned to help us with very specific questions for our environment. The level of response to our requirements is always super high. We have requested specific features to be added and these have been developed and introduced very quick tot he product (within weeks). Their DevOps and agile approach seems to pay off.
I haven't had to use support very often, but when I have, it has been effective in helping to accomplish our goals. Since Nagios has been very popular for a long time, there is also a very large user base from which to learn from and help you get your questions answered.
Simple Network Management Protocol cannot achieve what an agent-based monitoring solution can. Access layer testing gives you visibility into the user's endpoint. ThousandEyes is able to provide both telemetry and user experience in a bundled solution. The way that Cisco has built in the enterprise agents to their 9300 and 9500 switches has made exposure to the platform widespread.
Because we get all we required in Nagios [Core] and for npm, we have to do lots of configuration as it is not as easy as Comair to Nagios [Core]. On npm UI, there is lots of data, so we are not able to track exact data for analysis, which is why we use Nagios [Core].
With it being a free tool, there is no cost associated with it, so it's very valuable to an organization to get something that is so great and widely used for free.
You can set up as many alerts as you want without incurring any fees.